利用Python+PowerBi进行拉勾网杭州站的数据采集及可视化分析之爬虫篇
思路:
1、获取到拉勾网的所有岗位信息
2、一个一个岗位进行获取数据
只考虑杭州. 但是其他城市可以参考
https://www.lagou.com/lbs/getAllCitySearchLabels.json
这个json,里面都是各种城市名单. 按照这个+岗位,可以爬全国
一、获取拉勾网杭州站的岗位信息

在这里,可以看到 拉勾网 所有的岗位(理论上??) . 我猜啦...不然也找不到其他的地方能找到岗位数据了

这里的源代码也很简单.直接用正则表达式来爬即可.
#时间 2018/06/21 17:24
#提取职位分类跟具体职位.方便后期根据具体职位进行搜索
import requests # 网络请求
import re
import time
import random
from bs4 import BeautifulSoup
import pandas as pd
url='https://www.lagou.com/'
html = requests.get(url)
html = html.text.encode(html.encoding).decode()
soup= BeautifulSoup(html,'html.parser')
dataList=[]
for i in soup.find_all("div",{"class":"menu_sub dn"}): #这里主要是为了获取到岗位的二级分类.
for i2 in i.find_all("dl"):
bigposition=re.search(r'(.*?)',str(i2)).group(1)
list=re.findall('>(.*?)',str(i2))
for row in list:
dataList.append([bigposition,row])
dataList.insert(0,["分类","职位"]) #在list最前面插入column名.
dataList=pd.DataFrame(dataList)
dataList.to_csv(r"C:\Users\Jack\Desktop\lagouPositionData.csv",encoding = "utf-8",mode="a+",index=0,header=0)
最后出来的就是这样子的啦~
一个个二级分类+具体的岗位名. 扫了一眼,理论上应该覆盖大部分拉钩网上面的职位了.
二、获取关键字的岗位信息
这一步,网上的各位大神已经写烂了. 无非就是抓包后发现其实是通过发送一个post进行提交数据.
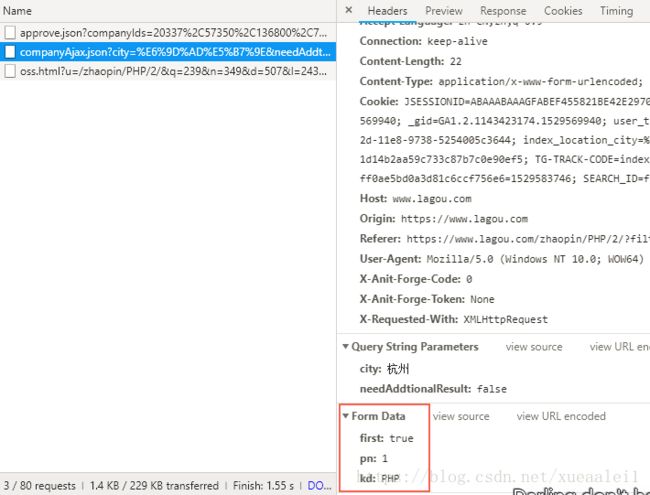
当然,first要改成false. pn就是pagenumber,kd就是...key..key什么来着.. 就当他是关键词吧..
虽然说前端展示只有30页. 但是可以通过totalcount来得到总共有多少个岗位.然后/15.就知道是多少页了.
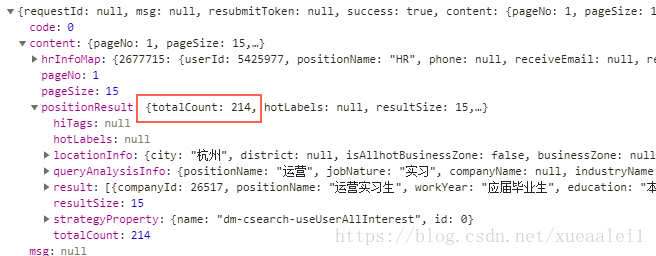
这样子就可以遍历所有的该关键词的岗位啦.
同时,爬取关键信息的话. 我建议是利用正则表达式一个个进行抓取.
因为拉勾网经常改... 一改结构的话,好多网上的教程里的正则都不能用了.

