SMO算法
本文转自:http://blog.sina.com.cn/s/blog_89ba75c80101gxgg.html
SMO算法
在上文2.1.2节中,我们提到了求解对偶问题的序列最小最优化SMO算法,但并未提到其具体解法。
事实上,SMO算法是由Microsoft Research的John C. Platt在1998年发表的一篇论文《Sequential Minimal Optimization A Fast Algorithm for Training Support Vector Machines》中提出,它很快成为最快的二次规划优化算法,特别针对线性SVM和数据稀疏时性能更优。
接下来,咱们便参考John C. Platt的这篇文章来看看SMO的解法是怎样的。
3.5.1、SMO算法的解法
咱们首先来定义特征到结果的输出函数为
再三强调,这个u与我们之前定义的 实质是一样的。
实质是一样的。
接着,咱们重新定义咱们原始的优化问题,权当重新回顾,如下:

求导得到:

代入 中,可得
中,可得 。
。
引入对偶因子后,得:

s.t:
且
注:这里得到的min函数与我们之前的max函数实质也是一样,因为把符号变下,即有min转化为max的问题,且yi也与之前的 等价,yj亦如此。
等价,yj亦如此。


从而最终我们的问题变为:

继而,根据KKT条件可以得出其中 取值的意义为:
取值的意义为:
 还是拉格朗日乘子(问题通过拉格朗日乘法数来求解)
还是拉格朗日乘子(问题通过拉格朗日乘法数来求解)
- 对于第1种情况,表明是正常分类,在边界内部(我们知道正确分类的点yi*f(xi)>=0);
- 对于第2种情况,表明了是支持向量,在边界上;
- 对于第3种情况,表明了是在两条边界之间;
 <=1但是=C
<=1但是=C - >=1但是>0则是不满足的而原本=0
- =1但是=0或者=C则表明不满足的,而原本应该是0<
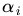
注:别忘了2.1.1节中,L对a、b求偏导,得到:


 ,
,
 ,
,
 表示旧值。
表示旧值。

 :
:

 的上下界分别为:
的上下界分别为:

 。
。
- 对于ai,即第一个乘子,可以通过刚刚说的那3种不满足KKT的条件来找;
- 而对于第二个乘子aj可以找满足条件 :
 求得。
求得。



3.5.2、SMO算法的步骤

- 第一步选取一对
 和
和 ,选取方法使用启发式方法;
,选取方法使用启发式方法; - 第二步,固定除和之外的其他参数,确定W极值条件下的,由表示。
 ,
,
 对应的拉格朗日乘子
对应的拉格朗日乘子
 ,
,
 ,那么这个小规模的二次规划问题写为:
,那么这个小规模的二次规划问题写为:



知道了如何更新乘子,那么选取哪些乘子进行更新呢?具体选择方法有以下两个步骤:
- 步骤1:先“扫描”所有乘子,把第一个违反KKT条件的作为更新对象,令为a2;
- 步骤2:在所有不违反KKT条件的乘子中,选择使|E1 −E2|最大的a1(注:别忘了,其中,而,求出来的E代表函数ui对输入xi的预测值与真实输出类标记yi之差)。
- 使乘子能满足KKT条件
- 对一个满足KKT条件的乘子进行更新,应能最大限度增大目标函数的值(类似于梯度下降)
综上,SMO算法的基本思想是将Vapnik在1982年提出的Chunking方法推到极致,SMO算法每次迭代只选出两个分量ai和aj进行调整,其它分量则保持固定不变,在得到解ai和aj之后,再用ai和aj改进其它分量。与通常的分解算法比较,尽管它可能需要更多的迭代次数,但每次迭代的计算量比较小,所以该算法表现出整理的快速收敛性,且不需要存储核矩阵,也没有矩阵运算。
3.5.3、SMO算法的实现
行文至此,我相信,SVM理解到了一定程度后,是的确能在脑海里从头至尾推导出相关公式的,最初分类函数,最大化分类间隔,max1/||w||,min1/2||w||^2,凸二次规划,拉格朗日函数,转化为对偶问题,SMO算法,都为寻找一个最优解,一个最优分类平面。一步步梳理下来,为什么这样那样,太多东西可以追究,最后实现。如下图所示:

