人体检测HOG特征 Finding People in Images and Videos
1. Introduction
Any given class has ahuge intra-class variation.
任何类的类内距离都可能很大。
Challenges:
Firstly, the imageinformation process suppresses 3-D depth information and creates dependencieson viewpoint such that even a small change in the object's position ororientation w.r.t. the camera center may change its appearance considerably. Arelated issue is the large variation in scales under which an object can beviewed. An object detector must handle the issues of viewpoint and scalechanges and provide invariance to them.
第一,3D深度信息丢失使图像依赖于视角。物体和相机之间的相对位置和方向如果发生微小变化,可能引起图像的巨大变化。一个相关的问题是:多大尺寸的物体才会被系统检测到。一个特征检测算法必须能够处理特征尺度和视角的变化。
Secondly, mostnatural object classes have large within-class variations. For example, forhumans both appearance and pose change considerably between images anddifferences in clothing create further changes. A robust detector must try toachieve independence of these variations.
第二,大部分自然物体都有很大的类内变化。
Thirdly, backgroundclutter is common and varies from mage to image. Examples are images taken innatural settings, outdoor scenes in cities and indoor environments. Thedetector must be capable of distinguishing object class from complex backgroundregions.
第三,每一幅图像的背景都会有差异。
Fourthly, object colorand general illumination varies considerably.
第四,特征颜色和光照会发生变化。
Finally, partialocclusions create further difficulties because only part of the object isvisible for processing.
最后,遮挡问题。
2. Stateof the Art
2.1 Image Features
2.1.1 Sparse LocalRepresentations
Sparserepresentations are based on local descriptors of relevant local image regions.The regions can be selected using either key point detectors or partsdetectors.
Point Detectors 点特征
The hypothesis isthat key point detectors select stable and more reliable image regions, whichare especially informative about local image content. The overall detectorperformance thus depends on the reliability, accuracy and repeatabilitywith which these key points can be found for the given object class and theinformativeness of the points chosen.
One advantage ofsparse key point based approaches is the compactness of the representation:there are many fewer key point descriptors than image pixels, so thelatter stages of the classification process are speeded up. However note thatmost key point detectors are designed to fire repeatedly on particular objectsand may have limitations when generalizing to object classes or categories,i.e. they may not be repeatable for general object classes.
3.Overview of Detection Methodology and Results
3.1 OverallArchitecture
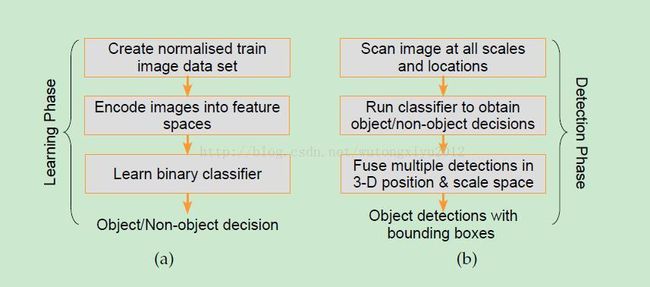
The first stage of learning is the creationof the training data. The positive training examples are fixed resolution imagewindows containing the centered object, and the negative examples are similarwindows that are usually randomly subsampled and cropped from set of images notcontaining any instances of the object.
第一步是创建训练数据。正类样本是以物体为中心的固定尺寸图像,负类样本是不包含物体的图像。
Three properties oflinear SVM make it valuable for comparative testing work: it converges reliablyand repeatedly during training; it handles large data sets gracefully; and ithas good robustness towards different choices of feature sets andparameters.
SVM的优点
As the linear SVMworks directly in the input feature space, it ensures that the feature set isas linearly separable as possible, so improvements in performance imply animproved encoding.
SVM直接在原特征上进行分类,提高识别率意味着提高了特征的可分性。
3.2 Overview ofFeature Sets
3.2.1 Static HOGDescriptors
The hypothesis isthat local object appearance and shape can often be characterized rather wellby the distribution of local intensity gradient or edge directions, evenwithout precise knowledge of the corresponding gradient or edge positions.
