统计学习方法笔记---SMO算法
前言
首先我们需要知道的是SMO算法适用于求解凸二次规划问题的最优解,在详细讲解SMO之前,我们需要了解坐标上升法,该算法每一轮迭代得到多元函数中的一个参数,通过多次迭代直到收敛得到所有参数解。如 Θ = [ θ 1 , θ 2 , θ 3 ] \Theta = [\theta_1, \theta_2, \theta_3] Θ=[θ1,θ2,θ3],每一轮只计算 θ i \theta_i θi,经过三次迭代得到 Θ \Theta Θ。
SMO的特点
SMO与坐标上升法的思想大致相同,只不过每一轮迭代同时更新两个参数。因为如果优化目标函数的约束条件对参数有限制,若只更新一个参数,可能会导致约束条件失效。
如SVM中有约束条件: ∑ i = 1 N α i y i = 0 \sum_{i=1}^N \alpha_iy_i=0 ∑i=1Nαiyi=0
SMO算法的工作原理
每次循环中选择两个alpha进行优化处理,一旦找到一对合适的alpha,那么就增大其中一个同时减小另一个。这里所谓的“合适”就是指两个alpha必须要符合一定的条件,条件一直就是这两个alpha必须要在间隔边界之外,而其第二个条件则是这两个alpha还没有进行过区间化处理或者不在边界上。
区间化处理: ?
SVM中的SMO算法
SVM的对偶问题:
m a x ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j k ( x i , x j ) y i y j s . t ∑ i = 1 n α i y i = 0 0 ≤ α i ≤ C max \quad \sum_{i=1}^n\alpha_i -\frac 1 2 \sum_{i=1}^n\sum_{j=1}^n \alpha_i \alpha_jk_(x_i,x_j)y_iy_j \\ s.t \quad \sum_{i=1}^n \alpha_iy_i = 0 \\ \\ 0 \le \alpha_i \le C maxi=1∑nαi−21i=1∑nj=1∑nαiαjk(xi,xj)yiyjs.ti=1∑nαiyi=00≤αi≤C
定义:
k i j = K ( x i , x j ) f ( x i ) = ∑ j = 1 n y j α j k i j + b v i = f ( x i ) − ∑ j = 1 2 y i α j k i j − b k_{ij} = K(x_i, x_j) \\ f(x_i) = \sum_{j=1}^ny_j\alpha_jk_{ij}+b \\ v_i = f(x_i) - \sum_{j=1}^2y_i\alpha_jk_{ij}-b kij=K(xi,xj)f(xi)=j=1∑nyjαjkij+bvi=f(xi)−j=1∑2yiαjkij−b
于是SMO的最优化问题的子问题为 W ( α 1 , α 2 ) W(\alpha_1, \alpha_2) W(α1,α2):
W ( α 1 , α 2 ) = ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n y i y j K ( x i , x j ) α i α j = α 1 + α 2 − ( 1 2 k 11 α 1 2 + 1 2 k 22 α 2 2 + y 1 y 2 k 12 α 1 α 2 + 1 2 ∑ i = 1 j ∑ j = 3 n y i y j K ( x i , x j ) α i α j + 1 2 ∑ i = 3 n ∑ j = 1 n y i y j K ( x i , x j ) α i α j ) = α 1 + α 2 − ( 1 2 k 11 α 1 2 + 1 2 k 22 α 2 2 + y 1 y 2 k 12 α 1 α 2 + ∑ i = 1 n y i α i v i ) = α 1 + α 2 − ( 1 2 k 11 α 1 2 + 1 2 k 22 α 2 2 + y 1 y 2 k 12 α 1 α 2 + y 1 α 1 v 1 + y 2 α 2 v 2 ) W(\alpha_1, \alpha_2)= \sum_{i=1}^n \alpha_i - \frac 1 2 \sum_{i=1}^n \sum_{j=1}^n y_i y_j K(x_i,x_j)\alpha_i\alpha_j\\ = \alpha_1 + \alpha_2-( \frac 1 2 k_{11}\alpha_1^2 + \frac 1 2 k_{22}\alpha_2^2 + y_1y_2k_{12}\alpha_1\alpha_2 + \frac 1 2 \sum_{i=1}^j \sum_{j=3}^n y_i y_j K(x_i,x_j)\alpha_i\alpha_j + \frac 1 2 \sum_{i=3}^n \sum_{j=1}^n y_i y_j