至于下文中将阐述的核函数则为是为了更好的处理非线性可分的情况,而松弛变量则是为了纠正或约束少量“不安分”或脱离集体不好归类的因子。
台湾的林智仁教授写了一个封装SVM算法的libsvm库,大家可以看看,此外这里还有一份libsvm的注释文档。
除了在这篇论文《fast training of support vector machines using sequential minimal optimization》中platt给出了SMO算法的逻辑代码之外,这里也有一份SMO的实现代码,大家可以看下。
3.6、SVM的应用
或许我们已经听到过,SVM在很多诸如文本分类,图像分类,生物序列分析和生物数据挖掘,手写字符识别等领域有很多的应用,但或许你并没强烈的意识到,SVM可以成功应用的领域远远超出现在已经在开发应用了的领域。
3.6.1、文本分类
一个文本分类系统不仅是一个自然语言处理系统,也是一个典型的模式识别系统,系统的输入是需要进行分类处理的文本,系统的输出则是与文本关联的类别。由于篇幅所限,其它更具体内容本文将不再详述。
OK,本节虽取标题为证明SVM,但聪明的读者们想必早已看出,其实本部分并无多少证明部分(特此致歉),怎么办呢?可以参阅《支持向量机导论》一书,此书精简而有趣。本节完。
读者评论
- “压力”陡增的评论→//@藏了个锋:我是看着July大神的博文长大的啊//@zlkysl:就是看了最后那一篇才决定自己的研究方向为SVM的。--http://weibo.com/1580904460/zraWk0u6u?mod=weibotime。
- @张金辉:“SVM的三重境界,不得不转的一篇。其实Coursera的课堂上Andrew Ng讲过支持向量机,但显然他没有把这作为重点,加上Ng讲支持向量机的方法我一时半会难以完全消化,所以听的也是一知半解。真正开始了解支持向量机就是看的这篇“三重境界”,之后才对这个算法有了大概的概念,以至如何去使用,再到其中的原理为何,再到支持向量机的证明等。总之,这篇文章开启了我长达数月的研究支持向量机阶段,直到今日。”--http://zhan.renren.com/profile/249335584?from=template#!//tag/三重境界。
- @孤独之守望者:"最后,推出svm的cost function 是hinge loss,然后对比其他的方法的cost function,说明其实他们的目标函数很像,那么问题是svm为什么这么popular呢?您可以再加些VC dimension跟一些error bound的数学,点一下,提供一个思路和方向"。--http://weibo.com/1580904460/AiohoyDwq?mod=weibotime。
- @夏粉_百度:“在面试时,考察SVM可考察机器学习各方面能力:目标函数,优化过程,并行方法,算法收敛性,样本复杂度,适用场景,调参经验,不过个人认为考察boosting和LR也还不错啊。此外,随着统计机器学习不断进步,SVM只被当成使用了一个替代01损失hinge研究,更通用的方法被提出,损失函数研究替代损失与贝叶斯损失关系,算法稳定性研究替代损失与推广性能关系,凸优化研究如何求解凸目标函数,SVM,boosting等算法只是这些通用方法的一个具体组建而已。”
- @居里猴姐:关于SVM损失函数的问题,可以看看张潼老师的这篇《Statistical behavior and consistency of classification methods based on convex risk minimization》。各种算法中常用的损失函数基本都具有fisher一致性,优化这些损失函数得到的分类器可以看作是后验概率的“代理”。此外,张潼老师还有另外一篇论文《Statistical analysis of some multi-category large margin classification methods》,在多分类情况下margin loss的分析,这两篇对Boosting和SVM使用的损失函数分析的很透彻。
- @夏粉_百度:SVM用了hinge损失,hinge损失不可导,不如其它替代损失方便优化并且转换概率麻烦。核函数也不太用,现在是大数据时代,样本非常大,无法想象一个n^2的核矩阵如何存储和计算。而且,现在现在非线性一般靠深度学习了。//@Copper_PKU:请教svm在工业界的应用典型的有哪些?工业界如何选取核函数,经验的方法?svm的训练过程如何优化?
- @Copper_PKU:July的svm tutorial 我个人觉得还可以加入和修改如下部分:(1) 对于支持向量解释,可以结合图和拉格朗日参数来表达,松弛中sv没有写出来. (2) SMO算法部分,加入Joachims论文中提到的算法,以及SMO算法选取workset的方法,包括SMO算法的收敛判断,还有之前共轭梯度求解方法,虽然是较早的算法,但是对于理解SMO算法有很好的效果。模型的优化和求解都是迭代的过程,加入历史算法增强立体感。-- http://weibo.com/1580904460/Akw6dl3Yk#_rnd1385474436177。
- //@廖临川: 之所以sgd对大训练集的效果更好,1.因为SGD优化每次迭代使用样本子集,比使用训练全集(尤其是百万数量级)要快得多;2.如果目标函数是凸的或者伪凸的,SGD几乎必然可以收敛到全局最优;否则,则收敛到局部最优;3.SGD一般不需要收敛到全局最优,只要得到足够好的解,就可以立即停止。//@Copper_PKU:sgd的核心思想:是迭代训练,每拿到一个样本就算出基于当前w(t) 的loss function,t代表训练第t次,然后进行下一w(t+1)的更新,w(t+1)=w(t)-(learning rate) * loss function的梯度,这个类比神经网络中bp中的参数训练方法。 sample by sample就是每次仅处理一个样本而不是一个batch。
- //@Copper_PKU:从损失函数角度说:primal问题可以理解为正则化项+lossfunction,求解目标是在两个中间取平衡如果强调loss function最小则会overfitting,所以有C参数。 //@研究者July:SVM还真就是在一定限定条件下,即约束条件下求目标函数的最优值问题,同时,为减少误判率,尽量让损失最小。
- ...
参考文献及推荐阅读
- 《支持向量机导论》,[美] Nello Cristianini / John Shawe-Taylor 著;
- 支持向量机导论一书的支持网站:http://www.support-vector.net/;
- 《数据挖掘导论》,[美] Pang-Ning Tan / Michael Steinbach / Vipin Kumar 著;
- 《数据挖掘:概念与技术》,(加)Jiawei Han;Micheline Kamber 著;
- 《数据挖掘中的新方法:支持向量机》,邓乃扬 田英杰著;
- 《支持向量机--理论、算法和扩展》,邓乃扬田英杰 著;
- 支持向量机系列,pluskid:http://blog.pluskid.org/?page_id=683;
- http://www.360doc.com/content/07/0716/23/11966_615252.shtml;
- 数据挖掘十大经典算法初探;
- 《模式识别支持向量机指南》,C.J.C Burges 著;
- 《统计学习方法》,李航著(第7章有不少内容参考自支持向量机导论一书,不过,可以翻翻看看);
- 《统计自然语言处理》,宗成庆编著,第十二章、文本分类;
- SVM入门系列,Jasper:http://www.blogjava.net/zhenandaci/category/31868.html;
- 最近邻决策和SVM数字识别的实现和比较,作者不详;
- 斯坦福大学机器学习课程原始讲义:http://www.cnblogs.com/jerrylead/archive/2012/05/08/2489725.html;
- 斯坦福机器学习课程笔记:http://www.cnblogs.com/jerrylead/tag/Machine Learning/;
- http://www.cnblogs.com/jerrylead/archive/2011/03/13/1982639.html;
- SMO算法的数学推导:http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html;
- 数据挖掘掘中所需的概率论与数理统计知识、上;
- 关于机器学习方面的文章,可以读读:http://www.cnblogs.com/vivounicorn/category/289453.html;
- 数学系教材推荐:http://blog.sina.com.cn/s/blog_5e638d950100dswh.html;
- 《神经网络与机器学习(原书第三版)》,[加] Simon Haykin 著;
- 正态分布的前世今生:http://t.cn/zlH3Ygc;
- 《数理统计学简史》,陈希孺院士著;
- 《最优化理论与算法(第2版)》,陈宝林编著;
- A Gentle Introduction to Support Vector Machines in Biomedicine:http://www.nyuinformatics.org/downloads/supplements/SVM_Tutorial_2010/Final_WB.pdf,此PPT很赞,除了对引入拉格朗日对偶变量后的凸二次规划问题的深入度不够之外,其它都挺好,配图很精彩,本文有几张图便引自此PPT中;
- 来自卡内基梅隆大学carnegie mellon university(CMU)的讲解SVM的PPT:http://www.autonlab.org/tutorials/svm15.pdf;
- 发明libsvm的台湾林智仁教授06年的机器学习讲义SVM:http://wenku.baidu.com/link?url=PWTGMYNb4HGUrUQUZwTH2B4r8pIMgLMiWIK1ymVORrds_11VOkHwp-JWab7IALDiors64JW_6mD93dtuWHwFWxsAk6p0rzchR8Qh5_4jWHC;
- http://staff.ustc.edu.cn/~ketang/PPT/PRLec5.pdf;
- Introduction to Support Vector Machines (SVM),By Debprakash Patnai M.E (SSA),https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&ved=0CCwQFjAA&url=http://www.pws.stu.edu.tw/ccfang/index.files/AI/AI&ML-Support Vector Machine-1.ppt&ei=JRR6UqT5C-iyiQfWyIDgCg&usg=AFQjCNGw1fTbpH4ltQjjmx1d25ZqbCN9nA;
- 多人推荐过的libsvm:http://www.csie.ntu.edu.tw/~cjlin/libsvm/;
- 《machine learning in action》,中文版为《机器学习实战》;
- SMO算法的提出:Sequential Minimal Optimization A Fast Algorithm for Training Support Vector Machines:http://research.microsoft.com/en-us/um/people/jplatt/smoTR.pdf;
- 《统计学习理论的本质》,[美] Vladimir N. Vapnik著,非常晦涩,不做过多推荐;
- 张兆翔,机器学习第五讲之支持向量机http://irip.buaa.edu.cn/~zxzhang/courses/MachineLearning/5.pdf;
- VC维的理论解释:http://www.svms.org/vc-dimension/,中文VC维解释http://xiaoxia001.iteye.com/blog/1163338;
