在SMP系统中,我们的应用程序经常使用多线程的技术,那么在Linux中如何查看某个进程的多个线程呢?
本文介绍3种命令来查看Linux系统中的线程(LWP)的情况:
在我的系统中,用qemu-system-x86_64命令启动了一个SMP的Guest,所以有几个qemu的线程,以此为例来说明。
1. pstree 命令,查看进程和线程的树形结构关系。
| |
[
root
@
jay
-
linux
~
]
# pstree | grep qemu
|
-
gnome
-
terminal
-
+
-
bash
--
-
qemu
-
system
-
x86
--
-
2
*
[
{
qemu
-
system
-
x8
}
]
[
root
@
jay
-
linux
~
]
# pstree -p | grep qemu
|
-
gnome
-
terminal
(
10194
)
-
+
-
bash
(
10196
)
--
-
qemu
-
system
-
x86
(
10657
)
-
+
-
{
qemu
-
system
-
x8
}
(
10660
)
|
|
`
-
{
qemu
-
system
-
x8
}
(
10661
)
|
2. ps 命令,-L参数显示进程,并尽量显示其LWP(线程ID)和NLWP(线程的个数)。
|
|
[
root
@
jay
-
linux
~
]
# ps -eLf | grep qemu
root
10657
10196
10657
0
3
13
:
48
pts
/
1
00
:
00
:
00
qemu
-
system
-
x86_64
-
hda
smep
-
temp
.
qcow
-
m
1024
-
smp
2
root
10657
10196
10660
3
3
13
:
48
pts
/
1
00
:
00
:
26
qemu
-
system
-
x86_64
-
hda
smep
-
temp
.
qcow
-
m
1024
-
smp
2
root
10657
10196
10661
2
3
13
:
48
pts
/
1
00
:
00
:
19
qemu
-
system
-
x86_64
-
hda
smep
-
temp
.
qcow
-
m
1024
-
smp
2
root
10789
9799
10789
0
1
14
:
02
pts
/
0
00
:
00
:
00
grep
--
color
=
auto
qemu
|
上面命令查询结果的第二列为PID,第三列为PPID,第四列为LWP,第六列为NLWP。
另外,ps命令还可以查看线程在哪个CPU上运行,命令如下:
|
|
[
root
@
jay
-
linux
~
]
# ps -eo ruser,pid,ppid,lwp,psr,args -L | grep qemu
root
10657
10196
10657
1
qemu
-
system
-
x86_64
-
hda
smep
-
temp
.
qcow
-
m
1024
-
smp
2
root
10657
10196
10660
1
qemu
-
system
-
x86_64
-
hda
smep
-
temp
.
qcow
-
m
1024
-
smp
2
root
10657
10196
10661
2
qemu
-
system
-
x86_64
-
hda
smep
-
temp
.
qcow
-
m
1024
-
smp
2
root
10834
9799
10834
1
grep
--
color
=
auto
qemu
|
其中,每一列依次为:用户ID,进程ID,父进程ID,线程ID,运行该线程的CPU的序号,命令行参数(包括命令本身)。
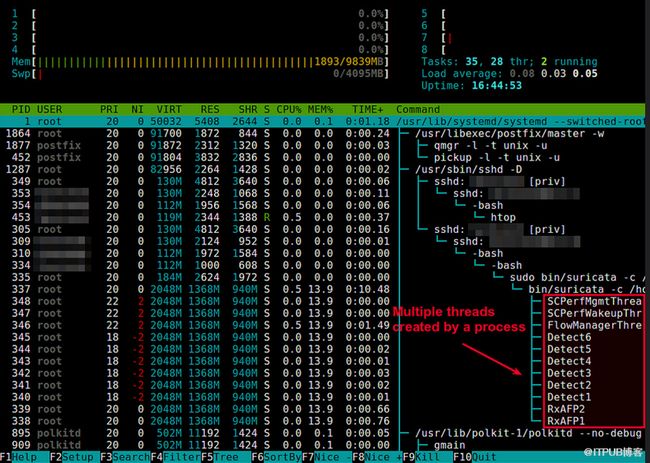
3. top 命令,其中H命令可以显示各个线程的情况。(在top命令后,按H键;或者top -H)
|
|
[
root
@
jay
-
linux
~
]
# top -H
top
-
14
:
18
:
20
up
22
:
32
,
4
users
,
load
average
:
2.00
,
1.99
,
1.90
Tasks
:
286
total
,
1
running
,
285
sleeping
,
0
stopped
,
0
zombie
Cpu
(
s
)
:
0.0
%
us
,
0.0
%
sy
,
0.0
%
ni
,
100.0
%
id
,
0.0
%
wa
,
0.0
%
hi
,
0.0
%
si
,
0.0
%
st
Mem
:
3943892k
total
,
1541540k
used
,
2402352k
free
,
164404k
buffers
Swap
:
4194300k
total
,
0k
used
,
4194300k
free
,
787768k
cached
PID
USER
PR
NI
VIRT
RES
SHR
S
%
CPU
%
MEM
TIME
+
COMMAND
10660
root
20
0
1313m
188m
2752
S
2.3
4.9
0
:
46.78
qemu
-
system
-
x86
10661
root
20
0
1313m
188m
2752
S
2.0
4.9
0
:
39.44
qemu
-
system
-
x86
10867
root
20
0
15260
1312
960
R
0.3
0.0
0
:
00.07
top
1
root
20
0
19444
1560
1252
S
0.0
0.0
0
:
00.34
init
2
root
20
0
0
0
0
S
0.0
0.0
0
:
00.02
kthreadd
.