K(x_i,x_j)\alpha_i\alpha_j)\\ = \alpha_1 + \alpha_2- (\frac 1 2 k_{11}\alpha_1^2 + \frac 1 2 k_{22}\alpha_2^2 + y_1y_2k_{12}\alpha_1\alpha_2 + \sum_{i=1}^ny_i\alpha_iv_i )\\ = \alpha_1 + \alpha_2-(\frac 1 2 k_{11}\alpha_1^2 + \frac 1 2 k_{22}\alpha_2^2 + y_1y_2k_{12}\alpha_1\alpha_2+y_1\alpha_1v1 + y_2\alpha_2v_2) W(α1,α2)=i=1∑nαi−21i=1∑nj=1∑nyiyjK(xi,xj)αiαj=α1+α2−(21k11α12+21k22α22+y1y2k12α1α2+21i=1∑jj=3∑nyiyjK(xi,xj)αiαj+21i=3∑nj=1∑nyiyjK(xi,xj)αiαj)=α1+α2−(21k11α12+21k22α22+y1y2k12α1α2+i=1∑nyiαivi)=α1+α2−(21k11α12+21k22α22+y1y2k12α1α2+y1α1v1+y2α2v2)
这里需要注意到两点
- K 12 = K 21 K_{12} = K_{21} K12=K21,因为核函数在希尔伯特空间中,希尔伯特空间中的向量具有正交性1的特点,即 < f , g > = < g , f >
- α 1 , α 2 \alpha_1,\alpha_2 α1,α2为变量, α 3 , . . . , α n \alpha_3 , ..., \alpha_n α3,...,αn为常数,在上式我们省略了常数项
由于
α i y 1 + α 2 y 2 = k y i ∈ { − 1 , 1 } α 1 = γ − s α 2 ( γ = y 1 k , s = y 1 y 2 ) \alpha_iy_1 + \alpha_2y_2 = k \quad y_i \in \{ -1, 1\} \\ \alpha_1 =\gamma - s\alpha_2 \\ (\gamma = y_1k, s = y_1y_2) αiy1+α2y2=kyi∈{−1,1}α1=γ−sα2(γ=y1k,s=y1y2)
令 α 2 \alpha_2 α2为优化变量,则
W ( α 2 ) = − ( γ − s α 2 + α 2 − 1 2 k 11 ( γ − s α 2 ) 2 − 1 2 k 22 α 2 2 ) ∂ W ( α 2 ) ∂ α 2 = − s + 1 + s k 11 − k 22 α 2 − s k 12 ( γ − 2 s α 2 ) + y 2 v 1 − y 2 v 1 = − s + 1 + s k 11 γ − k 22 α 2 − k 22 α 2 − s k 12 γ + 2 s k 12 α 2 + y 2 v 1 − y 2 v 2 令 ∂ W ( α 2 ) ∂ α 2 = 0 α 2 = − s + 1 + s k 11 γ − s k 12 γ + y 2 v 1 − y 2 v 2 k 11 + k 22 + 2 k 12 W(\alpha_2) = -( \gamma - s \alpha_2 + \alpha_2 - \frac 1 2 k_{11}(\gamma - s\alpha_2)^2 - \frac 1 2 k_{22} \alpha_2^2) \\ \frac {\partial W(\alpha_2)} {\partial \alpha_2} = -s + 1 + sk_{11} - k_{22}\alpha_2 - sk_{12}(\gamma - 2s\alpha_2) + y_2v_1 - y_2v_1 \\ =-s + 1 + sk_{11}\gamma - k_{22}\alpha_2 - k_{22}\alpha_2 -sk_{12}\gamma + 2sk_{12}\alpha_2 + y_2v_1 -y_2v_2 \\ \quad \\ 令\frac {\partial W(\alpha_2)} {\partial \alpha_2} = 0 \\ \quad \\ \alpha_2 =\frac { -s + 1 + sk_{11}\gamma - sk_{12}\gamma + y_2v_1 - y_2v_2} {k_{11} + k_{22} + 2k_{12}} W(α2)=−(γ−sα2+α2−21k11(γ−sα2)2−21k22α22)∂α2∂W(α2)=−s+1+sk11−k22α2−sk12(γ−2sα2)+y2v1−y2v1=−s+1+sk11γ−k22α2−k22α2−sk12γ+2sk12α2+y2v1−y2v2令∂α2∂W(α2)=0α2=k11+k22+2k12−s+1+sk11γ−sk12γ+y2v1−y2v2
定义误差项 E i = f ( x i ) − y i E_i = f(x_i) - y_i Ei=f(xi)−yi, 取 γ = α 1 o l d + s α 2 o l d \gamma = \alpha_1^{old} + s\alpha_2^{old} γ=α1old+sα2old, K = k 11 + k 22 − 2 k 12 K = k_{11} + k_{22} -2k_{12} K=k11+k22−2k12
已知:
v 1 = f ( x 1 ) − y 1 α 1 k 11 − y 2 α 2 k 12 − b v 2 = f ( x 2 ) − y 1 α 1 k 21 − y 2 α 2 k 22 − b v_1 = f(x_1) - y_1\alpha_1k_{11} - y_2\alpha_2k_{12} -b\\ v_2 = f(x_2) - y_1\alpha_1k_{21} - y_2\alpha_2k_{22}-b v1=f(x1)−y1α1k11−y2α2k12−bv2=f(x2)−y1α1k21−y2α2k22−b
则
α 2 n e w = − s + 1 + s γ k 11 − s γ k 12 + y 2 f ( x 1 ) − s α 1 o l d k 11 − α 2 o l d k 12 − y 2 f ( x 2 ) + s α 1 o l d k 21 + α 2 o l d k 22 k 11 + k 22 + 2 k 12 \alpha_2^{new} = \frac {-s + 1 + s\gamma k_{11} - s\gamma k_{12} + y_2f(x_1)-s\alpha_1^{old}k_{11} - \alpha_2^{old}k_{12} - y_2f(x_2) + s\alpha_1^{old}k_{21} + \alpha_2^{old}k_{22}} {k_{11} + k_{22} + 2k_{12}} \\ α2new=k11+k22+2k12−s+1+sγk11−sγk12+y2f(x1)−sα1oldk11−α2oldk12−y2f(x2)+sα1oldk21+α2oldk22
将 α 1 = γ − s α 2 \alpha_1 =\gamma - s\alpha_2 α1=γ−sα2 代入:
α 2 n e w = y 2 [ f ( x 1 ) − y 1 ) − ( f ( x 2 ) − y 2 ) ] + s γ k 11 − s ( γ − s α 2 o l d ) k 11 + s ( γ − s α 2 o l d ) k 21 − s γ k 12 − α 2 o l d k 12 + α 2 o l d k 22 k 11 + k 22 + 2 k 12 = y 2 [ f ( x 1 ) − y 1 ) − ( f ( x 2 ) − y 2 ) ] + α 2 o l d k 11 + α 2 o l d k 22 − 2 k 12 α 2 o l d k 11 + k 22 + 2 k 12 = α 2 o l d + y 2 ( E 1 − E 2 ) K \alpha_2^{new}=\frac {y_2[f(x_1) - y_1) - (f(x_2) - y_2)] + s\gamma k_{11} - s(\gamma - s \alpha_2^{old})k_{11} + s(\gamma - s\alpha_2^{old})k_{21} - s\gamma k_{12} - \alpha_2^{old}k_{12} + \alpha_2^{old} k_{22}} {k_{11} + k_{22} + 2k_{12}}\\ = \frac {y_2[f(x_1) - y_1) - (f(x_2) - y_2)] + \alpha_2^{old}k_{11} + \alpha_2^{old}k_{22}-2k_{12}\alpha_2^{old}} {k_{11} + k_{22} + 2k_{12}} \\ \quad \\ = \alpha_2^{old} + \frac {y_2(E_1 - E_2)} {K} α2new=k11+k22+2k12y2[f(x1)−y1)−(f(x2)−y2)]+sγk11−s(γ−sα2old)k11+s(γ−sα2old)k21−sγk12−α2oldk12+α2oldk22=k11+k22+2k12y2[f(x1)−y1)−(f(x2)−y2)]+α2oldk11+α2oldk22−2k12α2old=α2old+Ky2(E1−E2)
对变量进行剪辑
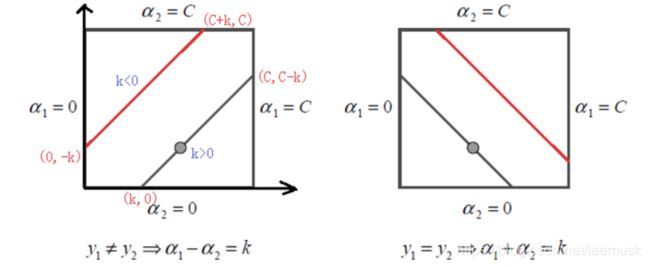
已知 0 ≤ α i ≤ C 0 \le \alpha_i \le C 0≤αi≤C (这里的C为SVM的目标优化函数的惩罚参数。所以需要对变量进行剪辑,因为只有两个变量 α 1 , α 2 \alpha_1 , \alpha_2 α1,α2,所有约束可以用二维空间中的图形表示。
有两种情况:
y 1 y 2 ≠ 1 ⇒ α 1 − α 2 = k y 1 y 2 = 1 ⇒ α 1 + α 2 = k y_1y_2 \ne 1 \Rightarrow \alpha_1 - \alpha_2 = k \\ y_1y_2 = 1 \Rightarrow \alpha_1+ \alpha_2 = k y1y2=1⇒α1−α2=ky1y2=1⇒α1+α2=k
-
y 1 = y 2 , α 1 − α 2 = k y_1 = y_2 , \alpha_1 - \alpha_2 = k y1=y2,α1−α2=k:
k > 0时, α 2 \alpha_2 α2 的范围是 (0, C-k)
k < 0时, α 2 \alpha_2 α2 的范围是 (-k, C)
=> α 2 n e w \alpha_2^{new} α2new 的最小值L, 最大值H为:
L = m a x ( 0 , α 2 o l d − α 1 o l d ) H = m i n ( C , C + α 2 o l d − α 1 o l d ) L = max(0, \alpha_2^{old} - \alpha_1^{old}) \\ H = min(C, C+\alpha_2^{old} - \alpha_1^{old}) L=max(0,α2old−α1old)H=min(C,C+α2old−α1old) -
y 1 ≠ y 2 , α 1 + α 2 = k y_1 \ne y_2, \alpha_1 + \alpha_2 = k y1=y2,α1+α2=k:
k < C时, α 2 \alpha_2 α2 的范围是 (0, k)
k > C时, α 2 \alpha_2 α2 的范围是 (k-C, C )
=> α 2 n e w \alpha_2^{new} α2new 的最小值L, 最大值H为:
L = m a x ( 0 , α 2 o l d + α 1 o l d − C ) H = m i n ( C , α 2 o l d + α 1 o l d ) L = max(0, \alpha_2^{old} + \alpha_1^{old} -C) \\ H = min(C, \alpha_2^{old} + \alpha_1^{old}) L=max(0,α2old+α1old−C)H=min(C,α2old+α1old)
现在,最优化问题沿着约束方向未经剪辑时的解为:
α 2 n e w , u n c = α 2 o l d + y 2 ( E 1 − E 2 ) K \alpha_2^{new, unc} = \alpha_2^{old} + \frac {y_2(E_1 - E_2)} {K} α2new,unc=α2old+Ky2(E1−E2)
经剪辑后 α 2 \alpha_2 α2的解是:
α 2 n e w = { H , α 2 n e w , u n c > H α 2 n e w , u n c , L ≤ α 2 n e w , u n c ≤ H L , α 2 n e w , u n c < L \alpha_2^{new} = \begin{cases} H, \quad \alpha_2^{new, unc} > H \\ \alpha_2^{new, unc}, L \le \alpha_2^{new, unc} \le H \\ L, \quad \alpha_2^{new, unc} < L \end{cases} α2new=⎩⎪⎨⎪⎧H,α2new,unc>Hα2new,unc,L≤α2new,unc≤HL,α2new,unc<L
由 α 2 n e w \alpha_2^{new} α2new求得 α 1 n e w \alpha_1^{new} α1new:
α 1 n e w = α 1 o l d + y 1 y 2 α 2 n e w \alpha_1^{new} = \alpha_1^{old} + y_1y_2\alpha_2^{new} α1new=α1old+y1y2α2new
最后,我们得到了最优化问题的解 ( α 1 n e w , α 2 n e w ) (\alpha_1^{new},\alpha_2^{new}) (α1new,α2new)
选择变量
SMO算法在每个问题中选择两个变量优化,其中至少一个变量是违法KKT条件的。
选择第一个变量
选择第一个变量的过程为外层循环。找到训练样本中选择违反KKT条件最严重的样本点,并将其对应的变量作为第一个变量。
检验训练样本是否满足KKT条件:
SMO算法在每个问题中选择两个变量优化,其中至少一个变量是违法KKT条件的。
KKT条件的推导过程:
根据软间隔支持向量机的KKT条件:
{ μ i ξ i = 0 C − α i − μ i = 0 y i f ( x i ) − 1 + ξ i ≥ 0 α i ( y i f ( x i ) − 1 + ξ i ) = 0 \begin{cases} \mu_i\xi_i = 0\\ C- \alpha_i - \mu_i = 0 \\ y_if(x_i) - 1 + \xi_i \ge 0 \\ \alpha_i(y_if(x_i) - 1 + \xi_i ) = 0 \end{cases} ⎩⎪⎪⎪⎨⎪⎪⎪⎧μiξi=0C−αi−μi=0yif(xi)−1+ξi≥0αi(yif(xi)−1+ξi)=0
进行如下推导:
{ α i = 0 ⇔ μ i = C ⇔ ξ i = 0 ⇔ y i f ( x i ) ≥ 1 0 < α i < C ⇔ μ i > 0 ⇔ ξ i = 0 ⇔ y i f ( x i ) = 1 α i = C ⇔ μ i = 0 ⇔ ξ i ≥ 0 ⇔ y i f ( x i ) ≤ 1 \begin{cases} \alpha_i = 0 \Leftrightarrow \mu_i = C \Leftrightarrow \xi_i = 0 \Leftrightarrow y_if(x_i) \ge 1 \\ 0 < \alpha_i < C \Leftrightarrow \mu_i>0 \Leftrightarrow \xi_i = 0 \Leftrightarrow y_if(x_i) = 1 \\ \alpha_i = C \Leftrightarrow \mu_i = 0 \Leftrightarrow \xi_i \ge 0 \Leftrightarrow y_if(x_i) \le 1 \end{cases} ⎩⎪⎨⎪⎧αi=0⇔μi=C⇔ξi=0⇔yif(xi)≥10<αi<C⇔μi>0⇔ξi=0⇔yif(xi)=1αi=C⇔μi=0⇔ξi≥0⇔yif(xi)≤1
得到检验训练样本的KKT条件:
{ α i = 0 ⇔ y i f ( x i ) ≥ 1 0 < α i < C ⇔ y i f ( x i ) = 1 α i = C ⇔ y i f ( x i ) ≤ 1 \begin{cases} \alpha_i = 0 \Leftrightarrow y_if(x_i) \ge 1 \\ 0 < \alpha_i < C \Leftrightarrow y_if(x_i) = 1 \\ \alpha_i = C \Leftrightarrow y_if(x_i) \le 1 \end{cases} ⎩⎪⎨⎪⎧αi=0⇔yif(xi)≥10<αi<C⇔yif(xi)=1αi=C⇔yif(xi)≤1
选择第二个变量
找到第二个变量的过程为内层循环,第二个变量选择的标准是希望使 α 2 \alpha_2 α2有足够大的变化。而 ∣ E 1 − E 2 ∣ |E_1 - E_2| ∣E1−E2∣依赖于 ∣ E 1 − E 2 ∣ |E_1 - E_2| ∣E1−E2∣, 且 E 1 E_1 E1是已知的。所以需要找到使 ∣ E 1 − E 2 ∣ |E_1 - E_2| ∣E1−E2∣最大的变量 α 2 \alpha_2 α2。如果内层循环通过以上方法选择的 α 2 \alpha_2 α2不能是目标函数有足够的下降,那么采用以下启发式继续选择 α 2 \alpha_2 α2,遍历在间隔边界上的支持向量点,依次将其对应的变量作为 α 2 \alpha_2 α2实适用,直到目标函数有足够的下降。若找不到合格的 α 2 \alpha_2 α2,那么遍历训练数据集;若仍找不到合适的 α 2 \alpha_2 α2,则放弃第一个 α 1 \alpha_1 α1,在通过外层循环寻求另外的 α 1 \alpha_1 α1。
更新阈值b 和差值E
当我们更新了一对 α i , α j \alpha_i, \alpha_j αi,αj 之后都需要重新计算阈值 b ,因为 b 关系到我们 f ( x ) f(x) f(x) 的计算,关系到下次优化的时候误差 E i E_i Ei的计算。
为了使得被优化的样本都满足KKT条件,
当 α 1 n e w \alpha_1^{new} α1new 不在边界,即 0 < α 1 n e w < C 0 < \alpha_1^{new} < C 0<α1new<C , 根据KKT条件可知相应的数据点为支持向量,满足 y 1 ( w T + b ) = 1 y_1(w^T + b) = 1 y1(wT+b)=1 , 两边同时乘上 y 1 y_1 y1 得到 ∑ i = 1 n α i y i k ( x 1 , x i ) = y i \sum_{i=1}^n \alpha_iy_i k(x1,x_i) = y_i ∑i=1nαiyik(x1,xi)=yi , 进而得到 b 1 n e w b_1^{new} b1new 的值:
