支持向量机(SVM)算法详解
1. 背景:


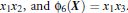
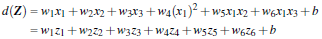
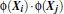 ,其中
,其中
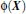 是把训练集中的向量点转化到高维的非线性映射函数,因为内积的算法复杂
是把训练集中的向量点转化到高维的非线性映射函数,因为内积的算法复杂

f(x) = (1, 2, 3, 2, 4, 6, 3, 6, 9)
f(y) = (16, 20, 24, 20, 25, 36, 24, 30, 36)
= 16 + 40 + 72 + 40 + 100+ 180 + 72 + 180 + 324 = 1024
1.1 最早是由 Vladimir N. Vapnik 和 Alexey Ya. Chervonenkis 在1963年提出
1.2 目前的版本(soft margin)是由Corinna Cortes 和 Vapnik在1993年提出,并在1995年发表
1.3 深度学习(2012)出现之前,SVM被认为机器学习中近十几年来最成功,表现最好的算法
2. 机器学习的一般框架:
训练集 => 提取特征向量 => 结合一定的算法(分类器:比如决策树,KNN)=>得到结果
3. 介绍:
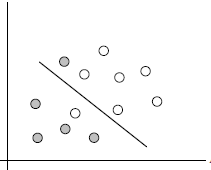
3.1 例子:
两类?哪条线最好?
3.2 SVM寻找区分两类的超平面(hyper plane), 使边际(margin)最大
总共可以有多少个可能的超平面?无数条
如何选取使边际(margin)最大的超平面 (Max Margin Hyperplane)?
超平面到一侧最近点的距离等于到另一侧最近点的距离,两侧的两个超平面平行
3. 线性可区分(linear separable) 和 线性不可区分 (linear inseparable)
4. 定义与公式建立
超平面可以定义为:
W: weight vectot, n 是特征值的个数
X: 训练实例
b: bias
4.1 假设2维特征向量:X = (x1, X2)
把 b 想象为额外的 wight
超平面方程变为:
所有超平面右上方的点满足:
所有超平面左下方的点满足:
调整weight,使超平面定义边际的两边:
综合以上两式,得到: (1)
所有坐落在边际的两边的的超平面上的被称作”支持向量(support vectors)"
分界的超平面和H1或H2上任意一点的距离为 (i.e.: 其中||W||是向量的范数(norm))
所以,最大边际距离为:
5. 求解
5.1 SVM如何找出最大边际的超平面呢(MMH)?
利用一些数学推倒,以上公式 (1)可变为有限制的凸优化问题(convex quadratic optimization)
利用 Karush-Kuhn-Tucker (KKT)条件和拉格朗日公式,可以推出MMH可以被表示为以下“决定边
界 (decision boundary)”
其中,
是支持向量点 (support vector)的类别标记(class label)
是要测试的实例
和 都是单一数值型参数,由以上提到的最有算法得出
是支持向量点的个数
5.2 对于任何测试(要归类的)实例,带入以上公式,得出的符号是正还是负决
1 sklearn简单例子
#!/usr/bin/env python
#-*-coding:utf-8-*-
#支持向量积的使用,建立超平面
from sklearn import svm
x=[[2,0],[1,1],[2,3]]
y=[0,0,1]
clf=svm.SVC(kernel='linear')
#kernel='linear'线性核函数
clf.fit(x,y)
print(clf)
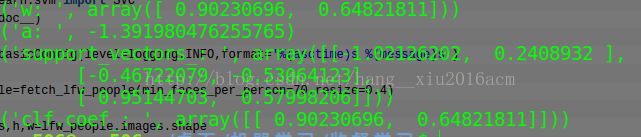
print(clf.support_vectors_)
#支持向量
print(clf.support_)
#支持向量的位置
print(clf.n_support_)
#支持向量的个数
print(clf.predict([2,0]))
结果解释:
SVM分类器的模型,各个参数的打印
支持向量的坐标
支持向量在测试集中的位置坐标
两个支持向量的个数
2 sklearn 画出决定界限
#!/usr/bin/env python
#-*-coding:utf-8-*-
#svm 向量积的使用2
import numpy as np
import pylab as pl
#画图
from sklearn import svm
np.random.seed(0)
X=np.r_[np.random.randn(20,2)-[2,2],np.random.randn(20,2)+[2,2]]
Y=[0]*20+[1]*20
#两部分进行赋值
clf=svm.SVC(kernel='linear')
clf.fit(X,Y)
#获得线性函数的系数
w=clf.coef_[0]#得到斜率
a=-w[0]/w[1]#生成x为-5--5的随机数
xx=np.linspace(-5,5)
yy=a*xx-(clf.intercept_[0])/w[1]
b=clf.support_vectors_[0]#得到支持向量的下向量
yy_down=a*xx+(b[1]-a*b[0])#支持向量的下向量
b=clf.support_vectors_[-1]
yy_up=a*xx+(b[1]-a*b[0])
print('w: ',w)
print('a: ',a)
print('support_vectors_: ',clf.support_vectors_)
print('clf.coef_: ',clf.coef_)
#三条直线
pl.plot(xx,yy,'k-')
pl.plot(xx,yy_down,'k--')
pl.plot(xx,yy_up,'k--')
#特殊的话支持向量点的
pl.scatter(clf.support_vectors_[:,0],clf.support_vectors_[:,1],
s=80,facecolors='none')
#一般点的函数pl.scatter(X[:,0],X[:,1],c=Y,cmap=pl.cm.Paired)
pl.axis('tight')
pl.show()
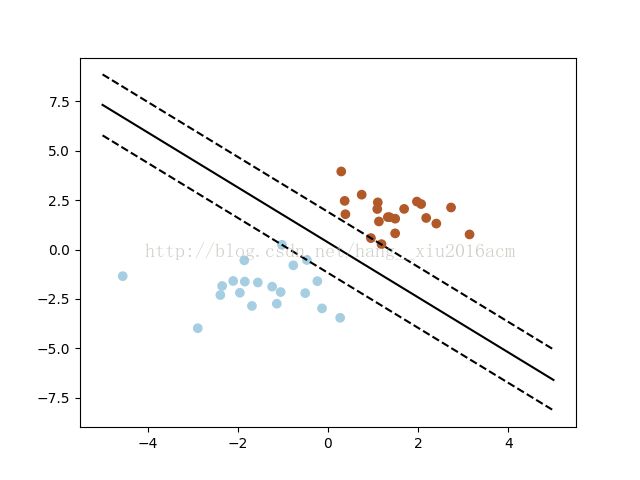
结果解释:
w: 表示线性函数的系数
a: 表示线性函数的斜率
支持向量的坐标
2 打印的图形
1 SVM算法特性:
1.1 训练好的模型的算法复杂度是由支持向量的个数决定的,而不是由数据的维度决定的。所以SVM不太容易产生overfitting
1.2 SVM训练出来的模型完全依赖于支持向量(Support Vectors), 即使训练集里面所有非支持向量的点都被去除,重复训练过程,结果仍然会得到完全一样的模型。
1.3 一个SVM如果训练得出的支持向量个数比较小,SVM训练出的模型比较容易被泛化。
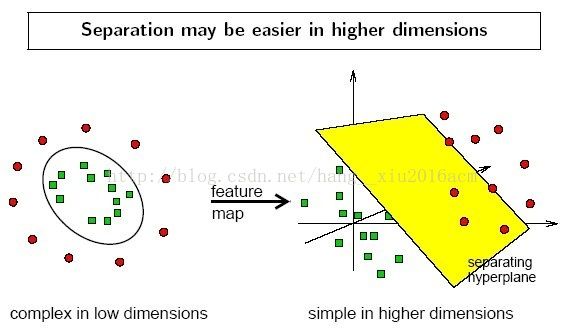
2. 线性不可分的情况 (linearly inseparable case)
2.1 数据集在空间中对应的向量不可被一个超平面区分开
2.2 两个步骤来解决:
2.2.1 利用一个非线性的映射把原数据集中的向量点转化到一个更高维度的空间中
2.2.2 在这个高维度的空间中找一个线性的超平面来根据线性可分的情况处理
2.2.3 视觉化演示 https://www.youtube.com/watch?v=3liCbRZPrZA
2.3 如何利用非线性映射把原始数据转化到高维中?
2.3.1 例子:
3维输入向量:
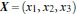
转化到6维空间 Z 中去:
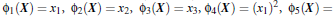
新的决策超平面:
 其中W和Z是向量,这个超平面是线性的
其中W和Z是向量,这个超平面是线性的
解出W和b之后,并且带入回原方程:
2.3.2 思考问题:
2.3.2.1: 如何选择合理的非线性转化把数据转到高纬度中?
2.3.2.2: 如何解决计算内积时算法复杂度非常高的问题?
2.3.3 使用核方法(kernel trick)
3. 核方法(kernel trick)
3.1 动机
在线性SVM中转化为最优化问题时求解的公式计算都是以内积(dot product)的形式出现的
度非常大,所以我们利用核函数来取代计算非线性映射函数的内积
3.1 以下核函数和非线性映射函数的内积等同
3.2 常用的核函数(kernel functions)
h度多项式核函数(polynomial kernel of degree h):
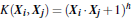
高斯径向基核函数(Gaussian radial basis function kernel):

S型核函数(Sigmoid function kernel):

如何选择使用哪个kernel?
根据先验知识,比如图像分类,通常使用RBF,文字不使用RBF
尝试不同的kernel,根据结果准确度而定
3.3 核函数举例:
假设定义两个向量:
x = (x1, x2, x3); y = (y1, y2, y3)
定义方程:
f(x) = (x1x1, x1x2, x1x3, x2x1, x2x2, x2x
3, x3x1, x3x2, x3x3)
K(x, y ) = ()^2
假设
x = (1, 2, 3); y = (4, 5, 6).
f(y) = (16, 20, 24, 20, 25, 36, 24, 30, 36)
K(x, y) = (4 + 10 + 18 ) ^2 = 32^2 = 1024
同样的结果,使用kernel方法计算容易很多
4. SVM扩展可解决多个类别分类问题
对于每个类,有一个当前类和其他类的二类分类器(one-vs-rest)
利用SVM进行人脸识别实例:
#!/usr/bin/env python
#-*-coding:utf-8-*-
#svm 实现人脸识别
from __future__ import print_function
from time import time
import logging
import matplotlib.pyplot as plt
from sklearn.cross_validation import train_test_split
from sklearn.datasets import fetch_lfw_people
from sklearn.grid_search import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.decomposition import RandomizedPCA
from sklearn.svm import SVC
print(__doc__)
logging.basicConfig(level=logging.INFO,format='%(asctime)s %(message)s')
#进展打印
lfw_people=fetch_lfw_people(min_faces_per_person=70,resize=0.4)
#加载数据
n_samples,h,w=lfw_people.images.shape
#个数图片,图片的h,w
X=lfw_people.data
#特征向量
n_features=X.shape[1]
#特征向量的维数
y=lfw_people.target
#不同的人字典
target_names=lfw_people.target_names
n_classes=target_names.shape[0]
print('Total dataset size:')
print("n_samples: %d" % n_samples)
print('n_features: %d' % n_features)
print('n_classes: %d' % n_classes)
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25)
#分类
n_components=150
print('Extracting the top %d eigenfaces from %d faces' % (n_components,X_train.shape[0]))
t0=time()
pca=RandomizedPCA(n_components=n_components,whiten=True).fit(X_train)
#降维
print('done in %0.3fs'% (time()-t0))
eignfaces=pca.components_.reshape((n_components,h,w))
#图片特征值
print('Projecting the input data on the eigenfaces orthonormal basis')
t0=time()
X_train_pca=pca.transform(X_train)
#低维矩阵
X_train_pca=pca.transform(X_test)
print('done in %0.3fs' % (time()-t0))
#分类用支持向量机
print('Fitting the classifier to the training set')
t0=time()
param_grid={'C':[1e3,5e3,1e4,5e4,1e5],'gamma':[0.0001,0.0005,0.001,0.005,0.01,0.1],}
#特征值不同比例进行尝试
clf=GridSearchCV(SVC(kernel='rbf',class_weight='auto'),param_grid)
#准确率高那个
clf=clf.fit(X_train_pca,y_train)
print('done in %0.3fs' % (time()-t0))
print('Best extimator found by grid search:')
print(clf.best_estimator_)
#评估准确率
print("Predicting people's names on the test set")
t0=time()
y_pred=clf.predict(X_test_pca)
#预测
print('done in %0.3fs' % (time()-t0))
#print(classification_report(y_test,y_pred,target_names=target_names))
#print(confusion_matrix(y_test,y_pred,labels=range(n_classes)))
#显示正确值与测试值
#def plot_gallery(images,titles,h,w,n_row=3,n_col=4):
# plt.figure(figsize=(1.8*n_col,2.4*n_row))
# plt.subplots_adjust(bottom=0,left=.01,right=.99,top=.90,hspace=.35)
# for i in range(n_row*n_col):
# plt.subplot(n_row,n_col,i+1)
# plt.imshow(images[i].reshape((h,w)),cmap=plt.cm.gray)
# plt.title(titles[i],size=12)
# plt.xticks(())
#plt.yticks(())
#def title(y_pred,y_test,target_names,i):
# pred_name=target_names[y_pred[i]].resplit(' ',1)[-1]
# true_name=target_names[y_test[i]].resplit(' ',1)[-1]
# return 'predicted: %s\ntrue: %s' % (pred_name,true_name)
#prediction_titels=[title(y_pred,y_test,target_names,i) for i in range(y_pred.shape[0])]
#plot_gallery(X_test,prediction_titles,h,w)
#eigenface_titles=['eigenface %d' % i for i in range(eigenfaces.shape[0])]
#plot_gallery(eigenfaces,eigenface_titles.h,w)
plt.show()