代码质量保证体系(上)
比尔·盖茨说:“用代码行数来衡量编程的进度,就如同用航空器零件的重量来衡量航空飞机的制造进度一样。”所以,相对于代码的数量,我们通常更乐意去关注代码本身的质量,也因此,在开源社区里,除了某些特殊的目的,我们也更愿意去关注一个人被接受patch的数目,而不是这些patch里代码的行数。
对于“代码质量”的定义,我们应该每个人都能说个不尽相同的三言两语,但是更多的感觉可能是只可意会不可言传,很难真正地使用统一的标准去定义清楚。当然,已经有一些研究和工具在通过各种指标来对代码的质量进行量化,就比如这里以Code Review过程中每分钟出现“脏话”的个数来衡量代码的质量。

总之,将“代码质量”定义清楚是一件足够复杂的事情。幸好,笛卡儿很有预见性地在17世纪的某一天,闲极无聊写了这么一本书,书名就叫《方法论》,在这本目前来说绝大部分人都不知道的书里将方法上升到了理论的高度。笛卡儿在他的这本书里将研究问题的方法归纳为简单的一句话,就是“复杂问题要简单化”。
代码一是给计算机读,二是给人来读,给维护这份代码的人来读。给计算机读比较简单,只要遵守语言的规则,计算机就能将它编译成最后的结果。给人来读就比较麻烦,我们去读别人的代码的时候,我们都是希望这个代码写得比较简单,函数很短,命名能够让人望文生义,读起来就像读小说故事会一样,等等,我们希望的就是我们自己编码的时候应该要做到的目标,这就是站在通俗角度简单化了的代码质量。
这个简单化了的定义强调更多的是代码的可读性,“代码应该是写给其他人来读的,而能让机器运行的仅仅是附带着的。”大牛们如是说。可读性是其他一切代码质量指标,包括可维护性、可靠性、可扩展性、性能等的基石,一般来说,干净整洁的代码,往往运行起来更快。而且即使它们不快,也可以很容易地让它们变快。正如人们所说的,优化正确的代码比改正优化过的代码容易多了。
但是对于任何一个蓬勃发展前景无限可期的开源项目来说,它的代码质量却不能只是这么简单地给个通俗定义,而是必须有一套行之有效的体系与工具来保证。
站在软件工程的高度,通常来说,代码质量保证的步骤通常可以概括为:
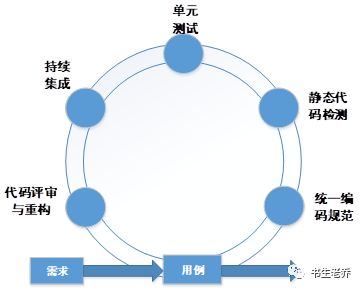
统一编码规范
这里所谓的统一编码规范,其实涵盖了两个方面的含义:一份行之有效的编码规范,加上一些辅助检查代码是否符合规范的工具。
一个项目或者一个企业,如果要下决心提高软件的质量,第一步要做的就是制定有效的软件编码规范。这份规范就是通向成为一个百年老店的车票,21世纪的年轻人要注意,没有买票就上车大多都不会有个好的结果。
而要真正把编码规范贯彻下去,单单靠程序猿的热情,很难坚持下去。这个世界上有两样最不靠谱的东西,一个是程序猿的审美,另一个就是程序猿的热情,这个热情需要高回报做支撑,有了高回报热情就可以美化为福报。所以编码规范要能够真正的实施下去,最好需要一些工具做配合,这些工具可以应用在编码的过程中,比如提交代码之前必须通过工具的检测。
但是不管你的编码规范多么的美艳不可方物,它所起到的作用也只是预防、预防、还是预防,所以我们需要接下来更多的步骤。
静态代码检测
代码的开发完成以后,接着要进行的工作就是测试。而从计算机理论的角度来说,测试又被划分为静态测试与动态测试。
