姿态估计1-03:HR-Net(人体姿态估算)-白话给你讲论文-翻译无死角(1)
以下链接是个人关于HR-Net(人体姿态估算) 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。
姿态估计1-00:HR-Net(人体姿态估算)-目录-史上最新无死角讲解
本论文名为:
Deep High-Resolution Representation Learning for Human Pose Estimation (CVPR 2019)
话不多说,本人直接开始翻译了
Abstract
在这篇论文中,我们介绍了一种以学习高分辨率特征的人体姿态估算的方法,现在存在的大多数方法,都是提取图象的低分辨率特征,然后恢复成高分辨率特征进行预测。我们提出的方法,在整个网络中,主要以高分辨率为主。
网络的设计,首先是一个高分辨率的子网络分子作为第一个stage,后面的stage会添加新的网络分支,同时新分支网络提取特征的分辨率是逐渐减少的,并且每个子网络之间是相互平行的。我们会重复执行 multi-scale fusions(多尺寸融合),让多个不同分辨率的平行网络分支进行信息的交换,这样让输出高分辨率特征包含更多的信息。因此提取出来的关键点热图,在空间上的分布会更加的准确。
我们在两个基线数据上测试了我们的方法,分别为COCO keypoint detection dataset 以及MPII Human Pose dataset,另外我们还在PoseTrack dataset(跟踪数据集)做了测试,展现出了优越的结果。
1. Introduction
2D 人体姿态估算,是计算机视觉中一个基本的问题,其目的是去定位人体标注的关键点(如鼻子,眼睛,耳朵等)。其应用是十分广泛的,比如人类行为识别,动画模拟等。这篇论文主要主要介绍的是单人姿态估算,这是其他相关问题的基础,如多人姿态估算,视频姿态估算,以及轨迹追踪等。
 Figure 1:上图为HRNet的结构图,他是由多个平行,分辨率逐渐降低的子网络构成,平行的子网路通过multi-scale fusion进行信息交流。水平方向代表网络深度,垂直方向表示网络特征图的分辨率。
Figure 1:上图为HRNet的结构图,他是由多个平行,分辨率逐渐降低的子网络构成,平行的子网路通过multi-scale fusion进行信息交流。水平方向代表网络深度,垂直方向表示网络特征图的分辨率。
最近的姿态估算研究,在深度学习上取得了较好的性能。大多数方法都是通过神经网络,进行一系列的卷积组合,提取从搞分辨率到低分辨率的特征,然后又通过反卷积或者线性插值等方式增大特征图分辨率。
我们提出了一种比较新异的结构,叫做 HighResolution Net (HRNet),其主要的特点是,在整个处理的过程中,都是以高分辨率为主的。首先开始的第一个stage是一个高分辨率的,然后在接下来的stage逐渐添加低分辨率的网络分支,并且使用通过重复使用 multi-scale fusions ,然后平行的网络连接起来,进行信息交流。 我们使用这种网络结构去估算关键点。该网络的结构,如Figure 1所示。
相对于现在存在的一些姿态估算的网络结构,我们提出的方法有两个好处:
1.该网络分辨率的降低,是使用哦平行的方式,而不是一连串的去降低特征分辨率,因此其能一直保持高分辨率特征,而不需要一个分辨率由低到高的处理过程。因此预测出来的关键点热图,在空间上的分布会更加的精准。
2.现在大多数特征融合的方式,是让深层特征图和浅层特征图进行融合,相反,我们使用相同深度和相似级别的低分辨率图像,通过重复的多尺度融合来提高高分辨率图像。很显然,结果是高分辨率的表示对于位姿估计也很丰富。因此,我们预测的热图可能更准确
我们在COCO keypoint detection dataset 以及 MPII Human Pose dataset 上进行了实验,证明了我们提出方法的优越性,同时在PoseTrack dataset 进行了姿态追踪的演示。
2. Related Work
传统的单人位姿估计方法大多采用概率图形模型或图形结构模型,最近通过深度学习,自动提取特征方式,相对于传统的算法,提升是比较明显的。现在深度学习提出的解决方式主要分为两类,分别为关键点位置回归,以及估算关键点热图。
大多数网络都包含了一个主干网络,类似于分类网络一样,其降低了分辨率。以及另外一个主干网络,其产生与其输入具有相同分辨率的特征图。然后利用该特征去回归关键点或者估算热图。其主要是采用了分辨率 high-to-low 以及 low-to-high 的结构。可能增加多尺度融合和中间(深层)监督
High-to-low and low-to-high
这个 high-to-low 的处理过程,主要是获得低分辨率高语义的特征,low-to-high 的处理过程,其主要是生成高分辨率的特征图。为了提高性能,这两个过程可能会重复几次。比较由代表的设计有以下几种:
1.对称的高到低和低到高过程,如Hourglass 把 low-to-high 与 high-to-low 的结构设计成镜像模式。
2.重量级 high-to-low 和 轻量级 low-to-high。其 high-to-low 的结构设计,主要是基于分类网络的主干网络,如 ResNet。low-to-high 的设计主要通过简单的双线性上采样或者转置卷积。
3.与反卷积结合。如ResNet或VGGNet的后两个阶段采用了扩张卷积来消除空间分辨率的损失。这是随后一个轻量级 low-to-high 过程,以进一步提高分辨率。避免频繁使用反卷积昂贵的计算成本。
Multi-scale fusion.
