序列最小优化算法(SMO)
来源:http://zh.wikipedia.org/wiki/%E5%BA%8F%E5%88%97%E6%9C%80%E5%B0%8F%E4%BC%98%E5%8C%96%E7%AE%97%E6%B3%95
序列最小优化算法(英语:Sequential minimal optimization, SMO)是一种用于解决支持向量机训练过程中所产生优化问题的算法。SMO由微软研究院的约翰·普莱特(John Platt)发明于1998年[1],目前被广泛使用于SVM的训练过程中,并在通行的SVM库libsvm中得到实现。[2][3]
1998年,SMO算法发表在SVM研究领域内引起了轰动,因为先前可用的SVM训练方法必须使用复杂的方法,并需要昂贵的第三方二次规划工具。而SMO算法较好地避免了这一问题。[4]
目录[隐藏]
|
[编辑]问题定义
SMO算法主要用于解决支持向量机目标函数的最优化问题。考虑数据集![]() 的二分类问题,其中
的二分类问题,其中![]() 是输入向量,
是输入向量,![]() 是向量的类别标签,只允许取两个值。一个软边缘支持向量机的目标函数最优化等价于求解以下二次规划问题的最大值:
是向量的类别标签,只允许取两个值。一个软边缘支持向量机的目标函数最优化等价于求解以下二次规划问题的最大值:
-

-
满足:
-
其中,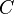 是SVM的参数,而
是SVM的参数,而![]() 是核函数。这两个参数都需要使用者制定。
是核函数。这两个参数都需要使用者制定。
[编辑]算法
SMO是一种解决此类支持向量机优化问题的迭代算法。由于目标函数为凸函数,一般的优化算法都通过梯度方法一次优化一个变量求解二次规划问题的最大值,但是,对于以上问题,由于限制条件![]() 存在,当某个
存在,当某个![]() 从
从![]() 更新到
更新到![]() 时,上述限制条件即被打破。为了克服以上的困难,SMO采用一次更新两个变量的方法。
时,上述限制条件即被打破。为了克服以上的困难,SMO采用一次更新两个变量的方法。
[编辑]数学推导
假设算法在某次更新时更新的变量为![]() 和
和![]() ,则其余变量都可以视为常量。为了描述方便,规定
,则其余变量都可以视为常量。为了描述方便,规定
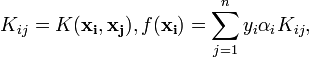
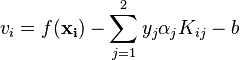
因而,二次规划目标值可以写成
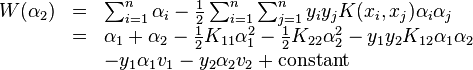
由于限制条件![]() 存在,将
存在,将![]() 看作常数,则有
看作常数,则有![]() 成立(
成立(![]() 为常数)。由于
为常数)。由于![]() ,从而
,从而![]() (
(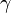 为常数,
为常数,![]() )。取
)。取![]() 为优化变量,则上式又可写成
为优化变量,则上式又可写成
对![]() 求偏导以求得最大值,有
求偏导以求得最大值,有
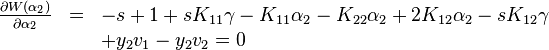
因此,可以得到
规定误差项![]() ,取
,取![]() ,并规定
,并规定![]() ,上述结果可以化简为
,上述结果可以化简为
再考虑限制条件![]() ,
,![]() 的取值只能为直线
的取值只能为直线![]() 落在
落在![]() 矩形中的部分。因此,具体的SMO算法需要检查
矩形中的部分。因此,具体的SMO算法需要检查![]() 的值以确认这个值落在约束区间之内。[1][5]
的值以确认这个值落在约束区间之内。[1][5]
[编辑]算法框架
SMO算法是一个迭代优化算法。在每一个迭代步骤中,算法首先选取两个待更新的向量,此后分别计算它们的误差项,并根据上述结果计算出![]() 和
和![]() 。最后再根据SVM的定义计算出偏移量
。最后再根据SVM的定义计算出偏移量![]() 。对于误差项而言,可以根据
。对于误差项而言,可以根据![]() 、
、![]() 和
和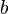 的增量进行调整,而无需每次重新计算。具体的算法如下:
的增量进行调整,而无需每次重新计算。具体的算法如下:
1 随机数初始化向量权重,并计算偏移 2 初始化误差项 3 选取两个向量作为需要调整的点 4 令 5 如果 6 令 7 如果 8 令 9 令 10 利用更新的和修改和的值 11 如果达到终止条件,则停止算法,否则转3
其中,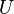 和
和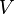 为
为![]() 的上下界。特别地,有
的上下界。特别地,有

这一约束的意义在于使得![]() 和
和![]() 均位于矩形域
均位于矩形域![]() 中。[5]
中。[5]
[编辑]优化向量选择方法
可以采用启发式的方法选择每次迭代中需要优化的向量。第一个向量可以选取不满足支持向量机KKT条件的向量,亦即不满足
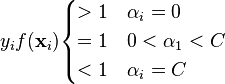
的向量。而第二个向量可以选择使得![]() 最大的向量。[5]
最大的向量。[5]
[编辑]终止条件
SMO算法的终止条件可以为KKT条件对所有向量均满足,或者目标函数![]() 增长率小于某个阈值,即
增长率小于某个阈值,即
-
-
 [5]
[5]
-
[编辑]参考资料
- ^ 1.0 1.1 Platt, John, Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines. 1998
- ^ Chih-Chung Chang and Chih-Jen Lin (2001). LIBSVM: a Library for Support Vector Machines.
- ^ Luca Zanni (2006). Parallel Software for Training Large Scale Support Vector Machines on Multiprocessor Systems.