谣言止于智者:基于深度强化学习的谣言早期检测模型

「论文访谈间」是由 PaperWeekly 和中国中文信息学会社会媒体处理专委会(SMP)联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。


谣言一般是指未经核实的陈述或说明,它往往与某一事件相关,在大众之间广泛传播。而随着社交媒体的发展,谣言可以通过社交媒体以核裂变的方式快速传播,这往往会引发诸多不安定因素,并对经济和社会产生巨大的影响。
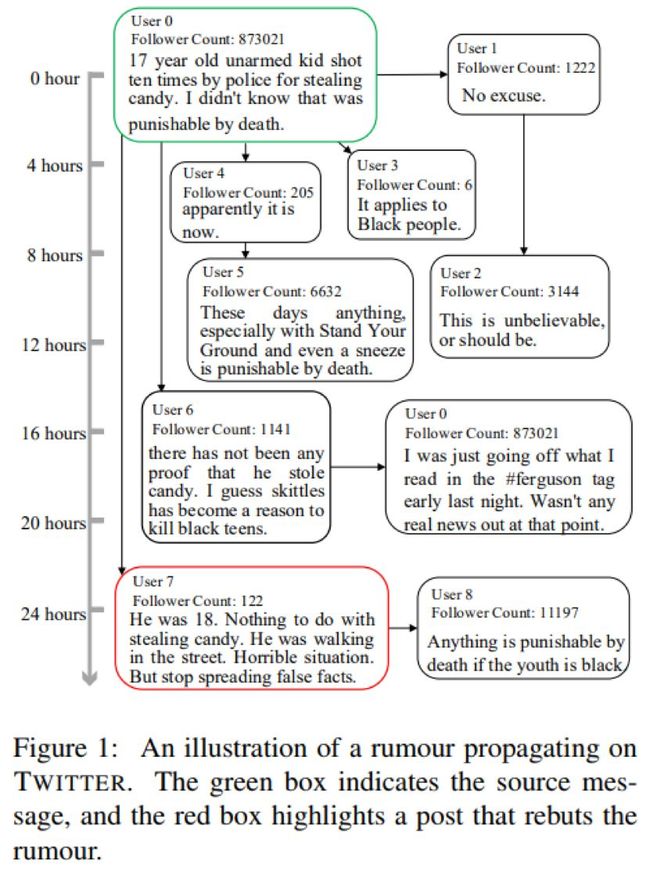
谣言从产生到传播直至造成危害,往往会经历一段时间的演化,在这期间会有大量的相关信息伴随源信息而发布。图 1 描述的是在 Twitter 上传播的一则谣言——“一个 17 岁黑人小孩因偷窃糖果被警察击毙”。
我们以源消息的发布作为时间原点,不难发现该信息一经发布便在 Twitter 上引发轩然大波,但遗憾的是,直至发布 24 小时后才有消息证实该信息为谣言。然而,此时该谣言已经在社交媒体上广泛传播,并造成不可挽回的影响。因此,本文旨在研究社交媒体中谣言的早期检测。
谣言的早期检测通常是指谣言刚产生的几小时内,即谣言在这期间被发现,其可控性强,产生的危害性弱。现有研究成果大多集中在如何更准确的进行谣言检测,其往往忽视了谣言检测的时效性需求。少数涉及早期谣言检测的,也只是简单比较不同静态检测点上的准确率,即仅用预先定义好的固定检测点前的数据进行检测,并比较准确率。
实际上,静态检测点并不是明智之举,不同的谣言在社交媒体上的爆点时间并不相同,有些谣言会因为时间的设置过早而无法保证检测准确率,有些谣言则会因为设置过晚而无法保证其检测时效性。因此,谣言的判别应依照不同的事件,动态地设置检测点,从而实现谣言的早期发现。
为了解决这一问题,本文提出了一个基于强化学习的谣言早期检测模型,该模型将社交媒体中发布的帖子按其发布时间以信息流的形式进行输入。每当一个新帖子到来,模型都会对其进行判别,并将判别结果输入到强化学习模块,强化学习模块利用奖励机制对当前检测结果进行判断,并根据准确率来进行策略选择。如果准确率满足要求,则输出判别结果,否则继续监听。通过这种方式,不仅实现了谣言的早期发现,同时还能保证检测的准确率。
模型
不失一般性,我们用E表示一个待检测的事件,它往往有一系列相关的帖子构成![]() ,其中
,其中![]() 表示源信息,
表示源信息,![]() 表示截至当前时间点最新发布的帖子。谣言早期判别模型的设计目标就是为了尽可能早的判别 E 是否是一个谣言。
表示截至当前时间点最新发布的帖子。谣言早期判别模型的设计目标就是为了尽可能早的判别 E 是否是一个谣言。
谣言早期判别模型(Early Rumor Detection,ERD)主要包括两个部分:检测点模块(Checkpoint Module,CM)和谣言检测模块(Rumor Detection Module,RDM)。
其中谣言检测模块用于判别某一事件是否为谣言,而检测点模块用于判断是否触发 RDM。这里 CM 扮演了一个重要的角色,它用来决定何时对相关事件进行判别。该模型的创新之处在于利用强化学习方法来发现最优的检测点,同时采用交替学习的方式优化两个模块,可以在保证准确率的前提下,尽早识别谣言。模型框架如下图所示。
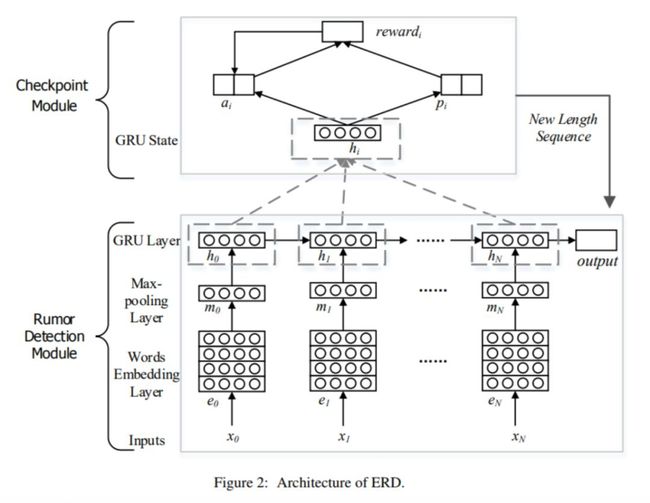
谣言检测模块
谣言检测模块主要用于检测某事件是否为谣言。具体地,首先将待检测的帖子序列进行分词并以词向量形式进行表示,同时使用全连接神经网络和 maxpooling 运算提取每个帖子的特征。需要注意的是由于通常帖子量很大,连续的帖子会按照一定数量以帖子集合形式输入。
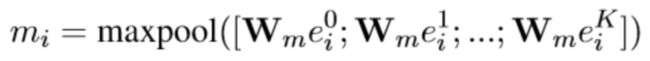
其次,采用 GRU 循环神经网络来学习帖子集合的序列特征。
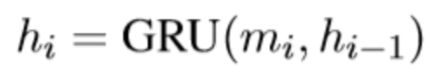
最后,采用 softmax 输出谣言检测的结果。
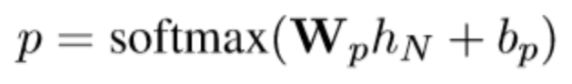
检测点模块
与现有设置静态检查点的方法不同,CM 通过学习触发 RDM 所需的帖子数量来确定检测点,进而对相关事件进行谣言识别。为此,我们利用深层强化学习来确定最佳检查点。我们以 RDM 的准确率作为奖励,同时将不触发 RDM 的次数作为惩罚。通过这种方式,CM 可以学习到如何在准确率和时效性之间进行权衡。
具体的,在强化学习模块中,CM 将 GRU 中产生的隐藏状态作为输入,使用双层前馈网络计算 action-value 函数。为此,我们采用 Q-learning 方法来进行计算,action-value 的最优函数 Q* 可以定义为在状态 s 下采取行动 a 以获得最大的奖励值 r。
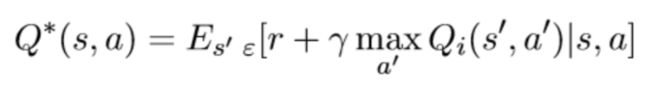
其中 r 是奖励值,γ 是 discount rate,选择所有 action 序列中的最优值 a’,使之满足期望最大化。
在这个过程中,CM 会根据当前状态,计算出不同 action 的奖励估计值![]() 。
。
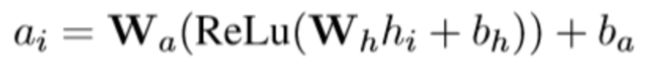
这里 action 集合主要包括继续输入待检测帖子和停止谣言检测,并以谣言检测模块给出的结果正确与否来计算实际奖励值。

这里 M 是一个递增的数,在每次判断正确后,M 值都会累积递增。-P 是一个固定的惩罚系数,-ε 是一个固定的微小惩罚系数,来促使检测点模块确定较早的检测点。
联合训练
在模型训练过程中,我们会一并训练 RDM 以及 CM 模块,其训练过程类似于生成对抗网络。具体的,我们会先预训练谣言检测模块(RDM),使其达到一定的准确率,进而来评估检测点模块。
随后,交替训练两个 CM 与 RDM 模型:检测点模块计算出来的新的检测点会反馈给下一个谣言检测模块,即检测点模块以谣言检测模块评估的结果学习到好的检测点,谣言检测模块适应新的检测点以给出正确结果。
实验结果
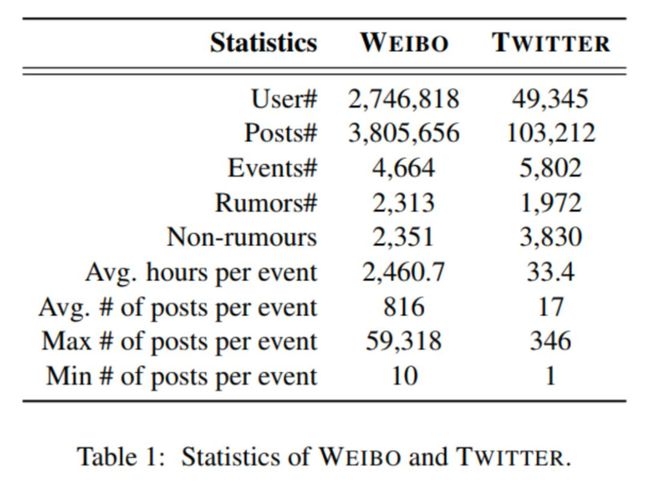
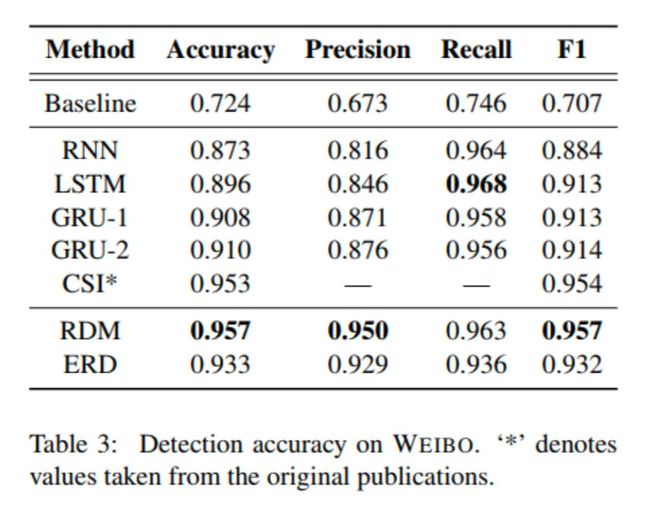
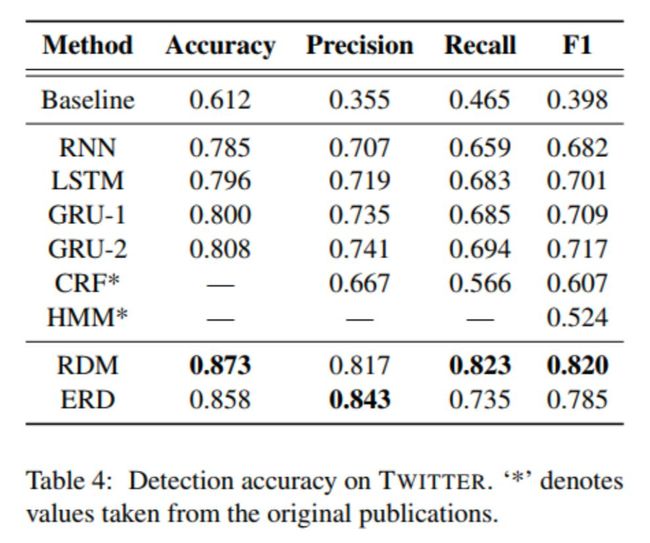
本文在两个公开数据集上进行实验来验证模型的准确性和时效性,分别是基于微博和 Twitter 的谣言数据集,两个数据集的相关统计指标请见表 1。
实验中,我们首先对模型的准确性进行比较。与现有模型相比,我们的模型 RDM(仅谣言检测模块采用完整的信息)的准确率在两个数据集上都更具优势,如表 3、表 4 所示。此外,与现有最好的模型相比,ERD(结合了检测点模块并使用动态检测点)也表现相当。
我们进一步对模型进行时效性验证。由于当前谣言检测方法中很少涉及时效性的实验,我们主要和 GRU-2 模型进行比较。在 GRU-2 中,其采用了人为设置的静态时间点方式,即事件发生后的第十二小时为检测节点。
在实验中,我们按照 6 小时作为一个时间间隔对其进行划分,将全部消息按照时间划分为 8 个间隔。图 6 展示的是不同时间间隔的谣言识别百分比,图 7 显示的是在各个时间间隔中的谣言识别准确率。