本方法基于一个假设:在一副图像中,局部目标的表象和形状(appearance and shape)能够被梯度或边缘的方向分布很好地描述。(本质:梯度的统计信息,而梯度主要存在于边缘的地方)(http://blog.csdn.net/zouxy09/article/details/7929348)。
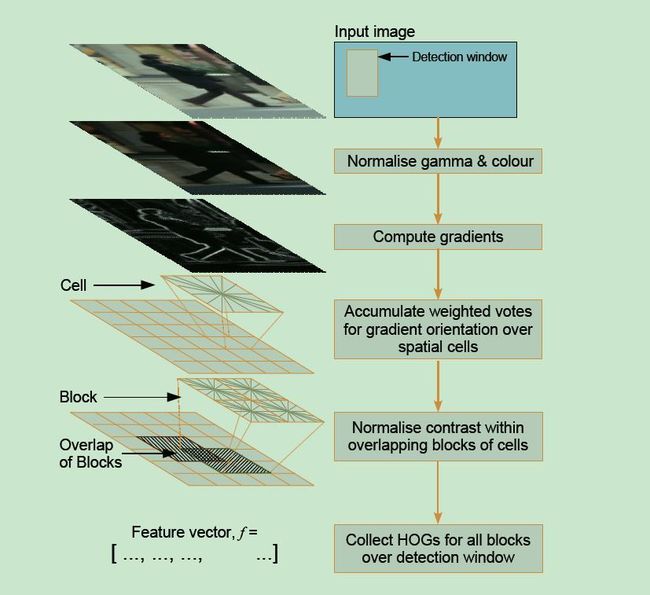
The first stageapplies an optional global image normalisation equalization that is designed toreduce the influence of illumination effects. Gamma compression
采用Gamma校正法对输入图像进行颜色空间的标准化(归一化);目的是调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰;
The second stagecomputes first order image gradients. These capture contour, silhouette andsome texture information, while providing further resistance to illumination variations.
计算图像每个像素的梯度(包括大小和方向);主要是为了捕获轮廓信息,同时进一步弱化光照的干扰。
The third stage aimsto produce an encoding that is sensitive to local image content while remainingresistant to small changes in pose or appearance.
给出与局部图像内容相关的编码,该编码在姿态和表象发生微小变化的情况下保持不变。
The fourth stagecomputes normalisation, which takes local groups of cells and contrastnormalises their overall responses before passing to next stage. Normalisationintroduces better invariance to illumination, shadowing, and edge contrast.
正则化。对每一个cell根据它所在的block进行正则化。这有助于克服光照,阴影,和边缘的影响。一个cell通常属于多个block,要根据它所属的每一个block进行正则化。因此,一个cell会以不同的特征出现多次。
The final stepcollects the HOG descriptors from all blocks of a dense overlapping grid ofblocks covering the detection window into a combined feature vector for use inthe window classifier.
把每一个block的特征串起来,组成一个长的特征向量。
4.Histogram of Oriented Gradients Based Encoding of Images
4.1.1 Static HOG Descriptors
All of the variantsshare the same basic processing chain described in section 3.2.1, i.e. they allare computed on a dense grid of uniformly spaced cells, they capture localshape information by encoding image gradients orientations in histograms, theyachieve a small amount of spatial invariance by locally pooling thesehistograms over spatial image regions, and they employ overlapping localcontrast normalisation for improved illumination invariance.
所有的变种都具有一些共性:在有规则的密集窗口上计算,对直方图的梯度方向进行编码以表达局部形状信息,把多个位置的直方图集中起来以克服位置的变化,使用有重叠的局部正则化以改善光照的影响。
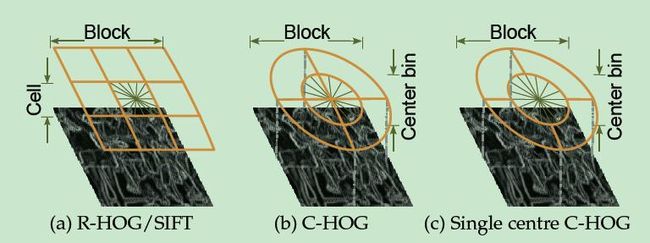
Rectangular HOG(R-HOG)
R-HOGs are similar toSIFT descriptors bust are used quite differently. SIFTs are computed at asparse set of scale-invariant key points, rotated to align their dominantorientations and used individually, whereas R-HOGs are computed in dense gridsat a single scale without dominant orientation alignment. The grid position ofthe block implicitly encodes spatial position relative to the detection windowin the final code vector. SIFTs are optimized for sparse wide baseline matching,R-HOGs for dense robust coding of spatial form.
R-HOG与SIFT相似,但适用于不同的应用。SIFT是稀疏的,需要进行旋转,单独使用;R-HOG是密集的,无须旋转,同其它的特征一起使用。
4.1.2 Circular HOG(C-HOG)
In circularHOG(C-HOG) block descriptors, the cells are defined into grids of log-polarshape. The input image is covered by a dense rectangular grid of centers. Ateach center, we divide the local image patch into a number of angular andradial bins. The angular bins are uniformly distributed over the circle. Theradial bins are computed over log scales, resulting in increasing bin size withincreasing distance from the center.
Cell是在log-polar坐标系中划分的。对于每个中心,我们在角度和半径方向分别划分小块。因为角度是均匀划分的,离中心越远的块包含的像素越多。
The motivation forthe log-polar grid is that it allows fine coding of nearby structure to becombined with coarser coding of wider context.
可以把附近结构的精细化编码同远处背景的粗略编码结合起来。
The C-HOG layout hasfour spatial parameters: the number of angular and radial bins; the radius ofthe central bin in pixels; and the expansion factor for subsequent radii.
C-HOG有四个参数:角度和径度划分的区间数,中心块的半径,非中心的半径差。
4.1.3 Bar HOG
Bar HOG descriptors are computed similarly to thegradient HOG ones, but use oriented second derivative (bar) filters instead offirst derivatives.
Bar HOG的计算和HOG的计算过程相似,区别在于前者使用二阶导数而后者使用一阶导数。
4.1.4Centre-Surround HOG
4.2 other descriptors
GeneralizedHaar Wavelets; shape contexts; PCA-SIFT (待看)
4.3 Implementationand Performance Study
4.3.1 Gamma/Color Normalisation
When available, color information alwayshelps, e.g. for the person detector RGB and LAB color space give comparableresults, while restricting to grayscale reduces performances.
颜色信息是有用的。
Our experience isthat square root gamma compression gives better performance for man-made objectclasses such as bicycles, motorbikes, cars, buses, and also people (whosepatterned clothing results in sudden contrast changes). For animals involvinglot of within-class color variation such as cats, dogs, and horses,unnormalised RGB turns out to be better, while for cows and sheep square rootcompression continues to yield better performance.
Gamma compression: 人造的各类物体,包括人
Unnormalised RGB: 动物
Root compression: 牛羊等
4.3.2 Gradient Computation
We computed image gradients using optionalGaussian smoothing followed by one of several discrete derivative masks andtested how performance varies. For color images (RGB or LAB space), we computedseparate gradients for each color channel and took the one with the largestnorm as the pixel’s gradient vector.
计算图像梯度可以有选择的进行高斯平滑,再用模板计算梯度。对于颜色图像,对每一个颜色通道计算梯度并取最大的梯度向量。
Overall detectorperformance is sensitive to the way in which gradients are computed and thesimplest scheme of centered 1-D [-1 0 1] masks at delta=0 works best. The useof any form of smoothing or of larger masks of any type seems to decrease theperformance. The most likely reason for this is the fine details are important:images are essentially edge based and smoothing decreases the edge contrast andhence the signal. A useful corollary is that the optimal image gradients can becomputed very quickly and simply.
计算梯度的时候,最简单的方法是最有效的。梯度算子是中心化的1-D算子 [-1 0 1]并且delta取0.使用更大的mask或者进行平滑,会降低算法的性能。这可能是因为图像的细节被抵消的原因。
4.3.3 Spatial /Orientation Binning
Each pixel contributes a weighted vote fororientation based on the orientation of the gradient element centered on it.
基于以它为中心计算得到的梯度,每一个像素都以一定的权重对最后的方向产生影响。权重取梯度的幅值,得到最优结果。
Fine orientationcoding turns out to be essential for good performance for all object classes,whereas spatial binning can be rather coarse.
把方向分得更细会明显提高算法的性能,但空间分得更细对性能的提高作用不大。把0-180度平均分成9份,得到最优结果。
4.3.4 BlockNormalisation Schemes and Descriptor Overlap
Anumber of different normalisation schemes were evaluated. Most of them arebased on grouping cells into larger spatial blocks and contrast normalizingeach block separately. In fact, the blocks are typically overlapped so thateach scalar cell response contributes several components to the finaldescriptor vector, each normalized with respect to a different block. This mayseem redundant but good normalisation is critical and including overlap significantlyimproves the performance.
正则化的方法有几种。他们大都把cell放在一个更大的block里,然后对每一个block分别正则化。实际上,这些block是互相重叠的,它们之间有交集。所以每个cell里的响应在最终的描述子里面会出现不只一次。这种冗余性被证明是可以改善性能的。

|
输入:当前尺度的图像和图像大小 输出:任意指定位置的特征编码 初始化: a. 对输入图像的每一个颜色通道进行Gamma正则化 b. 对每一个颜色通道,分别沿着x和y方向利用模板[-1 0 1]进行卷积,得到梯度值。每个像素的orientation 和magnitude等于所有通道计算得到的最大量。 c.如果使用R2-HOG,利用宽度为的高斯核对图像进行平滑,得到导数,利用公式计算主方向和公式计算振幅magnitude。 |
| 描述子的计算:对每一个用户指定的窗口进行计算 a、把图像窗口均匀分成由点构成的风格。 b、如果使用R-HOG (1) 把以当前点为中的的窗口区域划分成多个cell; (2) 对block内的图像梯度应该sigma= 的高斯窗口; (3) 创建一个的空间和方向直方图; (4) 对于block内的每一个像素,使用三线性插值来投票决定直方图的梯度振幅gradient magnitude。 c、如果使用R2-HOG,对图像的一阶梯度和二阶梯度运用与R-HOG相同的步骤,得到两个3D的直方图。 d、如果使用C-HOG, (1) 把以当前点为中心的图像区域分成log-polar圆形区域;通过创建角度和径度bins来把block分成多个cell。 (2) 为每一个cell创建一个bin的方向直方图; (3) 对block内的每一个像素,在log-polar-orientation空间里使用三线性插值来投票决定cell的直方图。 |
| 结束步骤: (a) 对每一个block独立的运用L2-Hys或L1-Sqrt进行正则化;如果使用R2-HOG,对每一个3D直方图进行独立的正则化; (b) 把所有的block的HOGs组成一个高维描述子。 |

| 输入: 正则化和确定正类样本的分辨率(宽度和长度);负类样本。 输出:训练得到的两类分类器,分类对像是的图像窗口。 |
| 创建负类样本,任何一个负类样本都是从负类图像里随机选取的一个窗口。 初步学习阶段(First phase learning): (a) 为每一个正类图像计算描述子; (b) 训练得到一个SVM分类器。 |
| 生成难分的负类样本(hard negative examples):对负类图像进行多尺度的扫描 (a) 初始尺度定义为,计算结束尺度,其中和分别是图像的宽度和高度; (b) 计算扫描尺度数,是固定的步长 (c) 对每一个尺度 (1) 使用二插值的方法对图像进行缩放; (2) 使用编码算法并且按步长扫描图像 (3) 把所有结果是的样本(难分类的样本hard examples)放入列表。 |
| 第二阶段学习 (a) 估计RAM中可以存储的难分样本个数 (b) 如果难分类样本个数大于上述个数,对难分类样本进行采样; (c) 利用正类样本,初始的负类样本,和难分类样本学习得到最终的SVM分类器。 |
Overall we studiedthe influence of various descriptor parameters and concluded that fine-scalegradient, fine orientation binning, relatively coarse spatial binning, andhigh-quality local contrast normalisation in overlapping descriptor blocks areall important for good performance.
总体来说,精细的梯度,精细的方向bin,粗略的空间bin,有效的局部对比度正则化都能提高最终的性能。
5 Multi-ScaleObject Localization
5.1Binary Classifier for object Localization
Scanning detection window based object detection and localizationrequires multiple overlapping detections to be merged. Our solution is based onthe following two hypotheses:
1. If the detector is robust, it shouldgive a strong positive (though not maximum) response even if the detectionwindow is slightly off-center or off-scale on the object.
2. A reliable detector will not firewith same frequency and confidence for non-object image windows.
检测到的窗口需要融合在一起。我们的方法基于以下两个假设:
1. 如果检测算法是鲁棒的,那么既使检测窗口稍微偏离物体中心或与物体的大小稍微不同,响应也应该足够大;
2. 对非物体的响应(频率和可信度frequency and confidence)应该是各不相同的。
An ideal fusion method wouldincorporate the following characteristics:
1. The higher the peak detection score,the higher the probability for the image region to be a true positive.
2. The more overlapping detectionsthere are in the neighborhood of an image region, the higher the probabilityfor the image region to be a true positive.
3. nearby overlapping detections shouldbe fused together, but overlaps occurring at very different scales or positive positionsshould not be fused.
一个理想的融合算法应该具有如下特征:
1.响应越大,被检测窗口是正样本的概率越大;
2. 出现的较大响应越密集,被检测窗口是正样本的概率越大;
3. 重叠的响应应该融合在一起,但如果重叠的响应在尺度和位置上具有较大差异就不应该融合。
Werepresent detections using kernel density estimation (KDE) in 3-D position andscale space. The bandwidth of thesmoothing kernel defines the local neighborhood. The kernel width should bechosen to meet several criteria. It should not be less than the spatial and scalestride at which window classifiers are run, nor less than the natural spatialand scale width of the intrinsic classifier response (the former should be obviouslybe chosen to be less than the latter). Also it should not be wider than theobject itself so that nearby objects are not confused.
我们使用三维位置尺度空间里的kernel densityestimation (KDE)来表示检测结果。平滑核的宽度定义了近邻的概念。核的宽度应该满足几个条件:不小于空域和尺度空间里的步长;不小于空域和尺度空间里分类器响应的自然长度。
后面的部分大部分都是公式推理。确定KDE的参数,和求解KDE的极值。
6 OrientedHistograms of Flow and Appearance for Detecting People in Videos
6.1Formation of Motion Compensation
The goal of this chapter is to exploitmotion cues to improve our person detector’s performance for films and videos.Detecting people in video sequences introduces new problems. Besides thechallenges already mentioned for static images such as variations in pose, appearance,clothing, illumination and background clutter, the detector has to handle themotion of the subject, the camera and the independent objects in thebackground. The main challenge is thus to find a set of features that characterizehuman motion well, while remaining resistant to camera and background motion.
本章的目的是探索运动线索来改善人体检测在电影和视频中的性能。在视频中检测人体会有一些新问题。除了图像中姿态,表像,服饰,光照,背景的影响外,还要考虑物体,相机,和其它物体的运动问题。主要的挑战是在降低相机和背景运动影响的前提下,找到一种表现人体运动的特征。
其它参考资料
http://blog.csdn.net/zouxy09/article/details/7929348
http://stackoverflow.com/questions/18474897/fastest-hog-feature-extraction-implementation
以下转自: http://www.zhizhihu.com/html/y2010/1690.html
HOG descriptors 是应用在计算机视觉和图像处理领域,用于目标检测的特征描述器。这项技术是用来计算局部图像梯度的方向信息的统计值。这种方法跟边缘方向直方图(edge orientation histograms)、尺度不变特征变换(scale-invariant feature transform descriptors) 以及形状上下文方法( shape contexts)有很多相似之处,但与它们的不同点是:HOG描述器是在一个网格密集的大小统一的细胞单元(dense grid of uniformly spaced cells)上计算,而且为了提高性能,还采用了重叠的局部对比度归一化(overlapping local contrast normalization)技术。
这篇文章的作者Navneet Dalal和BillTriggs是法国国家计算机技术和控制研究所French National Institute for Research inComputer Science and Control (INRIA)的研究员。他们在这篇文章中首次提出了HOG方法。这篇文章被发表在2005年的CVPR上。他们主要是将这种方法应用在静态图像中的行人 检测上,但在后来,他们也将其应用在电影和视频中的行人检测,以及静态图像中的车辆和常见动物的检测。
HOG描述器最重要的思想是:在一副 图像中,局部目标的表象和形状(appearance and shape)能够被梯度或边缘的方向密度分布很好地描述。具体的实现方法是:首先将图像分成小的连通区域,我们把它叫细胞单元。然后采集细胞单元中各像素 点的梯度的或边缘的方向直方图。最后把这些直方图组合起来就可以构成特征描述器。为了提高性能,我们还可以把这些局部直方图在图像的更大的范围内(我们把 它叫区间或block)进行对比度归一化(contrast-normalized),所采用的方法是:先计算各直方图在这个区间(block)中的密 度,然后根据这个密度对区间中的各个细胞单元做归一化。通过这个归一化后,能对光照变化和阴影获得更好的效果。
与其他的特征描述方法相 比,HOG描述器后很多优点。首先,由于HOG方法是在图像的局部细胞单元上操作,所以它对图像几何的(geometric)和光学的 (photometric)形变都能保持很好的不变性,这两种形变只会出现在更大的空间领域上。其次,作者通过实验发现,在粗的空域抽样(coarse spatial sampling)、精细的方向抽样(fine orientation sampling)以及较强的局部光学归一化(strong local photometric normalization)等条件下,只要行人大体上能够保持直立的姿势,就容许行人有一些细微的肢体动作,这些细微的动作可以被忽略而不影响检测效 果。综上所述,HOG方法是特别适合于做图像中的行人检测的。
上图是作者做的行人检测试验,其中(a)表示所有训练图像集 的平均梯度(average gradient across their training images);(b)和(c)分别表示:图像中每一个区间(block)上的最大最大正、负SVM权值;(d)表示一副测试图像;(e)计算完R- HOG后的测试图像;(f)和(g)分别表示被正、负SVM权值加权后的R-HOG图像。
算法的实现:
色彩和伽马归一化 (color and gamma normalization)
作者分别在灰度空间、RGB色彩空间和LAB色彩空间上对图像进行色彩和 伽马归一化,但实验结果显示,这个归一化的预处理工作对最后的结果没有影响,原因可能是:在后续步骤中也有归一化的过程,那些过程可以取代这个预处理的归 一化。所以,在实际应用中,这一步可以省略。
梯度的计算(Gradient computation)
最常用的方法是:简单地使用一个一维的离散微分模板(1-D centered point discrete derivative mask)在一个方向上或者同时在水平和垂直两个方向上对图像进行处理,更确切地说,这个方法需要使用下面的滤波器核滤除图像中的色彩或变化剧烈的数据 (color or intensity data)
作者也尝试了其他一些更复杂的模板,如3×3 Sobel 模板,或对角线模板(diagonalmasks),但是在这个行人检测的实验中,这些复杂模板的表现都较差,所以作者的结论是:模板越简单,效果反而越好。作者也尝试了在使用微分模板前加入 一个高斯平滑滤波,但是这个高斯平滑滤波的加入使得检测效果更差,原因是:许多有用的图像信息是来自变化剧烈的边缘,而在计算梯度之前加入高斯滤波会把这 些边缘滤除掉。
构建方向的直方图(creating the orientation histograms)
第三步就是为图像的每个细胞单元构建梯度方向直方图。细胞单元中的每一个像素点都为某个基于方向的直方图通道(orientation-based histogram channel)投票。投票是采取加权投票(weighted voting)的方式,即每一票都是带权值的,这个权值是根据该像素点的梯度幅度计算出来。可以采用幅值本身或者它的函数来表示这个权值,实际测试表明: 使用幅值来表示权值能获得最佳的效果,当然,也可以选择幅值的函数来表示,比如幅值的平方根(square root)、幅值的平方(squareof the gradient magnitude)、幅值的截断形式(clipped version of the magnitude)等。细胞单元可以是矩形的(rectangular),也可以是星形的(radial)。直方图通道是平均分布在0-1800(无 向)或0-3600(有向)范围内。作者发现,采用无向的梯度和9个直方图通道,能在行人检测试验中取得最佳的效果。
把细胞单元组 合成大的区间(grouping the cells together into larger blocks)
由于局部光照的变化(variations of illumination)以及前景-背景对比度(foreground-background contrast)的变化,使得梯度强度(gradient strengths)的变化范围非常大。这就需要对梯度强度做归一化,作者采取的办法是:把各个细胞单元组合成大的、空间上连通的区间(blocks)。 这样以来,HOG描述器就变成了由各区间所有细胞单元的直方图成分所组成的一个向量。这些区间是互有重叠的,这就意味着:每一个细胞单元的输出都多次作用 于最终的描述器。区间有两个主要的几何形状——矩形区间(R-HOG)和环形区间(C-HOG)。R-HOG区间大体上是一些方形的格子,它可以有三个参 数来表征:每个区间中细胞单元的数目、每个细胞单元中像素点的数目、每个细胞的直方图通道数目。作者通过实验表明,行人检测的最佳参数设置是:3×3细胞 /区间、6×6像素/细胞、9个直方图通道。作者还发现,在对直方图做处理之前,给每个区间(block)加一个高斯空域窗口(Gaussian spatial window)是非常必要的,因为这样可以降低边缘的周围像素点(pixels around the edge)的权重。
R- HOG跟SIFT描述器看起来很相似,但他们的不同之处是:R-HOG是在单一尺度下、密集的网格内、没有对方向排序的情况下被计算出来(are computed in dense grids at some single scale withoutorientation alignment);而SIFT描述器是在多尺度下、稀疏的图像关键点上、对方向排序的情况下被计算出来(are computed at sparse scale-invariant keyimage points and are rotated to align orientation)。补充一点,R-HOG是各区间被组合起来用于对空域信息进行编码(are used in conjunction to encode spatialform information),而SIFT的各描述器是单独使用的(are used singly)。
C- HOG区间(blocks)有两种不同的形式,它们的区别在于:一个的中心细胞是完整的,一个的中心细胞是被分割的。如右图所示:
作者发现 C-HOG的这两种形式都能取得相同的效果。C-HOG区间(blocks)可以用四个参数来表征:角度盒子的个数(number of angular bins)、半径盒子个数(number of radial bins)、中心盒子的半径(radiusof the center bin)、半径的伸展因子(expansion factor for the radius)。通过实验,对于行人检测,最佳的参数设置为:4个角度盒子、2个半径盒子、中心盒子半径为4个像素、伸展因子为2。前面提到过,对于R-HOG,中间加一个高斯空域窗口是非常有必要的,但对于C-HOG,这显得没有必要。C-HOG看起来很像基于形状上下文(Shape Contexts)的方法,但不同之处是:C-HOG的区间中包含的细胞单元有多个方向通道(orientation channels),而基于形状上下文的方法仅仅只用到了一个单一的边缘存在数(edge presence count)。
区间归一化 (Block normalization)
作者采用了四中不同的方法对区间进行归一化,并对结果进行了比较。引入v表示一个还没有被归一 化的向量,它包含了给定区间(block)的所有直方图信息。| | vk | |表示v的k阶范数,这里的k去1、2。用e表示一个很小的常数。这时,归一化因子可以表示如下:
L2-norm:
L1-norm:
L1-sqrt:
还 有第四种归一化方式:L2-Hys,它可以通过先进行L2-norm,对结果进行截短(clipping),然后再重新归一化得到。作者发现:采用L2- Hys L2-norm 和 L1-sqrt方式所取得的效果是一样的,L1-norm稍微表现出一点点不可靠性。但是对于没有被归一化的数据来说,这四种方法都表现出来显着的改进。
SVM 分类器(SVMclassifier)
最后一步就是把提取的HOG特征输入到SVM分类器中,寻找一个最优超平面作为决策函数。作者采用 的方法是:使用免费的SVMLight软件包加上HOG分类器来寻找测试图像中的行人。