.
.
.
|
在top中也可以查看进程(进程)在哪个CPU上执行的。
执行top后,按f,按j(选中* J: P = Last used cpu (SMP)),然后按空格或回车退出设置,在top的显示中会多出P这一列是最近一次运行该线程(进程)的CPU.
|
|
PID
USER
PR
NI
VIRT
RES
SHR
S
%
CPU
%
MEM
TIME
+
P
COMMAND
10661
root
20
0
1313m
188m
2752
S
2.3
4.9
0
:
44.24
3
qemu
-
system
-
x86
10660
root
20
0
1313m
188m
2752
S
2.0
4.9
0
:
51.74
0
qemu
-
system
-
x86
10874
root
20
0
15260
1284
860
R
0.7
0.0
0
:
00.32
2
top
1
root
20
0
19444
1560
1252
S
0.0
0.0
0
:
00.34
0
init
2
root
20
0
0
0
0
S
0.0
0.0
0
:
00.02
1
kthreadd
|
更多信息,请 man pstree, man top, man ps 查看帮助文档。
注: LWP为轻量级进程(即:线程),(light weight process, or thread) 。
0.最常用 pstree:
[root@iZ25dcp92ckZ temp]# pstree -a|grep multe
| | `-multepoolser
| | `-multepoolser
| | `-2*[{multepoolser}]
1. > top
可以显示所有系统进程
按u, 再输入相应的执行用户名称,比如Tom
可以看到Tom用户启动的所有进程和对应的pid
2. > pstack pid
可以看到此pid下,各线程的运行状态、
[root@test multepoolserver]# pstack 14944 (进程的PID号)
Thread 2 (Thread 0x41ed5940 (LWP 14945)):
#0 0x0000003c9ae0d5cb in read () from /lib64/libpthread.so.0
#1 0x00000000004017b6 in sync_additional_writing_worker ()
#2 0x0000003c9ae064a7 in start_thread () from /lib64/libpthread.so.0
#3 0x0000003c9a2d3c2d in clone () from /lib64/libc.so.6
Thread 1 (Thread 0x2b24b3094250 (LWP 14944)):
#0 0x0000003c9a2d4018 in epoll_wait () from /lib64/libc.so.6
#1 0x0000000000401d59 in Process ()
#2 0x00000000004029b8 in main ()
来自:http://blog.csdn.net/wind_324/article/details/6152912
方法一:
ps -ef f
用树形显示进程和线程
在Linux下面好像因为没有真正的线程,是用进程模拟的,有一个是辅助线程,所以真正程序开的线程应该只有一个。
方法二:
[root@apache dhj]# ps axm|grep httpd
方法三:
另外用pstree -c也可以达到相同的效果,但是没有线程号:
[root@apache dhj]# pstree -c|grep httpd
来自:http://blog.chinaunix.net/uid-346158-id-2131012.html
1. pstree
pstree以树结构显示进程
- [email protected].*:~# pstree
- init─┬─NetworkManager
- ├─abrt-dump-oops
- ├─abrtd
- ├─atd
- ├─auditd───{auditd}
- ├─automount───4*[{automount}]
- ├─certmonger
- ├─crond
- ├─dbus-daemon
- ├─hald─┬─hald-runner─┬─hald-addon-acpi
- │ │ └─hald-addon-inpu
- │ └─{hald}
- ├─httpd─┬─httpd
- │ └─4*[httpd───26*[{httpd}]]
- ├─irqbalance
- ├─mcelog
- ├─6*[mingetty]
- ├─modem-manager
- ├─mysqld_safe───mysqld───38*[{mysqld}]
- ├─nginx───13*[nginx]
- ├─php-fpm───76*[php-fpm]
- ├─portreserve
- ├─rpc.idmapd
- ├─rpc.statd
- ├─rpcbind
- ├─rsyslogd───3*[{rsyslogd}]
- ├─2*[sendmail]
- ├─sshd───sshd───bash───pstree
- ├─udevd───2*[udevd]
- ├─wpa_supplicant
- └─xinetd
2. ps -Lf
$ ps -Lf 1892
如下:PHP进程共启动了0个线程
[email protected].**:~# ps -Lf 1892
UID PID PPID LWP C NLWP STIME TTY STAT TIME CMD
root 1892 1 1892 0 1 Jan15 ? Ss 0:53 php-fpm: master process (/usr/local/php/etc/php-fpm.conf)
Mysql多个线程:
[email protected].*:~# ps -Lf 3005
UID PID PPID LWP C NLWP STIME TTY STAT TIME CMD
mysql 3005 2011 3005 0 39 Jan15 ? Sl 2:25 /usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/data/mysql --plugin-dir=
mysql 3005 2011 3081 0 39 Jan15 ? Sl 0:00 /usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/data/mysql --plugin-dir=
mysql 3005 2011 3082 0 39 Jan15 ? Sl 0:05 /usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/data/mysql --plugin-dir=
mysql 3005 2011 3083 0 39 Jan15 ? