Handler全家桶之 —— Handler 源码解析

今日科技快讯
昨日,第三方支付公司拉卡拉正式在深交所挂牌上市,上市价33.28元,开盘价39.94元,涨幅20.01%,总发行量4001万股。以开盘价计算,拉卡拉总市值达到159.76亿元。
作者简介
明天休息一天,提前祝大家周六愉快!
本篇文章来自 鸡汤程序员 的投稿,深入分析了Handler,希望对大家有所帮助!
鸡汤程序员 的博客地址:
https://www.jianshu.com/u/3f3c4485b55a
前言
这是一个系列文章,将会包括:
Handler全家桶之 —— Handler 源码解析
Handler全家桶之 —— HandlerThread & IntentService 源码解析
Handler全家桶之 —— AsyncTask 源码解析
Handler全家桶之 —— View.post() 源码解析
Handler 是 Android 开发中举足轻重的一种线程机制,很多地方,包括 Android 源码都不少地方用到了这个。
这篇文章将会从源码角度分析 Handler 机制以及一些常见的疑惑点。
作用
Handler 是一种用于线程间的消息传递机制。
因为 Android 中不允许在非主线程更新UI,所以最常使用的地方就是用于子线程获取某些数据后进行UI的更新。
基本用法
step1:创建Handler实例
//1.自定义Handler类
static class CustomHandler extends Handler{
@Override
public void handleMessage(Message msg) {
//更新UI等操作
}
}
CustomHandler customHandler = new CustomHandler();
//2.内部类
Handler innerHandler = new Handler(){
@Override
public void handleMessage(Message msg) {
//更新UI等操作
}
};
//3.callback方式
Handler callbackHandler = new Handler(new Handler.Callback() {
@Override
public boolean handleMessage(Message msg) {
//更新UI等操作
return true;
}
});
step2:发送消息
//1.发送普通消息
Message msg = Message.obtain();
msg.what = 0; //标识
msg.obj = "这是消息体"; //消息内容
innerHandler.sendMessage(msg);
//2.发送Runnale消息
innerHandler.post(new Runnable() {
@Override
public void run() {
//更新UI等操作,消息接收后执行此方法
}
});
Handler 的创建以及消息的发送都有很多种方法,各种方式的异同会在下面讲到。
源码分析
带着问题看源码 —— 鲁某
ps:本文源码基于 API 28 ,即 Android P / Android 9
先抛出我们的第一个问题:
3.1 为什么 Handler 能够切换线程执行?
我们在发送 Message 的时候在子线程,为什么执行的时候就切换成了主线程?想要知道答案,基本就要把 Handler 的运行流程给了解一遍。
因为最终的处理是在 handleMessage方法中进行的,所以我们看看 handleMessage方法是怎么被调用起来的。
先打个 debug , 看看调用链:

画个图直观一点:

可能有点奇怪,整个调用流程都没有出现我们发送消息的方法,那我们发送的 Message 对象在哪里被使用了呢?
看下上图的 Step 2 ,在 loop() 方法里面调用了 msg.target.dispatchMessage(msg) 方法,debug 中查看 msg 对象的属性,发现这个 msg 正是我们发送的那个 Message对象,这个 target 就是在 MainActivity 中创建的 Handler 对象。
也就是说,我们发送消息后,不知道什么原因,Looper.loop() 方法内会拿到我们发送的消息,并且最终会调用发送该消息的 Handler 的 handleMessage(Message msg)方法。先看看 loop() 方法是怎么拿到我们的 Message 的:
// Looper.java ,省略部分代码
loop(){
final Looper me = myLooper();
if (me == null) {
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
final MessageQueue queue = me.mQueue;
for (;;) {
Message msg = queue.next(); // might block , 从队列取出一个msg
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
msg.target.dispatchMessage(msg); //Handler处理消息
msg.recycleUnchecked(); //回收msg
}
}
首先,loop()方法会判断当前线程是否已经调用了 Looper.prepare(),如果没有,则抛异常,这就是我们创建非主线程的 Handler 为什么要调用Looper.prepare()的原因。而主线程中会在上面流程图的 Step 1 中,即 ActivityThread.main() 方法里面调用了 prepare 方法,所以我们创建默认(主线程)的 Handler 不需要额外创建 Looper 。
loop() 里面是一个死循环,只有当msg为空时才退出该方法。msg 是从 queue.next 中取出来的,这个 queue 就是我们经常听到的消息队列了(MessageQueue ),看看 next 方法的实现:
//MessageQueue.java ,删减部分代码
Message next() {
final long ptr = mPtr;
if (ptr == 0) {
//如果队列已经停止了(quit or dispose)
return null;
}
for (;;) {
synchronized (this) {
final long now = SystemClock.uptimeMillis(); //获取当前时间
Message prevMsg = null;
Message msg = mMessages;
if (msg != null && msg.target == null) {
//msg == target 的情况只能是屏障消息,即调用postSyncBarrier()方法
//如果存在屏障,停止同步消息,异步消息还可以执行
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous()); //找出异步消息,如果有的话
}
if (msg != null) {
if (now < msg.when) {
//当前消息还没准备好(时间没到)
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// 消息已准备,可以取出
if (prevMsg != null) {
//有屏障,prevMsg 为异步消息 msg 的前一节点,相当于拿出 msg ,链接前后节点
prevMsg.next = msg.next;
} else {
//没有屏障,msg 即头节点,将 mMessages 设为新的头结点
mMessages = msg.next;
}
msg.next = null; //断开即将执行的 msg
msg.markInUse(); //标记为使用状态
return msg; //返回取出的消息,交给Looper处理
}
}
// Process the quit message now that all pending messages have been ha
if (mQuitting) {
//队列已经退出
dispose();
return null; //返回null后Looper.loop()方法也会结束循环
}
}
}
源码中可以发现,虽然 MessageQueue 叫消息队列,但却是使用了链表的数据结构来存储消息。 next()方法会从链表的头结点开始,先看看头结点是不是消息屏障(ViewRootImpl使用了这个机制),如果是,那么就停止同步消息的读取,异步消息照常运作。
如果有消息,还会判断是否到了消息的使用时间,比如我们发送了延时消息,这个消息不会马上调用,而是继续循环等待,直到消息可用。这里就有一个新的问题2:为什么 next()中一直循环却不会导致应用卡死?这个问题等下再说。
到这里,我们就大致能理清 Handler.handleMessage()方法是怎么调起来的了。但是MessageQueue里面的消息是怎么来的呢?这个其实不看源码也能猜出来了,肯定是由我们发送的消息那里传过来的,但是为了理解更深刻,还是得看看消息是怎么传递到消息队列中的(MessageQueue );
//Handler.java
public final boolean sendMessage(Message msg){
return sendMessageDelayed(msg, 0);
}
public final boolean sendMessageDelayed(Message msg, long delayMillis){
if (delayMillis < 0) {
delayMillis = 0;
}
return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);
}
public boolean sendMessageAtTime(Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
if (queue == null) {
RuntimeException e = new RuntimeException(
this + " sendMessageAtTime() called with no mQueue");
Log.w("Looper", e.getMessage(), e);
return false;
}
return enqueueMessage(queue, msg, uptimeMillis);
}
可以看到,sendMessage()方法最终是调用了 sendMessageAtTime()方法,分析下这个方法,首先将会拿到一个消息队列 mQueue,这个队列是在创建 Looper的时候默认初始化的,然后会调用enqueueMessage()方法进队:
//Handler.java
private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {
msg.target = this;
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}
这个进队方法里面会将msg.target设为当前Handler,也就是上面说到的 Looper.loop()方法内最终调用的msg.target.dispatchMessage(msg)的这个 msg 的 target 来源。
如果当前 Handler 是异步的话,还会将发送的消息置为同步消息,这个 mAsynchronous 标识是我们构造 Handler 的时候传递的参数,默认为 false。
最后就是真正的进队方法 MessageQueue.enqueueMessage :
//MessageQueue.java 删减部分代码
boolean enqueueMessage(Message msg, long when) {
if (msg.target == null) {
throw new IllegalArgumentException("Message must have a target.");
}
if (msg.isInUse()) {
throw new IllegalStateException(msg + " This message is already in use.");
}
synchronized (this) {
if (mQuitting) {
msg.recycle();
return false;
}
msg.markInUse();
msg.when = when; //赋值调用时间
Message p = mMessages; //头结点
if (p == null || when == 0 || when < p.when) {
//队列中没有消息 或者 时间为0 或者 比头结点的时间早
//插入到头结点中
msg.next = p;
mMessages = msg;
} else {
Message prev;
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) { //类似插入排序,找到合适的位置
break;
}
}
// 结点插入
msg.next = p;
prev.next = msg;
}
}
return true;
}
刚开始会进行一系列的判断,然后根据时间来作为一个排队依据进行进队操作,需要注意的是:消息队列是使用链表作为数据的存储结构,是可以插队的,即不存在发送了延时消息不会阻塞消息队列。
再跟上面的出队方法联系起来,就会发现,异步消息并不会立刻执行,而是根据时间,完全跟同步消息一样的顺序插入队列中。异步消息与同步消息唯一的区别就是当有消息屏障时,异步消息还可以执行,而同步消息则不行。
整个Handler的大体运行机制到此应该有了一个比较清晰的轮廓了。
总结一下:Handler 发送的线程不处理消息,只有Looper.loop()将消息取出来后再进行处理,所以在Handler机制中,无论发送消息的Handler对象处于什么线程,最终的处理都是运行在 Looper.loop() 所在的线程。
比如:一个新的线程 Thread1 发送了一个消息 Msg1,这个线程的工作仅仅是将消息存储到消息队列而已,并没有下一步了,然后等待 Looper.loop() 处理到 Msg1 的时候(loop()方法一直运行在最开始调用它的线程,比如主线程),再将 Msg1 进行处理,所以最终就从 Thread1 切换到了主线程中运行。
可以拉到下面3.7小节看下流程图,更清晰一些
3.2 Handler.post(Runnable) 方法是运行在新的线程吗?
Handler 中发送消息的方法多达十几个,分为 sendXXX 以及 postXXX ,这里看看主要的几个 post 类型方法:
//Handler.java
public final boolean post(Runnable r){
return sendMessageDelayed(getPostMessage(r), 0);
}
public final boolean postAtTime(Runnable r, long uptimeMillis){
return sendMessageAtTime(getPostMessage(r), uptimeMillis);
}
...
几个 post 方法都是调用了相应的sendXXX 方法,然后用getPostMessage(Runnable r) 构建 Message 对象:
private static Message getPostMessage(Runnable r) {
Message m = Message.obtain();
m.callback = r;
return m;
}
这里获取到消息后,将 Runnable赋值给 Message.callback ,那这个 callback 有什么用呢?上面的整体流程分析中,我们知道 Looper.loop()会调用 msg.target.dispatchMessage(msg),这个target 就是 Handler 了,那么看一下这个方法的具体实现:
// Handler.java
public void dispatchMessage(Message msg) {
if (msg.callback != null) {
handleCallback(msg);
} else {
if (mCallback != null) {
if (mCallback.handleMessage(msg)) {
return;
}
}
handleMessage(msg);
}
}
private static void handleCallback(Message message) {
message.callback.run();
}
到这一步终于水落石出了,如果是用 postXXX 方法发送的消息,就会调用 handleCallback(msg) 方法,即调用我们post方法里传递的 Runnable 对象的run()方法。
也就是说,Runnable 跟线程没有半毛钱关系,他只是一个回调方法而已,只不过我们平时创建线程的时候使用多了,误以为他跟线程有什么py交易。
3.3 Handler(Callback) 跟 Handler() 这两个构造方法的区别在哪?
接着看3.2讲到的 dispatchMessage() 方法剩下的逻辑。
如果 msg 没有 callback 的话,那么将会判断 mCallback 是否为空,这个 mCallback 就是构造方法种传递的那个 Callback ,如果 mCallback为空,那么就调用 Handler 的 handleMessage(msg) 方法,否则就调用 mCallback.handleMessage(msg) 方法,然后根据 mCallback.handleMessage(msg)的返回值判断是否拦截消息,如果拦截(返回 true),则结束,否则还会调用 Handler#handleMessage(msg)方法。
也就是说:Callback.handleMessage() 的优先级比 Handler.handleMessage()要高 。如果存在Callback,并且Callback#handleMessage() 返回了 true ,那么Handler#handleMessage()将不会调用。
除了这点,还有什么区别吗?暂时真没发现。
3.4 子线程可以创建 Handler 吗?
问题可能有些模糊,意思是可以在子线程回调 handleMessage()吗。
上面理清了 Handler 的运行流程,但是创建流程好像还没怎么说,先看看 Handler 是怎么创建的:
public Handler() {
this(null, false);
}
public Handler(Callback callback) {
this(callback, false);
}
public Handler(boolean async) {
this(null, async);
}
public Handler(Callback callback, boolean async) {
if (FIND_POTENTIAL_LEAKS) {
final Class klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}
mLooper = Looper.myLooper();
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread " + Thread.currentThread()
+ " that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
先看上面这部分不传 Looper 的构造方法,这些方法最终都是调用了Handler(Callback callback, boolean async) 方法,所以直接看这个方法就行,一开始会在方法体内检测是否有潜在的内存泄漏风险,相信大家都有过被这东西烦过,看图:
这种被黄色支配的感觉不太舒服,可以在实例上面添加注解@SuppressLint("HandlerLeak")来去掉提示,但是这只是去掉提示而已,别忘了处理潜在的内存泄漏。
接着看下面,首先会调用 Looper.myLooper()方法拿到当前线程的 Looper 实例,如果为空,则抛异常,看看myLooper()具体是怎样的:
//Looper.java
public static @Nullable Looper myLooper() {
return sThreadLocal.get();
}
直接就是调用了 sThreadLocal的 get 方法,这个sThreadLocal是一个静态的 ThreadLocal 常量,看名字就能猜到与线程相关,具体的就不深究了。可以先把他看成一个线程id 与 Looper 的 map 键值对。既然有 get() ,那么就应该有 set() ,那么 Looper 是在哪里被存进去的呢?
//Looper.java
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
原来是在 Looper.prepare() 方法中被传进去的,并且 sThreadLocal 中每个线程都只能有一个 Looper 实例。需要注意的是,prepare()方法并没有调用 Looper#loop()方法,经过上面的流程分析也知道,这个 loop() 方法启动才能处理发送的消息,所以子线程创建 Handler 除了需要调用 Looper.prepare()外,还需要调用 Looper.loop()启动。
也就说明,任何线程都可以创建 Handler,只要当前线程调用了 Looper.prepare()方法,那么就可以使用 Handler 了,而且同一线程内就算创建 n 个 Handler 实例,也只对应一个 Looper,即对应一个消息队列。
理一理逻辑:Handler 机制要求创建 Handler 的线程必须先调用 Looper.prepare() 方法来初始化,初始化过程中会将当前线程的 Looper 存起来,如果没有进行 Looper 的初始化,将会抛异常,要启动 Looper ,还需要调用 loop() 方法。
3.5 为什么主线程不用调用 Looper.prepare() ?
上面说了,每个线程要创建 Handler 就必须要调用 Looper.prepare进行初始化,那么为什么我们平时在主线程创建 Handler 则不需要调用?
通过3.1 中的 debug 调用链就可以知道,主线程的 loop()方法是在 ActivityThread#main()方法中被调用的,那么看看 main() 方法:
//ActivityThread.java 删减部分代码
public static void main(String[] args) {
Looper.prepareMainLooper();
Looper.loop();
}
到这里就能明白了,在App启动的时候系统默认启动了一个主线程的 Looper,prepareMainLooper()也是调用了 prepare()方法,里面会创建一个不可退出的 Looper,并 set 到 sThreadLocal对象当中。
3.6 为什么创建 Message 对象推荐使用 Message.obtain()获取?
Message 对象有两种方式可以获得,一种是直接 new 一个实例,另一种就是调用 Message.obtain()方法了,Handler.obtainMessage() 也是调用Message.obtain()实现的,看看这个方法:
//Message.java
private static Message sPool;
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
sPool = m.next;
m.next = null;
m.flags = 0; // clear in-use flag
sPoolSize--;
return m;
}
}
return new Message();
}
可以看到,obtain() 方法会在以 sPool作为头结点的消息池(链表)中遍历,如果找到,那么取出来,并置为非使用状态,然后返回,如果消息池为空,则新建一个消息。
知道有消息池这个东西了,那么这个消息池的消息是怎么来的呢?
使用 AS 搜索一下,发现只有两个方法对 sPool 这个节点进行了赋值,一个是上面的 obtain(),另一个是下面这个:
//Message.java
private static final int MAX_POOL_SIZE = 50;
void recycleUnchecked() {
// Mark the message as in use while it remains in the recycled object pool.
// Clear out all other details.
flags = FLAG_IN_USE;
what = 0;
arg1 = 0;
arg2 = 0;
obj = null;
replyTo = null;
sendingUid = -1;
when = 0;
target = null;
callback = null;
data = null;
synchronized (sPoolSync) {
if (sPoolSize < MAX_POOL_SIZE) {
next = sPool;
sPool = this;
sPoolSize++;
}
}
}
看方法名也可以知道,这是一个回收的方法,方法体内将 Message 对象的各种参数清空,如果消息池的数量小于最大数量(50)的话,就当前消息插入缓存池的头结点中。
已经知道 Message 是会被回收的了,那么什么情况才会被回收呢?
继续查看调用链:
// Looper.java ,省略部分代码
loop(){
final MessageQueue queue = me.mQueue;
for (;;) {
Message msg = queue.next(); // might block , 从队列取出一个msg
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
msg.target.dispatchMessage(msg); //Handler处理消息
...
msg.recycleUnchecked(); //回收msg
}
}
其中的一个调用是在 Looper.loop()方法中,调用时机是在 Handler 处理事件之后,既然是 Handler 处理后就会回收,那么如果在 Handler.handleMessage() 中用新的线程使用这个 msg 会怎样呢?
//MainActivity.java
@SuppressLint("HandlerLeak")
static Handler innerHandler = new Handler() {
@Override
public void handleMessage(final Message msg) {
new Thread(new Runnable() {
@Override
public void run() {
boolean isRecycle = msg.obj == null;
Log.e("====是否已经回收===", "" + isRecycle);
}
}).start();
}
};
private void send(){
Message msg = Message.obtain();
msg.what = 0; //标识
msg.obj = "这是消息体"; //消息内容
innerHandler.sendMessage(msg);
}
当调用 send()方法发送消息后,发现打出 log:
E/====是否已经回收===: true
也就说明我们的推断是正确的。所以在平时使用中,不要在 handleMessage(Message msg)方法中对 msg 进行异步处理,因为异步处理后,该方法会马上返回,相当于告诉 Looper 已经处理完成了,Looper 就会将其回收。
如果真要在异步中使用,那么可以创建一个新的 Message 对象,并将值赋值过去。
回到前面的问题,我们目前发现了一个 Message 被回收的地方,那么其他地方有调用这个 Message .recycleUnchecked() 吗?接着看看:
//Message.java
public void recycle() {
if (isInUse()) {
if (gCheckRecycle) {
throw new IllegalStateException("This message cannot be recycled because it "
+ "is still in use.");
}
return;
}
recycleUnchecked();
}
Message 还有一个公共的回收方法,就是上面这个了,我们可以手动调用这个进行回收。还有就是消息队列中各种 removeMessage 也会触发回收,调用链太多了,就不贴代码了。
总而言之,因为 Handler 机制在整个 Android 系统中使用太频繁,所以 Android 就采用了一个缓存策略。就是 Message 里面会缓存一个静态的消息池,当消息被处理或者移除的时候就会被回收到消息池,所以推荐使用 Message.obtain()来获取消息对象。
3.7 梳理
到此就把Handler的大致流程分析完了,再画个图重新梳理一下思路:
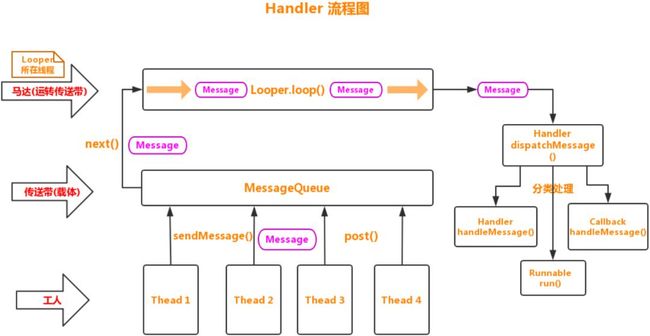
把整个Handler机制比作一个流水线的话,那么 Handler 就是工人,可以在不同线程传递 Message到传送带(MessageQueue),而传送带是被马达(Looper)运输的,马达又是一开始就运行了(Looper.loop()),并且只会在一开始的线程,所以无论哪个工人(Handler)在哪里(任意线程)传递产品(Message),都只会在一条传送带(MessageQueue)上被唯一的马达(Looper)运送到终点处理,即 Message 只会在调用 Looper.loop() 的线程被处理。
常见问题&技巧
4.1 为什么 Handler 会造成内存泄漏?
先来回顾下基础知识,可能造成内存泄漏的原因可以大致概括如下:
生命周期长的对象引用了生命周期短的对象。
Handler 跟其他一些类一样,本身是不会造成内存泄漏的,Handler 造成内存泄漏的一般原因都是由于匿名内部类引起的,因为匿名内部类隐性地持有外部类的引用(如果不持有引用怎么可以使用外部类的变量方法呢?)。
所以当内部类的生命周期比较长,如跑一个新的线程,碰巧又碰到生命周期短的对象(如Activity)需要回收,就会导致生命周期短的对象还在被生命周期长的对象所引用,进而回收不了。
典型的例子:
public class Main {
int _10m = 10*1024*1024;
byte[] bytes = new byte[4*_10m];
public void run() {
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(100*1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
public static void main(String args[]) {
Main object = new Main();
object.run();
object =null;
System.gc();
}
}
输出log:
[GC (System.gc()) [PSYoungGen: 3341K->880K(38400K)] 44301K->41848K(125952K)
[Full GC (System.gc()) [PSYoungGen: 880K->0K(38400K)] [ParOldGen: 40968K->41697K(87552K)] 41848K->41697K(125952K)
可以看到,即使object引用为空,object 对象还是没有被回收。这就会发生了内存泄漏,如果出现很多次这样的情况,那么就很有可能发生内存溢出(OutOfMemery)。
在 Handler 里面其实是类似的道理,匿名内部类的 Handler 持有 Activity 的引用,而发送的 Message 又持有 Handler 的引用,Message 又存在于 MessageQueue 中,而 MessageQueue 又是 Looper 的成员变量,并且 Looper 对象又是存在于静态常量 sThreadLocal 中。
所以反推回来,因为 sThreadLocal 是方法区常量,所以不会被回收,而 sThreadLocal 又持有 Looper 的引用...balabala...还是看图吧:

即 sThreadLocal 间接的持有了 Activity 的引用,当 Handler 发送的消息还没有被处理完毕时,比如延时消息,而 Activity 又被用户返回了,即 onDestroy() 后,系统想要对 Activity 对象进行回收,但是发现还有引用链存在,回收不了,就造成了内存泄漏。
4.2 怎么防止 Handler 内存泄漏?
从上面的分析中,可以知道,想要防止 Handler 内存泄漏,一种方法是把 sThreadLocal 到 Activity 的引用链断开就行了。
最简单的方法就是在 onPause()中使用 Handler 的 removeCallbacksAndMessages(null)方法清除所有消息及回调。就可以把引用链断开了。
Android 源码中这种方式也很常见,不在 onDestroy()里面调用主要是 onDestroy() 方法不能保证每次都能执行到。
第二种方法就是使用静态类加弱引用的方式:
public class MainActivity extends AppCompatActivity {
public TextView textView;
static class WeakRefHandler extends Handler {
//弱引用
private WeakReference reference;
public WeakRefHandler(MainActivity mainActivity) {
this.reference = new WeakReference(mainActivity);
}
@Override
public void handleMessage(Message msg) {
MainActivity activity = reference.get();
if (activity != null) {
activity.textView.setText("鸡汤程序员");
}
}
}
}
因为静态类不会持有外部类的引用,所以需要传一个 Activity 过来,并且使用一个弱引用来引用 Activity 的实例,弱引用在 gc 的时候会被回收,所以也就相当于把强引用链给断了,自然也就没有内存泄漏了。
4.3 Loop.loop() 为什么不会造成应用卡死?
上面也提了这个问题,按照一般的想法来说,loop() 方法是一个死循环,那么肯定会占用大量的 cpu 而导致应用卡顿,甚至说 ANR 。
但是 Android 中即使使用大量的 Looper ,也不会造成这种问题,问什么呢?
由于这个问题涉及到的知识比较深,主要是通过 Linux 的 epoll 机制实现的,这里需要 Linux 、 jni 等知识,我等菜鸟就不分析了,推荐一些相关文章:
Android中为什么主线程不会因为Looper.loop()里的死循环卡死?
https://www.zhihu.com/question/34652589
深入理解 MessageQueue
https://pqpo.me/2017/05/03/learn-messagequeue
总结
以上就是篇文章的全部分析了,这里总结一下:
1. Handler 的回调方法是在 Looper.loop()所调用的线程进行的;
2. Handler 的创建需要先调用 Looper.prepare() ,然后再手动调用 loop()方法开启循环;
3. App 启动时会在ActivityThread.main()方法中创建主线程的 Looper ,并开启循环,所以主线程使用 Handler 不用调用第2点的逻辑;
4. 延时消息并不会阻塞消息队列;
5. 异步消息不会马上执行,插入队列的方式跟同步消息一样,唯一的区别是当有消息屏障时,异步消息可以继续执行,同步消息则不行;
6. Callback.handleMessage() 的优先级比 Handler.handleMessage()要高*
7. Handler.post(Runnable)传递的 Runnale 对象并不会在新的线程执行;
8. Message 的创建推荐使用 Message.obtain() 来获取,内部采用缓存消息池实现;
9. 不要在 handleMessage()中对消息进行异步处理;
10. 可以通过removeCallbacksAndMessages(null)或者静态类加弱引用的方式防止内存泄漏;
11. Looper.loop()不会造成应用卡死,里面使用了 Linux 的 epoll 机制。
推荐阅读:
像小红书一样的图片裁剪控件联动效果
使用Google开源库AutoService进行组件化开发
让你直呼666的仿Excel表格效果
欢迎关注我的公众号,学习技术或投稿


长按上图,识别图中二维码即可关注