视频学习
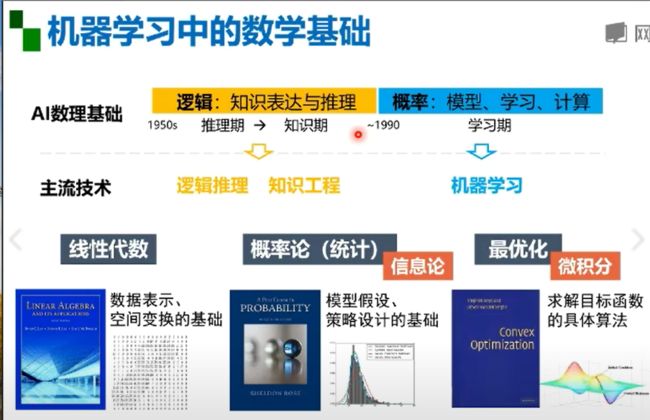
机器学习的数学基础
特征向量形象化的描述:对一个矩阵施加线性变换后,使矩阵发生尺度变化而不改变方向。
秩形象化的描述:秩序,复杂度,一个数据分布很容易被捕捉,则秩小,很难被捕捉,则秩大。
数据降维:只保留前R个较大奇异值及其对应的特征向量(较大奇异值包含了矩阵的主要信息)。
低秩近似:保留决定数据分布的最主要的模式/方向(丢弃的可能是噪声或其他不关键的信息)。
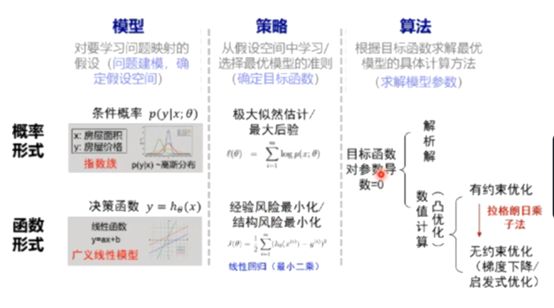
概率/函数形式的统一:
问题补充:
逐层训练时,在训练下一层时,会冻结上一层的参数。
逐层预训练初始化参数是为了更好的初始化,使其落到比较好的区域里面。
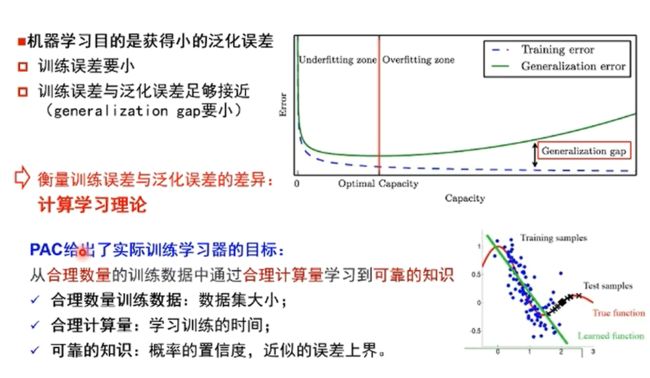
策略设计:训练误差->泛化误差

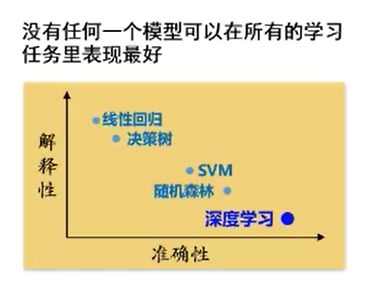
免费午餐定理:
奥卡姆剃刀原理:
“如无必要,勿增实体”, 即“简单有效原理”。如果多种模型能够同等程度地符合一个问题的观测结果,应选择其中使用假设最少的->最简单的模型。
欠拟合和过拟合的解决办法:
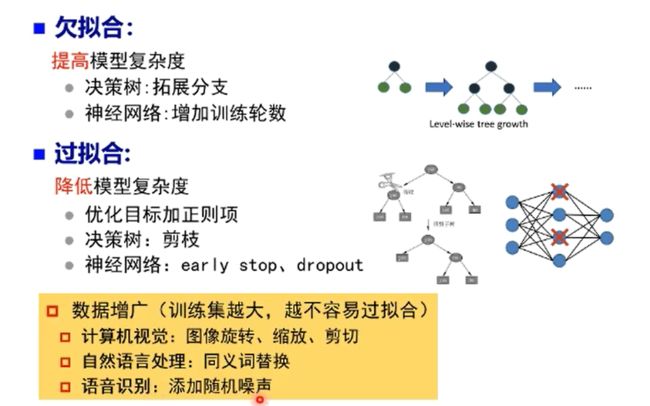
频率学派VS贝叶斯学派:
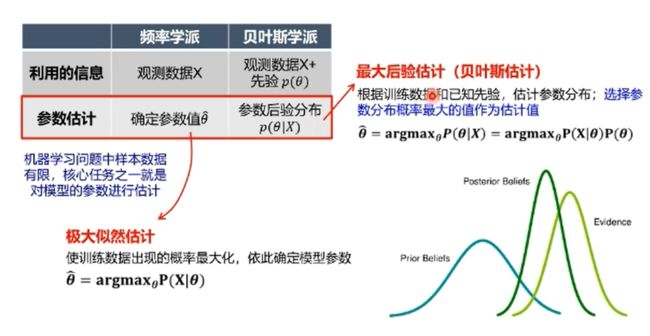
频率学派VS机器学习方法:
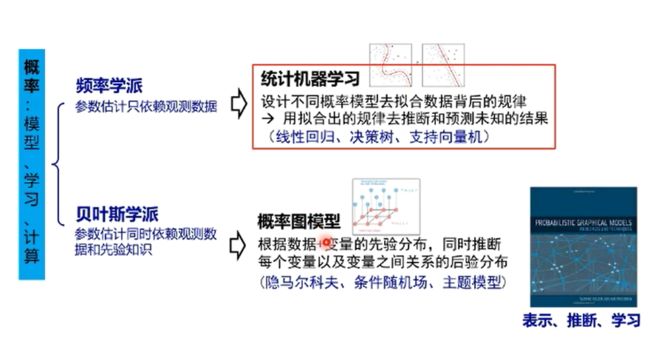
卷积神经网络基本组成结构
卷积神经网络的应用:分类、检索、检测、分割人脸识别、人脸验证、人脸表情识别、图像生成图像风格转换、自动驾驶。
传统神经网络VS卷积神经网络:
深度学习的三部曲:
1.搭建神经网络结构
2.找到一个合适的损失函数
3.找到一个合适的优化函数,更新参数
损失函数:
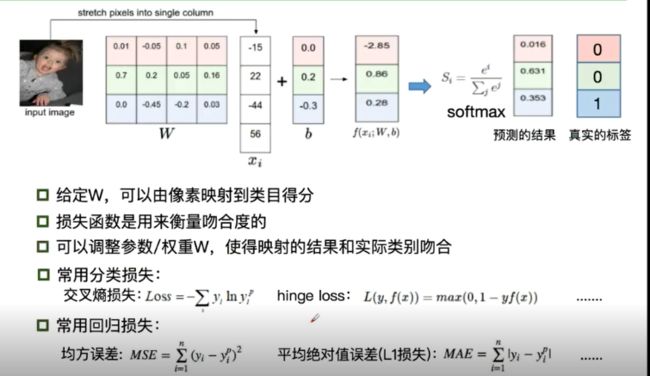
全连接网络处理图像的问题:参数太多:权重矩阵的参数太多->过拟合
卷积络的解决方式:局部关联,参数共享
两者的相同之处:都有卷积层、激活层、池化层和全连接层
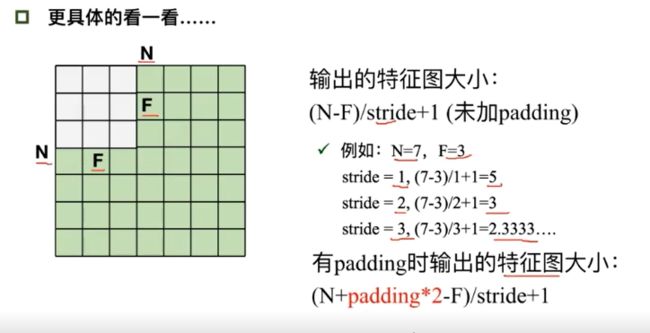
卷积:

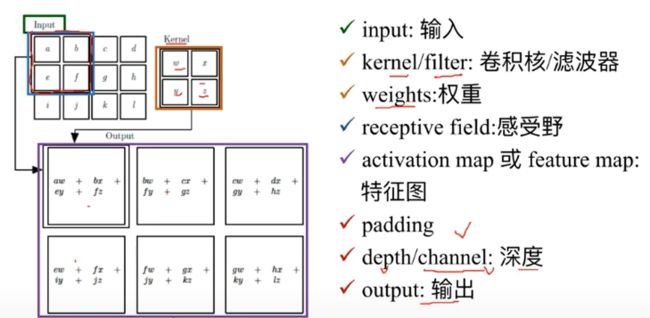

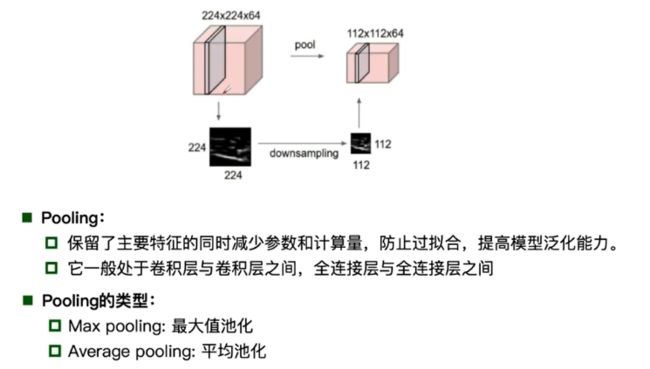
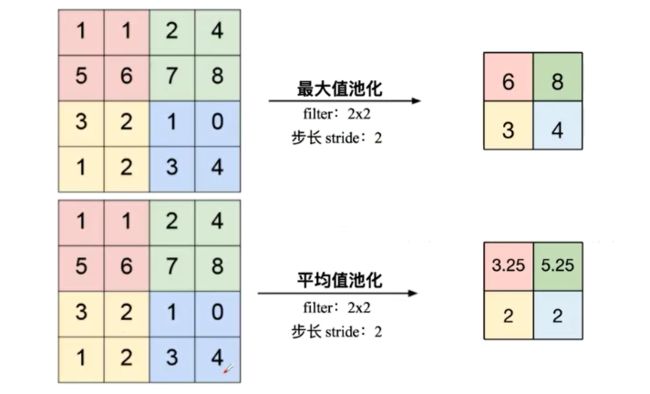
池化:
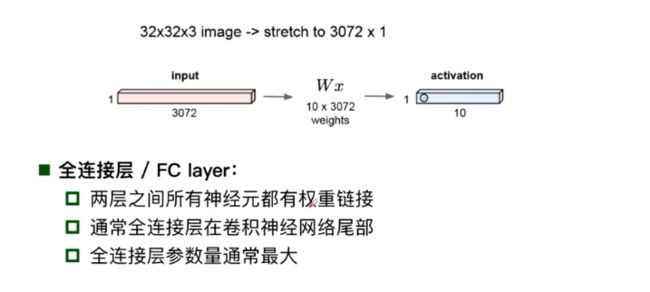
全连接:

卷积神经网络的典型架构
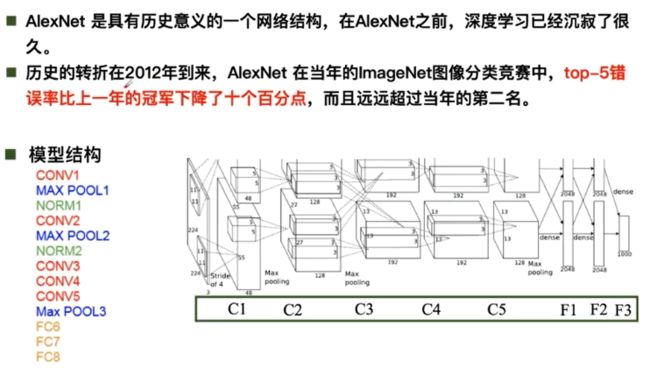
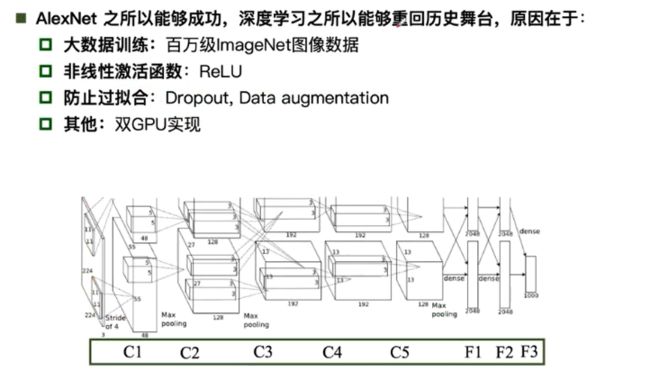
Alexnet:
ZFNet:

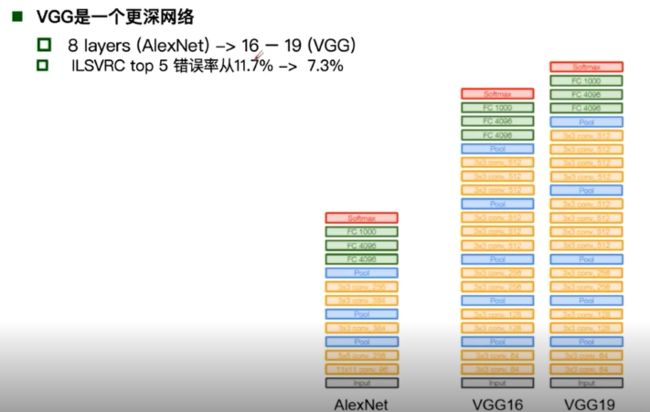
VGG:
GoogleNet:
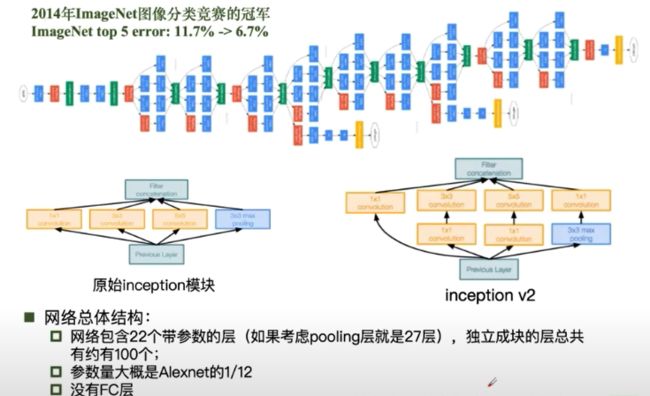
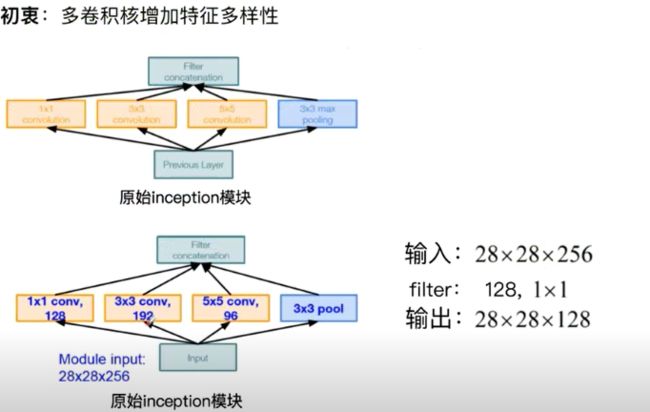
GoogleNet:Naive Inception 的计算复杂度过高
GoogleNet:Inception 插入1*1卷积核进行降维
GoogleNet:Inception V3 对V2的参数数量进行降低 增加非线性激活函数,使其表征能力更强,训练更快。
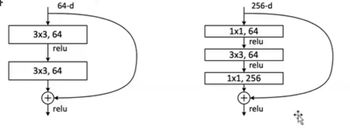
ResNet:
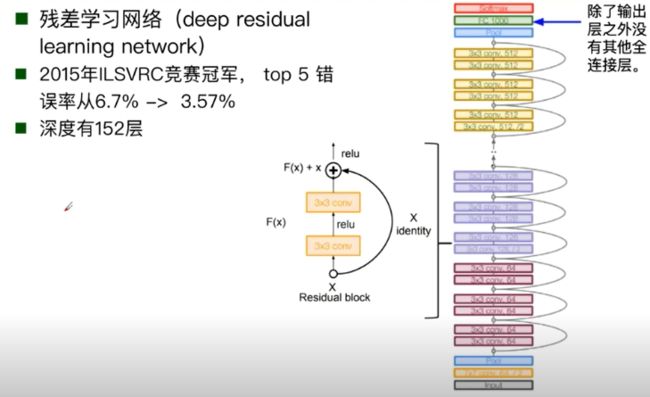
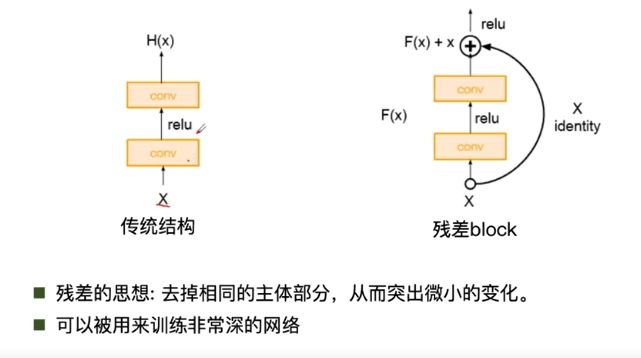
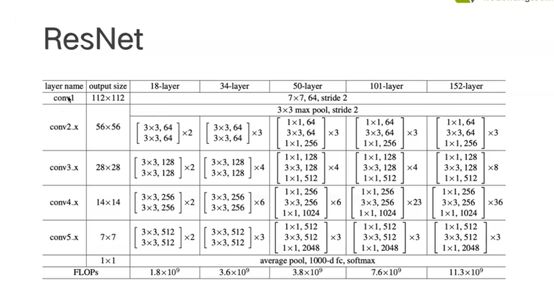
面试小问题:ResNet50层以下和50层以上有啥区别:50层以上由bottleNeck,50层以下没有
MNIST数据集分类
深度神经网络的特性:
- 很多层: compositionality
- 卷积: locality + stationarity of images
- 池化: Invariance of object class to translations
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy
# 计算模型当中含有多少参数
def get_n_params(model):
np = 0
for p in list(model.parameters()):
np += p.nelement()
return np
# 使用GPU来进行训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
1.加载数据(MINST)
Pytorch里面含有MINST、CIFAR10等常用的数据集,调用 torchvision.datasets 即可把这些数据由远程下载到本地
MNIST的使用方法:
torchvision.datasets.MNIST(root, train=True, transform=None, target_transform=None, download=False)
- root 为数据集下载到本地后的根目录,包括 training.pt 和 test.pt 文件
- train,如果设置为True,从training.pt创建数据集,否则从test.pt创建。
- download,如果设置为True, 从互联网下载数据并放到root文件夹下
- transform, 一种函数或变换,输入PIL图片,返回变换之后的数据。
- target_transform 一种函数或变换,输入目标,进行变换。
另外值得注意的是,DataLoader是一个比较重要的类,提供的常用操作有:batch_size(每个batch的大小), shuffle(是否进行随机打乱顺序的操作), num_workers(加载数据的时候使用几个子进程)
input_size = 28*28 # MINST上的图像是28*28大的
output_size = 10 # 类别是0-9的数字 因此分为十类
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train = True, download = True, transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))])),
batch_size = 64, shuffle = True)
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train = False, transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))])),
batch_size = 1000, shuffle = True)
显示数据集中的部分图像
plt.figure(figsize = (8, 5))
for i in range(20):
plt.subplot(4, 5, i + 1)
image, _ = train_loader.dataset.__getitem__(i)
plt.imshow(image.squeeze().numpy(),'gray')
plt.axis('off');

2.创建网络
定义网络时,需要继承nn.Module,并实现它的forward方法,把网络中具有可学习参数的层放在构造函数init中。
只要在nn.Module的子类中定义了forward函数,backward函数就会自动被实现(利用autograd)。
class FC2Layer(nn.Module):
def __init__(self, input_size, n_hidden, output_size):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
# 下式等价于nn.Module.__init__(self)
super(FC2Layer, self).__init__()
self.input_size = input_size
# 这里直接用 Sequential 就定义了网络,注意要和下面 CNN 的代码区分开
self.network = nn.Sequential(
nn.Linear(input_size, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, output_size),
nn.LogSoftmax(dim=1)
)
def forward(self, x):
# view一般出现在model类的forward函数中,用于改变输入或输出的形状
# x.view(-1, self.input_size) 的意思是多维的数据展成二维
# 代码指定二维数据的列数为 input_size=784,行数 -1 表示我们不想算,电脑会自己计算对应的数字
# 在 DataLoader 部分,我们可以看到 batch_size 是64,所以得到 x 的行数是64
# 大家可以加一行代码:print(x.cpu().numpy().shape)
# 训练过程中,就会看到 (64, 784) 的输出,和我们的预期是一致的
# forward 函数的作用是,指定网络的运行过程,这个全连接网络可能看不啥意义,
# 下面的CNN网络可以看出 forward 的作用。
x = x.view(-1, self.input_size)
return self.network(x)
class CNN(nn.Module):
def __init__(self, input_size, n_feature, output_size):
# 执行父类的构造函数,所有的网络都要这么写
super(CNN, self).__init__()
# 下面是网络里典型结构的一些定义,一般就是卷积和全连接
# 池化、ReLU一类的不用在这里定义
self.n_feature = n_feature
self.conv1 = nn.Conv2d(in_channels=1, out_channels=n_feature, kernel_size=5)
self.conv2 = nn.Conv2d(n_feature, n_feature, kernel_size=5)
self.fc1 = nn.Linear(n_feature*4*4, 50)
self.fc2 = nn.Linear(50, 10)
# 下面的 forward 函数,定义了网络的结构,按照一定顺序,把上面构建的一些结构组织起来
# 意思就是,conv1, conv2 等等的,可以多次重用
def forward(self, x, verbose=False):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = x.view(-1, self.n_feature*4*4)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
定义训练和测试函数
# 训练函数
def train(model):
model.train()
# 主里从train_loader里,64个样本一个batch为单位提取样本进行训练
for batch_idx, (data, target) in enumerate(train_loader):
# 把数据送到GPU中
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
# 把数据送到GPU中
data, target = data.to(device), target.to(device)
# 把数据送入模型,得到预测结果
output = model(data)
# 计算本次batch的损失,并加到 test_loss 中
test_loss += F.nll_loss(output, target, reduction='sum').item()
# get the index of the max log-probability,最后一层输出10个数,
# 值最大的那个即对应着分类结果,然后把分类结果保存在 pred 里
pred = output.data.max(1, keepdim=True)[1]
# 将 pred 与 target 相比,得到正确预测结果的数量,并加到 correct 中
# 这里需要注意一下 view_as ,意思是把 target 变成维度和 pred 一样的意思
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
accuracy))
3.在小型全连接网络上训练(Fully-connected network)
n_hidden = 8 # number of hidden units
model_fnn = FC2Layer(input_size, n_hidden, output_size)
model_fnn.to(device)
optimizer = optim.SGD(model_fnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_fnn)))
train(model_fnn)
test(model_fnn)
Number of parameters: 6442
Train: [0/60000 (0%)] Loss: 2.287285
Train: [6400/60000 (11%)] Loss: 1.967152
Train: [12800/60000 (21%)] Loss: 1.261107
Train: [19200/60000 (32%)] Loss: 0.959287
Train: [25600/60000 (43%)] Loss: 0.747636
Train: [32000/60000 (53%)] Loss: 0.476292
Train: [38400/60000 (64%)] Loss: 0.652557
Train: [44800/60000 (75%)] Loss: 0.392811
Train: [51200/60000 (85%)] Loss: 0.443054
Train: [57600/60000 (96%)] Loss: 0.350913
Test set: Average loss: 0.4373, Accuracy: 8715/10000 (87%)
4、在卷积神经网络上训练
定义的CNN和全连接网络拥有相同数量的模型参数
# Training settings
n_features = 6 # number of feature maps
model_cnn = CNN(input_size, n_features, output_size)
model_cnn.to(device)
optimizer = optim.SGD(model_cnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_cnn)))
train(model_cnn)
test(model_cnn)
Number of parameters: 6422
Train: [0/60000 (0%)] Loss: 2.260017
Train: [6400/60000 (11%)] Loss: 1.045880
Train: [12800/60000 (21%)] Loss: 0.482751
Train: [19200/60000 (32%)] Loss: 0.486722
Train: [25600/60000 (43%)] Loss: 0.354835
Train: [32000/60000 (53%)] Loss: 0.192605
Train: [38400/60000 (64%)] Loss: 0.172775
Train: [44800/60000 (75%)] Loss: 0.121670
Train: [51200/60000 (85%)] Loss: 0.128894
Train: [57600/60000 (96%)] Loss: 0.177849
Test set: Average loss: 0.1605, Accuracy: 9497/10000 (95%)
很明显相同参数下的CNN网络优于简单的全连接网络,原因是CNN网络可以更好的挖掘图像中的信息,主要通过两种手段:卷积和池化。
5.打乱像素顺序再次在两个网络上训练和测试
# 这里解释一下 torch.randperm 函数,给定参数n,返回一个从0到n-1的随机整数排列
perm = torch.randperm(784)
plt.figure(figsize=(8, 4))
for i in range(10):
image, _ = train_loader.dataset.__getitem__(i)
# permute pixels
image_perm = image.view(-1, 28*28).clone()
image_perm = image_perm[:, perm]
image_perm = image_perm.view(-1, 1, 28, 28)
plt.subplot(4, 5, i + 1)
plt.imshow(image.squeeze().numpy(), 'gray')
plt.axis('off')
plt.subplot(4, 5, i + 11)
plt.imshow(image_perm.squeeze().numpy(), 'gray')
plt.axis('off')

重新定义训练与测试函数,我们写了两个函数 train_perm 和 test_perm,分别对应着加入像素打乱顺序的训练函数与测试函数。
与之前的训练与测试函数基本上完全相同,只是对 data 加入了打乱顺序操作。
# 对每个 batch 里的数据,打乱像素顺序的函数
def perm_pixel(data, perm):
# 转化为二维矩阵
data_new = data.view(-1, 28*28)
# 打乱像素顺序
data_new = data_new[:, perm]
# 恢复为原来4维的 tensor
data_new = data_new.view(-1, 1, 28, 28)
return data_new
# 训练函数
def train_perm(model, perm):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
# 像素打乱顺序
data = perm_pixel(data, perm)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 测试函数
def test_perm(model, perm):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
data, target = data.to(device), target.to(device)
# 像素打乱顺序
data = perm_pixel(data, perm)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
accuracy))
小型全连接网络:
perm = torch.randperm(784)
n_hidden = 8 # number of hidden units
model_fnn = FC2Layer(input_size, n_hidden, output_size)
model_fnn.to(device)
optimizer = optim.SGD(model_fnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_fnn)))
train_perm(model_fnn, perm)
test_perm(model_fnn, perm)
Number of parameters: 6442
Train: [0/60000 (0%)] Loss: 2.294211
Train: [6400/60000 (11%)] Loss: 1.820978
Train: [12800/60000 (21%)] Loss: 1.060106
Train: [19200/60000 (32%)] Loss: 0.781592
Train: [25600/60000 (43%)] Loss: 0.718575
Train: [32000/60000 (53%)] Loss: 0.595289
Train: [38400/60000 (64%)] Loss: 0.603694
Train: [44800/60000 (75%)] Loss: 0.590031
Train: [51200/60000 (85%)] Loss: 0.745443
Train: [57600/60000 (96%)] Loss: 0.731628