其中,动态测试指的就是通常意义上我们所说的测试,它会去运行测试代码或直接运行被测试的软件来发现存在的问题。静态测试则是指应用其他手段实现测试目的,比如属于人工范畴的代码评审(CodeReview)与计算机辅助进行的静态代码检测。
代码的静态检测主要指利用静态分析工具对代码进行特性分析,以便检查程序逻辑的各种缺陷和可疑的程序构造,主要是让开发人员对编译器发现不了的潜在错误进行分析,如无效的死循环,多余的变量等,同一指针被释放多次等。
之所以称为静态代码检测,是因为只是分析源代码或者生成的目标文件,并不实际运行源代码生成可执行文件。它的目的是帮助我们尽可能早地在产品上线前就发现代码中存在的问题并及时修复,将其消灭在萌芽状态,进而为后续工作节省大量的花在测试与调试上面的时间。
我们应该都有沉痛的领悟:bug发现的越晚,修正的成本就越高。据权威部门统计,测试阶段修正bug的成本是编码阶段的约4倍的关系。为了减少成本,bug被发现的越早越好。在编程阶段,静态的分析代码就能找到代码的bug,是很多程序猿的梦想。而这个梦想随着以Coverity等为代表的很多静态分析工具的出现变成了现实。
基于编译器和静态代码分析工具都能检查代码中的潜在问题,所以不可避免的会拿它俩来做对比。编译器最重要的作用是生成可执行文件,它需要完成一系列的步骤:源程序(sourcecode)→ 预处理器(preprocessor)→ 编译器(compiler)→ 汇编程序(assembler)→ 目标程序(objectcode)→ 连接器(链接器,Linker)→ 可执行程序(executables)。为了能够更快的完成这一系列的过程,编译器在词法语法分析上不能耗费太多时间,也就是说,在检测错误时,前后查看的代码较少,这也是很多隐藏比较深的错误在编译过程中很难被发现的原因。
与检测出更多的错误相比,编译器更为在意的是生成可执行文件的性能,对于大的项目,比如Android,边以都要半天的时间,即使很少的性能提升都会节省不少分钟的时间。而代码静态分析工具却正好相反,寻求的是更多的发现代码中存在的各种问题,性能倒是并不在意,在时间上并没有苛刻的要求。所以,这些分析工具通常会非常慢,这个慢带来了很多的好处,可以对中间生成的抽象语法树做全面精确的分析,更为准确找到更多的问题。
这里是一些常见的C/C++静态分析工具:

sprase最初是由Linus编写,用于在linux内核源代码中发现各种类型的漏洞,后来Linus没有继续维护,交给josh维护,josh成功实现他的另外一个目标:推广sparse从内核到应用程序项目的广泛使用.
Coverity公司是由一流的斯坦福大学的科学家于2002年成立的,可以说是代码静态分析工具中的劳斯莱斯。基于Coverity的静态分析工具,于2006年由美国国土安全部发起并与斯坦福大学合办了一个关注开源代码完整性的公私合营的研究项目——Coverity Scan,对Linuxn内核、Firefox、Perl、Python等主要的开源项目进行扫描评估,下面这张表就是来自于Coverity Scan在2010年给出的开源软件质量报告。
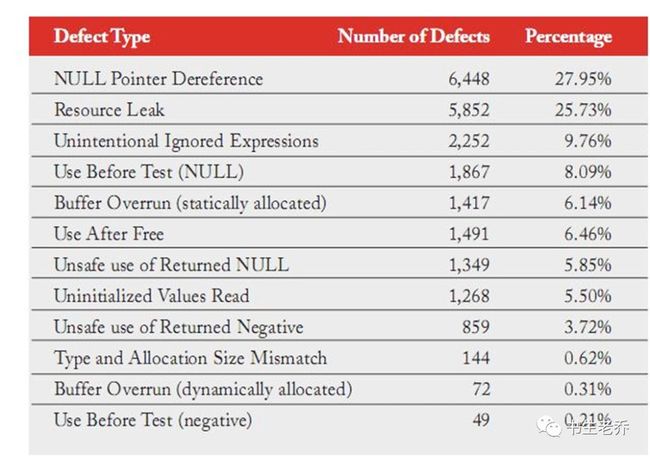
可以看到,即使内核等大神云集的项目,资源泄露、缓冲区溢出等错误的数量与比例也是如此醒目。所以,大神也在人间。
喜欢的话,欢迎扫码关注:)