我是这么写的.
data = re.findall('{"companyId":.*?,"positionName":"(.*?)","workYear":"(.*?)","education":"(.*?)",
"jobNature":"(.*?)","financeStage":"(.*?)","companyLogo":".*?","industryField":".*?",
"city":"(.*?)","salary":"(.*?)","positionId":.*?,"positionAdvantage":"(.*?)",
"companyShortName":"(.*?)","district"',html.text)import requests
import re
import time
import random
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false&isSchoolJob=0'
url = 'https://www.lagou.com/jobs/positionAjax.json?city=杭州&needAddtionalResult=false'
#只查看杭州的的数据 . 这里是只想要爬杭州的数据. 所以多加了一条赋值
# 这里的header自己随手拉一个出来啦
header = {'Host': 'www.lagou.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,en-US;q=0.7,en;q=0.3',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput=',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'X-Anit-Forge-Token': 'None',
'X-Anit-Forge-Code': '0',
'Content-Length': '26',
'Cookie': '327d4eb',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache'}def get_max_page(keyword): #来获取某个关键字的最大页数. 方便遍历. 同时,如果没有这个岗位的话,会自动返回max_page=0的
global max_page
form = {'first':'false','kd':'python','pn':1}
form['kd']=keyword
html = requests.post(url,data=form,headers = header)
soup= BeautifulSoup(html.text,'html.parser')
max_page=int(re.search('{"totalCount":([0-9]+),"',str(soup)).group(1))
if max_page%15==0:
max_page=max_page//15
else:
max_page=max_page//15+1
def get_detail(keyword,pn): #利用关键词和页码,配合上面的最大页数来爬.
global n
form = {'first':'false',
'kd':'实习',
'pn':53}
form['kd']=keyword
form['pn']=pn
# 提交数据
html = requests.post(url,data=form,headers = header)
soup= BeautifulSoup(html.text,'html.parser')
list=[]
for i in str(soup)[str(soup).find('"result":[')+10:].split('},{'):
#这里有个比较low的地方. 为了逐条来使用正则表达式. 我把每页15条数据,利用 " },{ " 这个符号直接隔开.
#这样可以生成15条岗位数据. 另外, "result": 以后的才是岗位信息,所以做了一个切割.
try:
positionId=re.search(',"positionId":(.*?),"',str(i)).group(1)
companyId=re.search('"companyId":(.*?),"',str(i)).group(1)
positionName=re.search(',"positionName":"(.*?)","',str(i)).group(1)
workYear=re.search(',"workYear":"(.*?)","',str(i)).group(1)
education=re.search(',"education":"(.*?)","',str(i)).group(1)
jobNature=re.search(',"jobNature":"(.*?)","',str(i)).group(1)
city=re.search(',"city":"(.*?)","',str(i)).group(1)
industryField=re.search(',"industryField":"(.*?)","',str(i)).group(1)
positionAdvantage=re.search(',"positionAdvantage":"(.*?)","',str(i)).group(1)
industryLables=re.search(',"industryLables":(\[.*?\]),"',str(i)).group(1)
financeStage=re.search(',"financeStage":"(.*?)","',str(i)).group(1)
companyLabelList=re.search(',"companyLabelList":(\[.*?\]),',str(i)).group(1)
firstType=re.search(',"firstType":"(.*?)","',str(i)).group(1)
secondType=re.search(',"positionName":"(.*?)","',str(i)).group(1)
list.append([positionId,companyId,positionName,workYear,education,jobNature,city,industryField,positionAdvantage,
industryLables,financeStage,companyLabelList,firstType,secondType,salary,keyword])
except AttributeError:
print('无法爬取') #这个逻辑设置的话,因为出现错误,n不会+1. 相当于重新开始.
continue
Data=pd.DataFrame(list)
Data.to_csv(r"C:\Users\Jack\Desktop\lagouData.csv",encoding = "utf-8",mode="a+",index=0,header=0)
print('完成',keyword,'第',pn,'页')
n+=1
import numpy as np
data=pd.read_csv("C:\\Users\\Jack\\Desktop\\lagouPositionData.csv")
data=np.array(data).tolist() #读取岗位信息.并将其改成list
for i in data:
keyword=i[1]
get_max_page(keyword)
print('开始爬取职位:',keyword,', 共',max_page,'页')
n=1
if max_page>=1:
while n<=max_page:
get_detail(keyword,n)
time.sleep(10) #我知道应该randint的..但是..
print('休息10秒钟啦')
print('全部都完成啦~~~')然后就是开开心心地跑起来啦.

在写这篇文档的时候,爬虫还在持续中,还没有报错....
希望能一口气爬完,我就能进行分析啦~~
PS:
以上过程中,没有考虑到 去重.
因为已经有positionid了. 如果去重的话,其实还蛮讨厌的. 之前我数据库导入的时候总是喜欢考虑去重方案.
后来发现,还是在分析环节去重会好很多.
当然了,如果说是爬小说啊,什么,数据量比较大,还是要考虑下去重的.