Test set: Average loss: 0.5092, Accuracy: 8448/10000 (84%)
CNN:
perm = torch.randperm(784)
n_features = 6 # number of feature maps
model_cnn = CNN(input_size, n_features, output_size)
model_cnn.to(device)
optimizer = optim.SGD(model_cnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_cnn)))
train_perm(model_cnn, perm)
test_perm(model_cnn, perm)
Number of parameters: 6422
Train: [0/60000 (0%)] Loss: 2.302913
Train: [6400/60000 (11%)] Loss: 2.259660
Train: [12800/60000 (21%)] Loss: 2.158767
Train: [19200/60000 (32%)] Loss: 1.658526
Train: [25600/60000 (43%)] Loss: 1.302927
Train: [32000/60000 (53%)] Loss: 1.099095
Train: [38400/60000 (64%)] Loss: 0.969859
Train: [44800/60000 (75%)] Loss: 0.835230
Train: [51200/60000 (85%)] Loss: 0.598763
Train: [57600/60000 (96%)] Loss: 0.552054
Test set: Average loss: 0.6426, Accuracy: 7941/10000 (79%)
小结:打乱像素顺序之后,小型全连接网络的性能上没有发生明显的变化,而CNN性能很明显的下降,这是因为CNN会利用像素的局部关系,但是打乱顺序之后,这些像素间的关系将无法被利用。
CIFAR10数据集分类
CIFAR10数据集包含十个类别:‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’,其中的图像大小为33232,也就是RGB的3层颜色通道,每层通道中的尺寸为32*32。

PyTorch 创建了一个叫做 totchvision 的包,该包含有支持加载类似Imagenet,CIFAR10,MNIST 等公共数据集的数据加载模块 torchvision.datasets 和支持加载图像数据数据转换模块 torch.utils.data.DataLoader。
首先,加载并归一化 CIFAR10 使用 torchvision 。torchvision 数据集的输出是范围在[0,1]之间的 PILImage,我们将他们转换成归一化范围为[-1,1]之间的张量 Tensors。
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 使用GPU训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# input[channel] = (input[channel] - mean[channel]) / std[channel]
# 注意下面代码中:训练的 shuffle 是 True,测试的 shuffle 是 false
# 训练时可以打乱顺序增加多样性,测试是没有必要
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=8,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
97%
165552128/170498071 [00:02<00:00, 81789133.73it/s]
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verified
CIFAR10中的一些图片:
def imshow(img):
plt.figure(figsize=(8,8))
img = img / 2 + 0.5 # 转换到 [0,1] 之间
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 得到一组图像
images, labels = iter(trainloader).next()
# 展示图像
imshow(torchvision.utils.make_grid(images))
# 展示第一行图像的标签
for j in range(8):
print(classes[labels[j]])

定义网络、损失函数和优化器:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 网络放到GPU上
net = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
训练网络:
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
Epoch: 1 Minibatch: 1 loss: 2.319
Epoch: 1 Minibatch: 101 loss: 1.739
Epoch: 1 Minibatch: 201 loss: 1.641
Epoch: 1 Minibatch: 301 loss: 1.571
Epoch: 1 Minibatch: 401 loss: 1.370
Epoch: 1 Minibatch: 501 loss: 1.565
Epoch: 1 Minibatch: 601 loss: 1.452
Epoch: 1 Minibatch: 701 loss: 1.448
Epoch: 2 Minibatch: 1 loss: 1.543
Epoch: 2 Minibatch: 101 loss: 1.447
Epoch: 2 Minibatch: 201 loss: 1.441
Epoch: 2 Minibatch: 301 loss: 1.320
Epoch: 2 Minibatch: 401 loss: 1.407
Epoch: 2 Minibatch: 501 loss: 1.245
Epoch: 2 Minibatch: 601 loss: 1.348
Epoch: 2 Minibatch: 701 loss: 1.199
Epoch: 3 Minibatch: 1 loss: 1.171
Epoch: 3 Minibatch: 101 loss: 1.180
Epoch: 3 Minibatch: 201 loss: 1.178
Epoch: 3 Minibatch: 301 loss: 1.251
Epoch: 3 Minibatch: 401 loss: 1.328
Epoch: 3 Minibatch: 501 loss: 1.357
Epoch: 3 Minibatch: 601 loss: 1.302
Epoch: 3 Minibatch: 701 loss: 1.203
Epoch: 4 Minibatch: 1 loss: 1.332
Epoch: 4 Minibatch: 101 loss: 1.207
Epoch: 4 Minibatch: 201 loss: 1.074
Epoch: 4 Minibatch: 301 loss: 1.312
Epoch: 4 Minibatch: 401 loss: 1.105
Epoch: 4 Minibatch: 501 loss: 0.974
Epoch: 4 Minibatch: 601 loss: 0.966
Epoch: 4 Minibatch: 701 loss: 1.284
Epoch: 5 Minibatch: 1 loss: 1.244
Epoch: 5 Minibatch: 101 loss: 1.175
Epoch: 5 Minibatch: 201 loss: 1.098
Epoch: 5 Minibatch: 301 loss: 1.008
Epoch: 5 Minibatch: 401 loss: 1.174
Epoch: 5 Minibatch: 501 loss: 1.090
Epoch: 5 Minibatch: 601 loss: 1.228
Epoch: 5 Minibatch: 701 loss: 1.377
Epoch: 6 Minibatch: 1 loss: 1.021
Epoch: 6 Minibatch: 101 loss: 0.756
Epoch: 6 Minibatch: 201 loss: 1.045
Epoch: 6 Minibatch: 301 loss: 1.175
Epoch: 6 Minibatch: 401 loss: 1.147
Epoch: 6 Minibatch: 501 loss: 1.155
Epoch: 6 Minibatch: 601 loss: 1.173
Epoch: 6 Minibatch: 701 loss: 1.143
Epoch: 7 Minibatch: 1 loss: 1.027
Epoch: 7 Minibatch: 101 loss: 1.187
Epoch: 7 Minibatch: 201 loss: 1.093
Epoch: 7 Minibatch: 301 loss: 0.758
Epoch: 7 Minibatch: 401 loss: 0.922
Epoch: 7 Minibatch: 501 loss: 1.218
Epoch: 7 Minibatch: 601 loss: 1.177
Epoch: 7 Minibatch: 701 loss: 0.895
Epoch: 8 Minibatch: 1 loss: 0.918
Epoch: 8 Minibatch: 101 loss: 0.902
Epoch: 8 Minibatch: 201 loss: 0.876
Epoch: 8 Minibatch: 301 loss: 0.927
Epoch: 8 Minibatch: 401 loss: 0.854
Epoch: 8 Minibatch: 501 loss: 1.201
Epoch: 8 Minibatch: 601 loss: 0.909
Epoch: 8 Minibatch: 701 loss: 1.001
Epoch: 9 Minibatch: 1 loss: 0.982
Epoch: 9 Minibatch: 101 loss: 1.132
Epoch: 9 Minibatch: 201 loss: 0.758
Epoch: 9 Minibatch: 301 loss: 0.896
Epoch: 9 Minibatch: 401 loss: 1.013
Epoch: 9 Minibatch: 501 loss: 1.014
Epoch: 9 Minibatch: 601 loss: 1.013
Epoch: 9 Minibatch: 701 loss: 0.965
Epoch: 10 Minibatch: 1 loss: 0.825
Epoch: 10 Minibatch: 101 loss: 0.971
Epoch: 10 Minibatch: 201 loss: 0.841
Epoch: 10 Minibatch: 301 loss: 0.870
Epoch: 10 Minibatch: 401 loss: 1.079
Epoch: 10 Minibatch: 501 loss: 0.831
Epoch: 10 Minibatch: 601 loss: 0.741
Epoch: 10 Minibatch: 701 loss: 1.007
Finished Training
从测试集里面取出8张图片:
# 得到一组图像
images, labels = iter(testloader).next()
# 展示图像
imshow(torchvision.utils.make_grid(images))
# 展示图像的标签
for j in range(8):
print(classes[labels[j]])

把图片输入模型,看CNN把图片识别成什么:
outputs = net(images.to(device))
_, predicted = torch.max(outputs, 1)
# 展示预测的结果
for j in range(8):
print(classes[predicted[j]])
cat
car
ship
ship
deer
frog
dog
frog
从结果中可以看出有几个识别错了
查看CNN在整个数据集上的表现:
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
Accuracy of the network on the 10000 test images: 63 %
准确率大概为63%
使用 VGG16 对 CIFAR10 分类
1.定义dataloader
CIFAR10是3x32x32的,所以transform定义是三通道的
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Files already downloaded and verified
Files already downloaded and verified
2.定义VGG网络
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M']
self.features = self._make_layers(self.cfg)
self.classifier = nn.Linear(2048, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
初始化网络,根据实际需要,修改分类层。因为 tiny-imagenet 是对200类图像分类,这里把输出修改为200。
# 网络放到GPU上
net = VGG().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
3.网络训练
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
Epoch: 1 Minibatch: 1 loss: 2.472
Epoch: 1 Minibatch: 101 loss: 1.387
Epoch: 1 Minibatch: 201 loss: 1.332
Epoch: 1 Minibatch: 301 loss: 1.125
Epoch: 2 Minibatch: 1 loss: 1.009
Epoch: 2 Minibatch: 101 loss: 1.108
Epoch: 2 Minibatch: 201 loss: 1.140
Epoch: 2 Minibatch: 301 loss: 1.039
Epoch: 3 Minibatch: 1 loss: 0.986
Epoch: 3 Minibatch: 101 loss: 0.879
Epoch: 3 Minibatch: 201 loss: 0.646
Epoch: 3 Minibatch: 301 loss: 0.586
Epoch: 4 Minibatch: 1 loss: 0.676
Epoch: 4 Minibatch: 101 loss: 0.757
Epoch: 4 Minibatch: 201 loss: 0.639
Epoch: 4 Minibatch: 301 loss: 0.713
Epoch: 5 Minibatch: 1 loss: 0.795
Epoch: 5 Minibatch: 101 loss: 0.746
Epoch: 5 Minibatch: 201 loss: 0.585
Epoch: 5 Minibatch: 301 loss: 0.686
Epoch: 6 Minibatch: 1 loss: 0.494
Epoch: 6 Minibatch: 101 loss: 0.556
Epoch: 6 Minibatch: 201 loss: 0.506
Epoch: 6 Minibatch: 301 loss: 0.596
Epoch: 7 Minibatch: 1 loss: 0.587
Epoch: 7 Minibatch: 101 loss: 0.421
Epoch: 7 Minibatch: 201 loss: 0.470
Epoch: 7 Minibatch: 301 loss: 0.473
Epoch: 8 Minibatch: 1 loss: 0.677
Epoch: 8 Minibatch: 101 loss: 0.560
Epoch: 8 Minibatch: 201 loss: 0.505
Epoch: 8 Minibatch: 301 loss: 0.493
Epoch: 9 Minibatch: 1 loss: 0.362
Epoch: 9 Minibatch: 101 loss: 0.425
Epoch: 9 Minibatch: 201 loss: 0.301
Epoch: 9 Minibatch: 301 loss: 0.340
Epoch: 10 Minibatch: 1 loss: 0.428
Epoch: 10 Minibatch: 101 loss: 0.368
Epoch: 10 Minibatch: 201 loss: 0.335
Epoch: 10 Minibatch: 301 loss: 0.396
Finished Training
4.测试正确率
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (
100 * correct / total))
Accuracy of the network on the 10000 test images: 84.48 %
使用VGG模型进行猫狗大战
import numpy as np
import matplotlib.pyplot as plt
import os
import torch
import torch.nn as nn
import torchvision
from torchvision import models,transforms,datasets
import time
import json
# 判断是否存在GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('Using gpu: %s ' % torch.cuda.is_available())
Using gpu: True
下载数据
! wget https://static.leiphone.com/cat_dog.rar
--2020-07-31 13:02:05-- https://static.leiphone.com/cat_dog.rar
Resolving static.leiphone.com (static.leiphone.com)... 47.246.24.229, 47.246.24.227, 47.246.24.228, ...
Connecting to static.leiphone.com (static.leiphone.com)|47.246.24.229|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 546904884 (522M) [application/x-rar-compressed]
Saving to: ‘cat_dog.rar’
cat_dog.rar 100%[===================>] 521.57M 19.4MB/s in 28s
2020-07-31 13:02:33 (18.9 MB/s) - ‘cat_dog.rar’ saved [546904884/546904884]
因为AI研习社提供的数据集是rar,所以需要安装rarfile库
pip install rarfile
Collecting rarfile
Downloading https://files.pythonhosted.org/packages/59/66/d2a475dce12051fa93d80c07cb1aea663e6ab15afc2c2973ab53cd14a0f0/rarfile-3.3.tar.gz (135kB)
|████████████████████████████████| 143kB 3.5MB/s
Building wheels for collected packages: rarfile
Building wheel for rarfile (setup.py) ... done
Created wheel for rarfile: filename=rarfile-3.3-py2.py3-none-any.whl size=24969 sha256=9076dc220e263686553095f5e2106dd924e55817a70bbf7dc9d4d3a7349b89d2
Stored in directory: /root/.cache/pip/wheels/77/9b/af/37bc95a3007ad325d678785dc65f6ee48bba34ecf0019cf9be
Successfully built rarfile
Installing collected packages: rarfile
Successfully installed rarfile-3.3
解压cat_dog文件
import rarfile
path = "cat_dog.rar"
path2 = "/content/"
rf = rarfile.RarFile(path)
rf.extractall(path2)
数据处理
datasets 是 torchvision 中的一个包,可以用做加载图像数据。它可以以多线程(multi-thread)的形式从硬盘中读取数据,使用 mini-batch 的形式,在网络训练中向 GPU 输送。在使用CNN处理图像时,需要进行预处理。图片将被整理成 的大小,同时还将进行归一化处理。torchvision 支持对输入数据进行一些复杂的预处理/变换 (normalization, cropping, flipping, jittering 等)。
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
vgg_format = transforms.Compose([
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
data_dir = './cat_dog/'
dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format)
for x in ['train', 'valid']}
dset_sizes = {x: len(dsets[x]) for x in ['train', 'valid']}
dset_classes = dsets['train'].classes
直接运行代码发现报错
Found 0 files in subfolders of: ./cat_dog/train
Supported extensions are: .jpg,.jpeg,.png,.ppm,.bmp,.pgm,.tif,.tiff,.webp
搜索之后线下载该数据集的文件存储结构跟Pytorch的规范格式不一致,所以要进行预处理
mkdir cat_dog/val/Dog
mkdir cat_dog/val/Cat
mkdir cat_dog/train/Cat
mkdir cat_dog/train/Dog
mkdir cat_dog/test/test
mv cat_dog/val/dog* cat_dog/val/Dog/
mv cat_dog/val/cat* cat_dog/val/Cat/
mv cat_dog/train/cat* cat_dog/train/Cat/
mv cat_dog/train/dog* cat_dog/train/Dog/
mv cat_dog/test/*.jpg cat_dog/test/test
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
vgg_format_train = transforms.Compose([
transforms.RandomRotation(30),# 随机旋转
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
vgg_format = transforms.Compose([
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
data_dir = './cat_dog/'
# 利用ImageFolder进行分类文件夹加载
# 两种加载数据集的方法
dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format)
for x in ['train', 'val']}
tsets = {y: datasets.ImageFolder(os.path.join(data_dir, y), vgg_format)
for y in ['test']}
dset_classes = dsets['train'].classes
dset_sizes = {x: len(dsets[x]) for x in ['train', 'val']}
# 通过下面代码可以查看 dsets 的一些属性
print(dsets['train'].classes)
print(dsets['train'].class_to_idx)
print(dsets['train'].imgs[:5])
print('dset_sizes: ', dset_sizes)
['Cat', 'Dog']
{'Cat': 0, 'Dog': 1}
[('./cat_dog/train/Cat/cat_0.jpg', 0), ('./cat_dog/train/Cat/cat_1.jpg', 0), ('./cat_dog/train/Cat/cat_10.jpg', 0), ('./cat_dog/train/Cat/cat_100.jpg', 0), ('./cat_dog/train/Cat/cat_1000.jpg', 0)]
dset_sizes: {'train': 20000, 'val': 2000}
loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=6)
loader_valid = torch.utils.data.DataLoader(dsets['val'], batch_size=5, shuffle=False, num_workers=6)
loader_test = torch.utils.data.DataLoader(tsets['test'],batch_size=5,shuffle=False,num_workers=6)
'''
valid 数据一共有2000张图,每个batch是5张,因此,下面进行遍历一共会输出到 400
同时,把第一个 batch 保存到 inputs_try, labels_try,分别查看
'''
count = 1
for data in loader_valid:
#print(count, end='\n')
if count == 1:
inputs_try,labels_try = data
count +=1
print(labels_try)
print(inputs_try.shape)
tensor([0, 0, 0, 0, 0])
torch.Size([5, 3, 224, 224])
# 显示图片的小程序
def imshow(inp, title=None):
# Imshow for Tensor.
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = np.clip(std * inp + mean, 0,1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# 显示 labels_try 的5张图片,即valid里第一个batch的5张图片
out = torchvision.utils.make_grid(inputs_try)
imshow(out, title=[dset_classes[x] for x in labels_try])

创建VGG Model
torchvision中集成了很多在 ImageNet (120万张训练数据) 上预训练好的通用的CNN模型,可以直接下载使用。
在本课程中,我们直接使用预训练好的 VGG 模型。同时,为了展示 VGG 模型对本数据的预测结果,还下载了 ImageNet 1000 个类的 JSON 文件。
在这部分代码中,对输入的5个图片利用VGG模型进行预测,同时,使用softmax对结果进行处理,随后展示了识别结果。可以看到,识别结果是比较非常准确的。
!wget https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
--2020-07-31 13:46:34-- https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
Resolving s3.amazonaws.com (s3.amazonaws.com)... 54.231.49.164
Connecting to s3.amazonaws.com (s3.amazonaws.com)|54.231.49.164|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 35363 (35K) [application/octet-stream]
Saving to: ‘imagenet_class_index.json’
imagenet_class_inde 100%[===================>] 34.53K --.-KB/s in 0.03s
2020-07-31 13:46:34 (1.17 MB/s) - ‘imagenet_class_index.json’ saved [35363/35363]
model_vgg = models.vgg16(pretrained=True)
with open('./imagenet_class_index.json') as f:
class_dict = json.load(f)
dic_imagenet = [class_dict[str(i)][1] for i in range(len(class_dict))]
inputs_try , labels_try = inputs_try.to(device), labels_try.to(device)
model_vgg = model_vgg.to(device)
outputs_try = model_vgg(inputs_try)
#print(outputs_try)
#print(outputs_try.shape)
#tensor([[-4.6803, -3.0721, -4.2074, ..., -8.1783, -1.4379, 5.2827],
# [-2.4916, -3.3212, 1.3284, ..., -4.5295, -0.9055, 4.1661],
# [-1.4204, -0.0192, -2.6073, ..., -0.2028, 3.1158, 3.8306],
# [-4.0369, -2.0386, -2.7258, ..., -5.3328, 4.3880, 1.6959],
# [-1.8230, 4.3508, -3.3690, ..., -2.3910, 3.7018, 5.3185]],
# device='cuda:0', grad_fn=)
#torch.Size([5, 1000])
'''
可以看到结果为5行,1000列的数据,每一列代表对每一种目标识别的结果。
但是我也可以观察到,结果非常奇葩,有负数,有正数,
为了将VGG网络输出的结果转化为对每一类的预测概率,我们把结果输入到 Softmax 函数
'''
m_softm = nn.Softmax(dim=1)
probs = m_softm(outputs_try)
vals_try,pred_try = torch.max(probs,dim=1)
#print( 'prob sum: ', torch.sum(probs,1))
#prob sum: tensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000], device='cuda:0',
# grad_fn=)
#print( 'vals_try: ', vals_try)
#vals_try: tensor([0.9112, 0.2689, 0.4477, 0.5912, 0.4615], device='cuda:0',
# grad_fn=)
#print( 'pred_try: ', pred_try)
#pred_try: tensor([223, 223, 282, 285, 282], device='cuda:0')
print([dic_imagenet[i] for i in pred_try.data])
imshow(torchvision.utils.make_grid(inputs_try.data.cpu()),
title=[dset_classes[x] for x in labels_try.data.cpu()])

由此可见,VGG很强大可以识别猫的品种
修改最后一层,冻结前面层的参数
我们的目标是使用预训练好的模型,因此,需要把最后的 nn.Linear 层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置 required_grad=False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。
print(model_vgg)
model_vgg_new = model_vgg;
for param in model_vgg_new.parameters():
param.requires_grad = False
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2)
model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1)
model_vgg_new = model_vgg_new.to(device)
print(model_vgg_new.classifier)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=2, bias=True)
(7): LogSoftmax()
)
)
Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=2, bias=True)
(7): LogSoftmax()
)
训练并测试全连接层
Adam更加准确
'''
第一步:创建损失函数和优化器
损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签.
它不会为我们计算对数概率,适合最后一层是log_softmax()的网络.
'''
criterion = nn.NLLLoss()
# 学习率
lr = 0.001
# 随机梯度下降
#optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = lr)
optimizer_vgg = torch.optim.Adam(model_vgg_new.classifier[6].parameters(),lr = lr)
'''
第二步:训练模型
'''
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
print('Training: No. ', count, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
# 模型训练
train_model(model_vgg_new,loader_train,size=dset_sizes['train'], epochs=1,
optimizer=optimizer_vgg)
Loss: 0.0024 Acc: 0.9518
def test_model(model,dataloader,size):
model.eval()
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size,2))
i = 0
running_loss = 0.0
running_corrects = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
predictions[i:i+len(classes)] = preds.to('cpu').numpy()
all_classes[i:i+len(classes)] = classes.to('cpu').numpy()
all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy()
i += len(classes)
print('Testing: No. ', i, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
return predictions, all_proba, all_classes
# 测试网络(valid)
predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['val'])
Loss: 0.0179 Acc: 0.9735