【论文解读 KDD 2018 | EANN】Event Adversarial Neural Networks for Multi-Modal Fake News Detection

论文题目:EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection
论文来源:KDD 2018
论文链接:https://doi.org/10.1145/3219819.3219903
代码链接:https://github.com/yaqingwang/EANN-KDD18
关键词:事件;多模态(图像+文本);对抗神经网络;假新闻检测
文章目录
- 1 摘要
- 2 模型
- 3 实验
- 4 总结
1 摘要
本文的目的是设计一个有效的模型,去除掉不具有迁移能力的特定事件的特征,并保留事件间的共享特征,以用于假新闻的识别。
本文是第一个对新事件和time-critical事件进行假新闻检测的研究,可基于多模态特征识别出假新闻,并且通过去除掉针对特定事件的特征学习到具有迁移能力的特征。
社交媒体上假新闻检测的挑战之一就是:如何识别和新发生的事件相关的假新闻。
大多数现有的工作倾向于学习特定事件的特征,不能转换到未见过的事件上,因此几乎不能处理这一挑战。
为了解决这一问题,本文提出EANN(Event Adversarial Neural Network)模型,可以得到event-invariant特征,有助于检测和新发生事件相关的假新闻。
模型主要由3部分组成:1)多模态特征抽取器;2)假新闻检测器;3)事件鉴别器。
多模态的特征抽取器用于从帖子中抽取出文本和视觉特征。该抽取器与假新闻检测器合作,学习可区分的表示,用于假新闻检测。事件鉴别器用于去除特定事件的特征,并保留事件间共享的特征。
在Weibo和Twitter收集到的多媒体数据集上进行实验,结果表明本文提出的EANN模型超越了SOTA方法,学习到了可迁移的特征表示。
2 模型
The goal of our model is to learn the transferable and discriminable feature representations for fake news detection.

模型由多模态特征抽取器、假新闻检测器和事件鉴别器三部分组成。
使用Text-CNN生成文本的特征,使用VGG-19和一层全连接层生成视觉特征,然后将两者拼接,得到多模态特征。
得到的多模态特征作为假新闻检测器的输入,预测该帖子的真假。
但是,直接最小化假新闻检测器的损失,仅有助于检测和训练集中所包含的事件相关的假新闻,因为只捕获到了特定事件的知识(例如 关键词)或没收,不具有很好的泛化能力。因此,需要去除掉针对特定事件的特征。我们需要衡量不同事件间特征表示的差异性,并去除掉这些特征以捕获到事件不变的特征表示。
事件鉴别器基于每个帖子的隐层表示,识别出每个帖子的事件标签。
一方面,多模态的特征抽取器试图欺骗事件鉴别器,以最大化鉴别损失(discrimination loss),鉴别损失越大说明不同事件的表示越相似,也就意味着学习到的特征是事件的共性特征。另一方面,事件鉴别器试图发现特征表示中包含的与特定事件相关的信息来识别事件。
3 实验
(1)数据集

1)Twitter Dataset
来自MediaEval Verifying Multimedia Use benchmark 。
包含文本、图像/视频以及社交上下文信息。
Christina Boididou, Katerina Andreadou, Symeon Papadopoulos, Duc-Tien Dang-Nguyen, Giulia Boato, Michael Riegler, Yiannis Kompatsiaris, et al. 2015. Verifying Multimedia Use at MediaEval 2015… In MediaEval.
2)Weibo Dataset
Zhiwei Jin, Juan Cao, Han Guo, Yongdong Zhang, and Jiebo Luo. 2017. Multimodal Fusion with Recurrent Neural Networks for Rumor Detection on Microblogs. In Proceedings of the 2017 ACM on Multimedia Conference. ACM, 795–816.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IdsMjx7u-1594383900759)(C:/Users/byn/AppData/Roaming/Typora/typora-user-images/image-20200709002108097.png)]
(2)实验结果
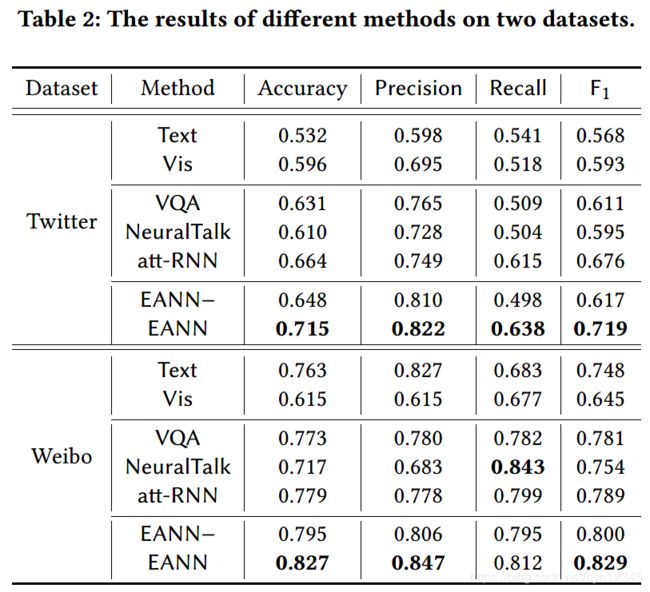
4 总结
本文解决的是多模态假新闻检测任务,提出模型EANN为未出现的事件学习到可迁移的特征,增强模型在新出现事件上的泛化能力。
模型由多模态特征抽取器、事件鉴别器、假新闻检测器三部分组成。多模态特征抽取器和假新闻检测器可学习到有区分性的表示,以用于假新闻检测。并且利用事件鉴别器学习到事件不变的表示,去除针对特定事件的表示。
不足:文本和视觉特征的融合只是简单的拼接。