b 1 n e w = y 1 − ∑ j = 3 n α i y i k i 1 − α 1 n e w y 1 k 11 − α 2 n e w y 2 k 21 b_1^{new} = y_1 - \sum_{j=3}^n\alpha_i y_i k_{i1} - \alpha_1^{new}y_1 k_{11} - \alpha_2^{new}y_2 k_{21} b1new=y1−j=3∑nαiyiki1−α1newy1k11−α2newy2k21
上式的前两项可以写成:
y 1 − ∑ j = 3 n α i y i k i 1 = − E 1 + α 1 o l d y 1 k 11 + α 2 o l d y 2 k 21 + b o l d y_1 - \sum_{j=3}^n\alpha_i y_i k_{i1} = -E_1 +\alpha_1^{old}y_1k_{11} + \alpha_2^{old}y_2k_{21} + b^{old} y1−j=3∑nαiyiki1=−E1+α1oldy1k11+α2oldy2k21+bold
可得:
b 1 n e w = − E 1 + α 1 o l d y 1 k 11 + α 2 o l d y 2 k 21 + b o l d − α 1 n e w y 1 k 11 − α 2 n e w y 2 k 21 = − E 1 − y 1 k 11 ( α 1 n e w − α 1 o l d ) − y 2 k 21 ( α 2 n e w − α 2 o l d ) + b o l d b_1^{new} = -E_1 +\alpha_1^{old}y_1k_{11} + \alpha_2^{old}y_2k_{21} + b^{old} - \alpha_1^{new}y_1 k_{11} - \alpha_2^{new}y_2 k_{21} \\ = -E_1 -y_1k_{11}(\alpha_1^{new}-\alpha_1^{old}) - y_2k_{21}(\alpha_2^{new}-\alpha_2^{old}) + b^{old} b1new=−E1+α1oldy1k11+α2oldy2k21+bold−α1newy1k11−α2newy2k21=−E1−y1k11(α1new−α1old)−y2k21(α2new−α2old)+bold
当 0 < α 2 n e w < C 0 < \alpha_2^{new} < C 0<α2new<C, 可以得到 b 2 n e w b_2^{new} b2new的表达式(推导同上):
b 2 n e w = − E 2 − y 1 k 12 ( α 1 n e w − α 1 o l d ) − y 2 k 22 ( α 2 n e w − α 2 o l d ) + b o l d b_2^{new} = -E_2 -y_1k_{12}(\alpha_1^{new}-\alpha_1^{old}) - y_2k_{22}(\alpha_2^{new}-\alpha_2^{old}) + b^{old} b2new=−E2−y1k12(α1new−α1old)−y2k22(α2new−α2old)+bold
当 α 1 n e w , α 2 n e w \alpha_1^{new}, \alpha_2^{new} α1new,α2new同时满足 0 < α i n e w < C 0 < \alpha_i^{new} < C 0<αinew<C,即 b 1 b_1 b1和 b 2 b_2 b2 都有效的时候,他们是相等的, b 1 n e w = b 2 n e w = b n e w b_1^{new} = b_2^{new} = b^{new} b1new=b2new=bnew。
当两个乘子 α 1 n e w , α 2 n e w \alpha_1^{new}, \alpha_2^{new} α1new,α2new 是0或者C, 即都在边界上,且 L ≠ H L \ne H L=H 时, b 1 n e w , b 2 n e w b_1^{new},b_2^{new} b1new,b2new之间的值就是满足KKT条件的阈值。SMO选择他们的中点作为新的阈值:
b n e w = b 1 n e w + b 2 n e w 2 b^{new} = \frac {b_1^{new} + b_2^{new}} 2 bnew=2b1new+b2new
接下来更新 E i n e w E_i^{new} Einew:
E i n e w = ∑ S y j α j k ( x i , x j ) + b n e w − y i E_i^{new} = \sum_S y_j \alpha_j k(x_i, x_j) +b^{new} -y_i Einew=S∑yjαjk(xi,xj)+bnew−yi
其中,S是所有支持向量 x j x_j xj的集合。支持向量为支撑超平面上,支撑超平面与分离超平面之间以及误分类侧的向量。
具体实现代码详见:https://blog.csdn.net/leemusk/article/details/105596434