YOLO3代码解析
有一个重要的点,在YOLO中每个gt box只选择一个anchor或者pred box进行训练,而在SSD或者其他的里面是可能选择多个的
定位算法中解码和Loss的计算是核心内容,各个算法在解码时,虽然思想差不多,但是还是 有些小的区别,这里进行一个汇总比较
(1) 所谓的解码,就是从feature map解码到检测box的过程
(2) 算loss的时候,也是包含了一个解码过程,同时也包含了loss的target的计算,最后是loss
1: Single shot 算法, YoLo1, YoLo3, SSD
1.2.1 Yolo3的解码
80 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024
81 conv 75 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 75
82 detection
92 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
93 conv 75 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 75
94 detection
104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
105 conv 75 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 75
106 detectionYolo3的最后包含坐标含义的feature map输出的形状是 (nB,75, nH, nW) 是在3个不同的feature map上来解码出Box值,为 (1,75,13,13) (1,75,26,26), (1,75,52,52), 其中75 = 3x(5+class numer 20) , 这里的5代表的是4个坐标值和Conf置信度值
(1) 这里20是20个VOC类别,如果是更换类别,那么需要修改81,93,105层的filter个数即可
(2) 这里的(nB,75, nH, nW) 是代表了有75个平面,每个平面大小是(nH,nW), 相当于是把原图划分成了(nH,nW)个cell. 每个cell是预测3个box, 所以是 3x(5+20) = 75个平面
(3)每个cell在预测3个Box的时候,是以一定的参考Box来进行预测的,这里的参考主要是参考Box的高度和宽度信息, 叫做anchor box, 或者所谓的prior box, Yolo3 中的anchor box 是 [10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326]. 其中[13x13]的feature map是对应的anchor[ 116,90, 156,198, 373,326]以此类推
对于前向传播, 解码的话,是对3个不同feature map做同样处理,最后把各个feature map得到的所有Box进行汇总,最后根据conf值来做一个NMS得到最终的结果
对于前向传播解码过程如下:
# output 的形状是(1,255,13,13)
# anchors 的形状是(6,)
# num_anchors 是一个int数据 = 3
# conf_thresh = 0.5
# num_classes = 80
# 这个函数的作用是对于输入的预测数据,结合anchor数据,来对预测数据进行解码,恢复到真正的检测坐标数据
def get_region_boxes(output, conf_thresh, num_classes, anchors, num_anchors, only_objectness=1, validation=False, use_cuda=True):
device = torch.device("cuda" if use_cuda else "cpu")
anchors = anchors.to(device)
anchor_step = anchors.size(0)//num_anchors
if output.dim() == 3:
output = output.unsqueeze(0)
batch = output.size(0)
assert(output.size(1) == (5+num_classes)*num_anchors)
h = output.size(2)#13
w = output.size(3)#13
cls_anchor_dim = batch*num_anchors*h*w #nB*nA*nH*nW
t0 = time.time()
all_boxes = []#存放的是所有batch的box数据,是一个[[[]]]类型数据,[batch[[box]]]
##-----------------------做解码工作-------begin-------------------------------------------------------------------------------------------
## 核心的思路是所有的处理都归结到(batch*num_anchors*h*w,)上
#本来数据的形状是(batch,num_anchors*(5+num_classes),h,w)
#先变到(batch*num_anchors, 5+num_classes,h*w)
#然后变到(5+num_classes,batch*num_anchors,h*w)
#然后是(5+num_classes,batch*num_anchors*h*w) --- 相当关于是一列是一个Box所具有的数据,列的索引是batch*num_anchors*h*w
output = output.view(batch*num_anchors, 5+num_classes, h*w).transpose(0,1).contiguous().view(5+num_classes, cls_anchor_dim)
#把[0,w-1]之间分成w份,相当于就是生成0,1,3,4在w=5时
#grid_x = torch.linspace(0, w-1, w).repeat(h,1)相当于是对图像进行分成网格,然后生成每个格子的x坐标,数据大小是(h,w)每个位置是网络的x坐标值
#repeat(batch*num_anchors, 1, 1)对这个平面坐标数据,进行整体平面复制
#然后把(batch*num_anchors, h, w)的平面x坐标数据展成1维,变成(batch*num_anchors*h*w)
grid_x = torch.linspace(0, w-1, w).repeat(batch*num_anchors, h, 1).view(cls_anchor_dim).to(device)
#(batch*num_anchors, h, w)的平面y坐标数据
grid_y = torch.linspace(0, h-1, h).repeat(w,1).t().repeat(batch*num_anchors, 1, 1).view(cls_anchor_dim).to(device)