- 来自NEC Labs America的Jason Weston关于SVM的讲义http://www.cs.columbia.edu/~kathy/cs4701/documents/jason_svm_tutorial.pdf;
- 来自MIT的SVM讲义:http://www.mit.edu/~9.520/spring11/slides/class06-svm.pdf;
- PAC问题:http://www.cs.huji.ac.il/~shashua/papers/class11-PAC2.pdf;
- 百度张潼老师的两篇论文:《Statistical behavior and consistency of classification methods based on convex risk minimization》http://home.olemiss.edu/~xdang/676/Consistency_of_Classification_Convex_Risk_Minimization.pdf,《Statistical analysis of some multi-category large margin classification methods》;
- http://jacoxu.com/?p=39;
- 《矩阵分析与应用》,清华张贤达著;
- SMO算法的实现:http://blog.csdn.net/techq/article/details/6171688;
- 常见面试之机器学习算法思想简单梳理:http://www.cnblogs.com/tornadomeet/p/3395593.html;
- 矩阵的wikipedia页面:http://zh.wikipedia.org/wiki/矩阵;
- 最小二乘法及其实现:http://blog.csdn.net/qll125596718/article/details/8248249;
- 统计学习方法概论:http://blog.csdn.net/qll125596718/article/details/8351337;
- http://www.csdn.net/article/2012-12-28/2813275-Support-Vector-Machine;
- A Tutorial on Support Vector Regression:http://alex.smola.org/papers/2003/SmoSch03b.pdf;SVR简明版:http://www.cmlab.csie.ntu.edu.tw/~cyy/learning/tutorials/SVR.pdf。
- SVM Org:http://www.support-vector-machines.org/;
- R. Collobert. Large Scale Machine Learning. Université Paris VI phd thesis. 2004:http://ronan.collobert.com/pub/matos/2004_phdthesis_lip6.pdf;
- Making Large-Scale SVM Learning Practical:http://www.cs.cornell.edu/people/tj/publications/joachims_99a.pdf;
- 文本分类与SVM:http://blog.csdn.net/zhzhl202/article/details/8197109;
- Working Set Selection Using Second Order Information
for Training Support Vector Machines:http://www.csie.ntu.edu.tw/~cjlin/papers/quadworkset.pdf; - SVM Optimization: Inverse Dependence on Training Set Size:http://icml2008.cs.helsinki.fi/papers/266.pdf;
- Large-Scale Support Vector Machines: Algorithms and Theory:http://cseweb.ucsd.edu/~akmenon/ResearchExam.pdf;
- 凸优化的概念:http://cs229.stanford.edu/section/cs229-cvxopt.pdf;
- 《凸优化》,作者: Stephen Boyd / Lieven Vandenberghe,原作名: Convex Optimization;
- Large-scale Non-linear Classification: Algorithms and Evaluations,Zhuang Wang,讲了很多SVM算法的新进展:http://ijcai13.org/files/tutorial_slides/te2.pdf;
后记
- 13年11月25日,用chrome浏览器打开文章,右键打印,弹出打印框,把左上角的目标更改为“另存为PDF”,成第一个PDF:http://vdisk.weibo.com/s/zrFL6OXKghu5V。
- 13年12月7日,用“印象笔记”提取出博客正文,放到office内编辑成此PDF:http://vdisk.weibo.com/s/zrFL6OXKgQHm8,较上一版本添加了完整的书签。
- 14年 2月18日,用Latex全部重排了本文所有公式,而且给所有公式和图片全部做了标记,Latex版下载地址为:http://vdisk.weibo.com/s/zrFL6OXKgnlcp。
本文会一直不断翻新,再者,上述3个PDF的阅读体验也还不是最好的,如果有朋友制作了更好的PDF,欢迎分享给我:http://weibo.com/julyweibo,谢谢。
July、二零一四年二月十一日于天通苑。