直接的方法是将多分辨率图像分别输入多个网络,并聚合输出一个特征图,通过跳过连接将 high-to-low 流程中的低级特征,通过 low-to-high 流程得到高分辨率的高级特征图。在级联金字塔网络中,globalnet将高high-to-low 过程中的低到高层次特征,逐步组合为低到高过程,再由refinenet将卷积处理的低到高层次特征组合。我们的方法是重复多尺度融合,部分是受深度融合及其扩展的启发(该出翻译比较难,有兴趣的朋友可以多琢磨一下)
Intermediate supervision
中间监督或深度监督,早期发展为图像分类,帮助深度网络训练,提高热图估计质量。hourglass 方式和卷积方法处理中间热图作为输入,中间热图作为剩余子网的输入或输入的一部分。
Our approach
我们的网络由 high-to-low 相互平行的子网络构成,其主要是使用高分辨率的分支网络进行姿态(heatmap)估算。它通过反复融合high-to-low 子网来产生可靠的高分辨率特征。该方法和现在存在的大多数方法(需要一个 low-to-high 上采样处理方式,聚合低级以及高高级特征)不一样,同时我们的方法,不需要 intermediate heatmap supervision,在关键点检测精度和计算复杂度和参数效率方面具有优势。
3. Approach
人类姿态估算,关键点检测,其目的是为了输入从一张 W × H W \times H W×H 图片 I, 然后定位其中人类的关键点,如鼻子眼睛嘴巴等。目前好的办法是把关键点的预测问题,转化为 K K K个大小为 W ′ × H ′ W' \times \ H' W′× H′的 heatmaps= { H 1 , H 2 , H 3 } \{H_1,H_2,H_3\} {H1,H2,H3}进行计算。每个热图 H k H_k Hk都表示第k个关键点的位置置信度。
我们也采用这种被广泛使用的方法,去预测人体的关键点,首先使用2个strided的卷积,减少输入图像的分辨率,获得初步特征图,然后把该特征图作为一个主体网络的输入,该主体网络的输出和输入的分辨率一样,其会其估算关键点的heatmaps 。我们将重点介绍这个主体的设计,并介绍图1中所示的高分辨率网络(HRNet)
Sequential multi-resolution subnetworks
有的位姿估计网络是通过串联高分辨率子网来建立的,每个子网形成一个stage,由一系列卷积组成,并且在相邻的子网之间有一个下样本层来将分辨率减半。设 N s r N_{sr} Nsr为某网络在 s stage 处的子网络,r 表示分辨率标号(其该分辨率计算方式为 1 2 r − 1 \frac {1}{2^{r-1}} 2r−11)。如下面表示的是 S = 4 S=4 S=4个 stages 的网络结构:
N 11 → N 22 → N 33 → N 44 N_{11} \rightarrow N_{22}\rightarrow N_{33} \rightarrow N_{44} N11→N22→N33→N44
Parallel multi-resolution subnetworks.
首先我们在第一个 stage 开始了一个高分辨率的网络分支,然后逐步增加高分辨率到低分辨率的子网路,形成一个新的 stages,并将多分辨率子网并行连接。因此,后一阶段并行子网的分辨率由前一阶段的分辨率和一个更低的分辨率组成,一个包含4个并行子网络的网络结构示例如下:
N 11 → N 21 → N 31 → N 41 ↘ N 22 → N 32 → N 42 ↘ N 33 → N 43 ↘ N 44 N_{11} \rightarrow N_{21}\rightarrow N_{31} \rightarrow N_{41} \\ \quad \quad \searrow N_{22} \rightarrow N_{32}\rightarrow N_{42} \\ \quad \quad \quad \quad \quad \searrow N_{33} \rightarrow N_{43} \\ \quad \quad \quad \quad \quad \quad \quad \quad \searrow N_{44} N11→N21→N31→N41↘N22→N32→N42↘N33→N43↘N44
Repeated multi-scale fusion.
我们引入了平行网络信息交换单元,比如每个子网络重复接受来自其他平行子网络的信息。下面是一个例子,展示了信息交换的方案。我们将第三 stage 分为几个(例如3个)交换模块,每个模块由3个并行卷积单元和一个跨并行单元的交换单元组成,其结构如下:

式中 C s r b C^b_{sr} Csrb表示第 sth 个 stage 中bth模块第rth分辨率的卷积单元, ε s b \varepsilon^b_s εsb是相应的信息交换单元。下图是详细说明:
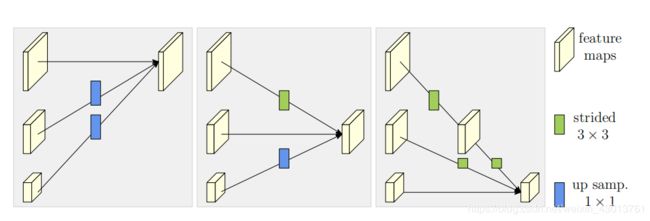
Figure 3图解:交换单元如何从左到右聚合高、中、低分辨率的信息。最右边的图示 strided 3×3 表示使用 strided=3x3的卷积。up samp. 1×1表示使用1x1的卷积进行上采样。
我们在图3中说明交换单元,并在下面给出公式。为了更加方便的解释,这里取消下标 b b b 和 s s s。假设输入到单元的特征图为 { X 1 , X 2 , . . . . . . X s } \{X_1,X_2, \quad ...... \quad X_s\} {X1,X2,......Xs},输出特征图为 { Y 1 , Y 2 , . . . . . . Y s } \{Y_1,Y_2, \quad ...... \quad Y_s\} {Y1,Y2,......Ys}。其输入和输出特征的宽高是一致的。每个输出都是输入映射的集合,表示为 Y s = ∑ i = 1 s a ( X i , k ) Y_s= \sum^s_{i=1}a(X_i,k) Ys=∑i=1sa(Xi,k)。跨阶段的交换单元有一个额外的输出映射: Y s + 1 = a ( Y s , s + 1 ) Y_{s+1}=a{(Y_s,s+1)} Ys+1=a(Ys,s+1)。
a ( X i , k ) a(X_i,k) a(Xi,k)包含了 X i X_i Xi从分辨率 i i i 到 k k k 的上采样或下采样过程。例如,一个 strided = 2x2,kernel=3x3 的卷积进行 2 倍下采样,两个 strided = 2x2,kernel=3x3 的进行四倍下采样。对于上采样,我们采用简单的最近邻抽样方法,kernel=1×1卷积用于通道数对齐。如果 i = k i=k i=k, a ( ⋅ , ⋅ ) a(·,·) a(⋅,⋅) 只是一个识别连接: a ( X i , k ) = X i a(X_i,k)=X_i a(Xi,k)=Xi
Heatmap estimation.
我们通过最后最后一个交换单元,获得高分辨率的特征回归 heatmaps,经过实验对比,我们使用均方误差作为 loss,用于比较预测的 heatmaps 和 标注的 heatmaps。 groundtruth heatmpas 是通过应用,以每个关键点的群真值位置为中心,采用标准差为1像素的二维高斯函数生成。
Network instantiation.
我们设计实现了关键热图估计网络,遵循的设计规则
重新分配深度到每个阶段和通道的数量到每个分辨率。
其中的主体,也就是我们的 HRNet,由四个平行子网络共四个 stages 组成,在每个模块,如果其分辨率逐渐降低到一半,相应的宽度(通道数)增加到两倍。第一个 stages 包含4个剩余单元,其中每个单元与ResNet-50相同,是由一个通道为64的 bottleneck 形成。然后进行一个3×3的卷积,将feature maps的通道数减小到 C C C, 第2、3、4阶段共有1、4、3个信息交换模块,相应的,一个信息交换模块包含4个剩余单元,其中每个单元在每个分辨率中包含两个3×3卷积以及跨分辨率的交换单元。综上所述,共有8个交换单位,即,进行了8次多尺度融合。
在我们的实验中,我们研究了一个小网和一个大网:HRNet-W32和HRNet-W48,其中32和48分别代表了高分辨率子网在最后三个阶段的宽度©。其他三个并行子网的宽度为:HRNet-W32=64、128、256,HRNet-W48=96,192,384。
翻译到这里比较累了,这篇博客就到这里为止了,下篇博客继续为大家翻译。