ix = torch.LongTensor(range(0,2)).to(device)
#anchors包含的是原始的方框,针对stride进行归一化后的数据
#变成3行两列,然后取第一个元素,得到所有anchor的w 结果形状是(3,1),结果是2维数据
#pytorch的index_select得到的结果是和原来Tensor一样的
anchor_w = anchors.view(num_anchors, anchor_step).index_select(1, ix[0]).repeat(1, batch, h*w).view(cls_anchor_dim)#1维度数据(nB*nA*nH*nW,)
anchor_h = anchors.view(num_anchors, anchor_step).index_select(1, ix[1]).repeat(1, batch, h*w).view(cls_anchor_dim)#1维度数据(nB*nA*nH*nW,)
# output[0]对应的是(0,batch*num_anchors*h*w) x坐标数据
# output[1]对应的是(1,batch*num_anchors*h*w) y坐标数据
#这里的xs,ys,ws,hs都是(nB*nA*nH*nW,)形状
xs, ys = torch.sigmoid(output[0]) + grid_x, torch.sigmoid(output[1]) + grid_y
ws, hs = torch.exp(output[2]) * anchor_w.detach(), torch.exp(output[3]) * anchor_h.detach()#Returns a new Tensor, detached from the current graph
det_confs = torch.sigmoid(output[4])
# by ysyun, dim=1 means input is 2D or even dimension else dim=0
cls_confs = torch.nn.Softmax(dim=1)(output[5:5+num_classes].transpose(0,1)).detach()
cls_max_confs, cls_max_ids = torch.max(cls_confs, 1)
#(nB*nA*nH*nW,)形状
cls_max_confs = cls_max_confs.view(-1)# view(-1)是把数据变成了1维
cls_max_ids = cls_max_ids.view(-1)
t1 = time.time()
sz_hw = h*w
sz_hwa = sz_hw*num_anchors
det_confs = convert2cpu(det_confs)
cls_max_confs = convert2cpu(cls_max_confs)
cls_max_ids = convert2cpu_long(cls_max_ids)
xs, ys = convert2cpu(xs), convert2cpu(ys)
ws, hs = convert2cpu(ws), convert2cpu(hs)
if validation:
cls_confs = convert2cpu(cls_confs.view(-1, num_classes))
t2 = time.time()
for b in range(batch):#对所有的图像遍历
boxes = []#存放了一个图像的所有预测Box,结果是[[box data]]
#对当前图像的对所有预测Box进行遍历,把置信度满足条件的保存下来
for cy in range(h):
for cx in range(w):
for i in range(num_anchors):
ind = b*sz_hwa + i*sz_hw + cy*w + cx
det_conf = det_confs[ind]
if only_objectness:
conf = det_confs[ind]
else:
conf = det_confs[ind] * cls_max_confs[ind]
if conf > conf_thresh:
bcx = xs[ind]
bcy = ys[ind]
bw = ws[ind]
bh = hs[ind]
cls_max_conf = cls_max_confs[ind]
cls_max_id = cls_max_ids[ind]
#box中存放的是(x,y,w,h,conf,max cls conf, cls_max_id)
box = [bcx/w, bcy/h, bw/w, bh/h, det_conf, cls_max_conf, cls_max_id]
if (not only_objectness) and validation:
for c in range(num_classes):
tmp_conf = cls_confs[ind][c]
if c != cls_max_id and det_confs[ind]*tmp_conf > conf_thresh:
box.append(tmp_conf)
box.append(c)
boxes.append(box)
all_boxes.append(boxes)
#output形状是(5+cls_num,nB*nA*nH*nW)
#gird_x grid_y 是 (nB*nA*nH*nW)
#这下面所有参与运算的数据形状都是(nB*nA*nH*nW),相当于对于各个pred box在列的方向上进行索引
xs, ys = torch.sigmoid(output[0]) + grid_x, torch.sigmoid(output[1]) + grid_y
ws, hs = torch.exp(output[2]) * anchor_w.detach(), torch.exp(output[3]) * anchor_h.detach()
#Returns a new Tensor, detached from the current graph
det_confs = torch.sigmoid(output[4])上面的代码反应的是对所有个pred box进行一起计算,一共所具有的pred box个数是(nB*nA*nH*nW)个, 其中grid_x, grid_y是各个pred box在cell上的索引,是整数,比如0,1,2,....12.
anchor_w 是anchor像素大小对应到feature map的大小,就是除以feature map的stride = 13
相当于对于xs, grid_x, anchor_w这些和大小位置相关的数据,都会映射到同一个参考的feature map上. 具体公式就是
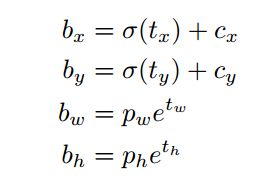
其中的Tx为网络的预测值, Bx是加上anchor数据以后的值, Pw, Ph是anchor的高宽度映射到特征图上的大小, b值是实际计算出来的数据,具体解析如下图

对于训练过程Loss计算如下:
2: