机器学习第八篇:逻辑回归
今天学习了逻辑回归,逻辑回归可以看做是线性回归的一种特殊情况吧。
1.理论知识
为什么说逻辑回归可以看做是线性回归的特殊情况呢?
首先![]() 是我们的线性回归模型,那么加入我们更替我们的y将y替换为lny,又会如何呢?这被称作‘广义线性模型’。
是我们的线性回归模型,那么加入我们更替我们的y将y替换为lny,又会如何呢?这被称作‘广义线性模型’。
线性模型有很多,但又一种非常特殊的函数,sigmod函数,当我们把范围扩大,就呈现出阶跃函数的趋势,那么我们能不能用这样的一个特性去进行分类呢?答案是肯定的,逻辑回归,听名字是回归,但我们一般都用来分类,为什么不叫逻辑分类呢?逻辑回归本质上还是回归操作,因为sigmod函数的关系我们可以设定阈值来达到分类的目的。
Sigmod函数: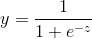
带入我们的![]() 可以得到:
可以得到:
![]()
然后变形可以得到:
![]()
如果我们将y看作分类的几率:![]() ,那么就有:
,那么就有:
![]()
然后可以导出:
![]()
![]()
2.参数估计
说到参数估计我就想起来我的室友在面试的时候遇到过这样一个问题,为什么逻辑回归选择使用极大似然来估计而不是最小二乘呢?这里我也具体说一下。
其一是因为如果你使用平方损失函数,你会发现梯度更新的速度和sigmod函数本身的梯度是很相关的。sigmod函数在它在定义域内的梯度都不大于0.25。这样训练会非常的慢。而极大似然和sigmod函数本身的梯度是无关的。这样更新的速度是可以自始至终都比较的稳定。
逻辑回归的最小二乘不是参数w的凸函数,会产生局部最优解,不容易得到全局最优解,而逻辑回归的极大似然是w的凸函数,是可以证明的。参数估计是建立在无约束的凸优化的基础上当问题含有约束条件的时候我们需要使用拉格朗日算法将有约束问题转化为无约束问题(SVM中出现)。
因为逻辑回归不是一种回归,而是一种分类算法。而逻辑回归的假设函数是属于指数分布族,且逻辑回归的样本给予满足伯努利分布而进行训练的。最大似然估计的出发点就是使得当前样本发生的可能性最大化,反向支持逻辑回归样本满足伯努利分布。而最小二乘法只是让预测值和观测值更拟合,而最大似然估计是保证计算出的特征值发生的概率正确率最大化,最大似然更满足逻辑回归是一种分类器。
最小二乘与极大似然也是有关联的,当误差呈现高斯分布的时候,两者是相等的:
首先假设线性回归模型具有以下形式:
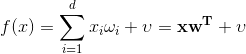
假设![]() ,也就是说
,也就是说![]() ,那么用最大似然来估计:
,那么用最大似然来估计:
![]()
![]()
这也就是最小二乘啊。
讨论完方法的选择,然后开始计算:
设:![]()
![]()
似然函数:
![]()
![]()
![]()
对L(w)求极大值,得到w的估计值:
![]()
![]()
3.实例代码
梯度下降法大家应该都知道:
![]()
而我们现在需要求解我们的最大值,我们使用类似的叫做梯度上升法:
![]()
![]()
然后建立在上述公式的基础上,代码如下:
def sigmoid(inX):
return 1.0/(1+exp(-inX))
def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn)
labelMat = mat(classLabels).transpose()
m,n = shape(dataMatrix)
alpha = 0.001
maxCycles = 500
weights = ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix*weights)
error = (labelMat - h)
weights = weights + alpha * dataMatrix.transpose()* error
#最后一步为何这样写我上面的推导的最后一个公式已经给出了答案
return weights4.随机梯度上升
当数据量非常大的时候,使用上面的方法计算的复杂度就太高了,改进的方法是依次仅用一个样本点来更新回归系数,此时可以把程序改成如下形式:
def stocGradAscent0(dataMatrix, classLabels):
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones(n) #initialize to all ones
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights但是这样处理肯定会有较大的误差,可以多加一层循环,增加迭代的次数,但简单的这样还是会有问题,w在迭代的过程中会出现周期性的波动(可以不用了解),最终的改进算法如下:
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones(n) #initialize to all ones
for j in range(numIter):
dataIndex = range(m)
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 #apha decreases with iteration, does not
randIndex = int(random.uniform(0,len(dataIndex)))#go to 0 because of the constant
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights5.数据缺失的处理
最后一个问题就是在处理之前发现数据有缺失怎么办,常见的处理方法如下:
- 使用可用特征的均值来填补缺失值
- 使用特殊值来填补缺失值,如-1,0,1
- 忽略有缺失值的样本(标签缺失的话一般都要忽略了)
- 使用相似样本的均值来填补
- 使用另外的算法
而在逻辑回归当中我们针对特征值的缺失通常采取的办法是用0填补,具体的理由如下:
- 使用0的话对weight不会产生较大影响,因为weights = weights + alpha * error * datanatrix[index]这一项的后面会变成0,即weights = weights不会产生奇怪的影响
- 由于sigmod(0) = 0.5,它对预测的结果不具有任何的倾向性
针对类别标签缺失的情况,只能选择将该条数据丢弃了。