图 6 和图 7 中的虚线分别表示 GRU-2 在 12 小时静态检测点上的判别结果。ERD 模型可以在 6 小时内识别出大部分事件,其远远早于 12 小时(实验中微博检测点平均为 7.5 小时,Twitter 平均为 3.4 小时)。不仅如此,图 7 显示相较于 GRU-2,ERD 模型在各个时间间隔的准确率更高。
此外,为了验证 CM 的有效性,我们将 ERD 和 RDM 做了比较,结果如图 8 所示。其中 RDM 采用了设定静态检测点的方法,可见在微博数据集上 ERD 仅 7.5 小时的结果就与 RDM 在 24 小时的准确率相当,而在 Twitter 上 ERD 更是能够提前近 20 小时达到与 RDM 相当的准确率。


表 3 是本文对 PARL 模型做的消融实验的结果,可以观察到:每个组件层都对提升分数预测的精度起到了正面的影响。

为了进一步对方法进行定性分析,我们在表 5 中展示了一个来自微博谣言事件的例子。谣言始于 2012 年 8 月 18 日发布的消息,声称大闸蟹含有有害激素和毒素。在发布后的 12 小时内,230 万用户通过转发、评论或质疑原文的方式参与了消息的散播。此谣言迅速蔓延,并对中国水产养殖业造成重大经济损失。在 24 小时后,谣言被正式驳回,但从表 5 中我们可以看到,ERD 在 34 分钟内就检测到谣言。
总结
本文提出了一种基于深度强化学习的早期谣言检测模型 ERD。与之前设置静态检测点的方法不同,ERD 可以通过强化学习的方法来动态设定检测点,以最少的信息来进行判别,进而实现谣言的早期发现。
我们分别在 Twitter 以及微博数据集中进行实验验证,ERD 可以分别用 3.4 小时以及 7.5 小时进行谣言的判别,与之前 12 小时相比大大提前了。同时 ERD 可以取得 93.3% 以及 85.8% 的准确率,与当前最优模型水平相当。
以下是相关数据集链接:
微博数据集:
http://alt.qcri.org/~wgao/data/rumdect.zip
Twitter数据集:
https://figshare.com/articles/PHEME_dataset_of_rumours_and_non-rumours/4010619
关于作者

周凯敏,毕业于国际关系学院,师从李斌阳副教授。主要研究文本不确定性识别,社交媒体中的谣言检测和用户意图识别等。原就职于义语智能科技(上海)有限公司,本文即主要于公司实习期间,在学校和公司大力支持下所完成的。

舒畅,义语智能CTO & CEO。英国诺丁汉大学人工智能博士,英国布里斯托大学机器学习硕士,获北京航空航天大学、英国赫尔大学双学士,师从国际机器学习泰斗级教授Nello Cristianini。曾在日本国立情报研究所(NII)担任访问研究员,广州市高端人才,现担任中科院计算所上海分所&义语智能人工智能自然语言处理联合实验室主任,中国中文信息学会青年工作委员会委员之一,社交媒体处理委员之一。在COLING,NAACL等顶尖国际会议和杂志期刊上发表过多篇论文,在国内拥有多项人工智能相关专利。

李斌阳,国际关系学院副教授,硕导。研究兴趣包括自然语言处理、情感分析和社会计算,累计发表论文50余篇。担任中国中文信息学会社交媒体专委会副秘书长、青年工作委员会委员,人工智能学会青工委委员。长期担任相关领域国际权威学术期刊审稿人和重要学术会议程序委员会委员(TPC)。曾获教育部科技进步二等奖(第三完成人),香港科技资讯优秀奖。

刘杰汉,博士,DeepBrain义语智能首席科学家。主要研究方向为NLP和主题模型,英国伦敦国王学院博士后,澳大利亚墨尔本大学机器学习博士及学士,现任澳大利亚墨尔本大学人工智能导师,曾在IBM澳大利亚研究院担任高级研究员,在日本国立情报研究所(NII)担任访问研究员。在ACL,COLING,NAACL,EMNLP等顶尖自然语言处理国际会议和杂志期刊上共发表论文近40篇,在国内及国外拥有多项人工智能相关专利。
主办单位



点击以下标题查看更多往期内容:
目标检测小tricks之样本不均衡处理
图神经网络综述:模型与应用
推荐系统阅读清单:最近我们在读哪些论文?
小样本学习(Few-shot Learning)综述
万字综述之生成对抗网络(GAN)
基于深度学习的推荐模型—PARL
基于双层注意力机制的异质图深度神经网络
基于小样本学习的意图识别冷启动
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
?
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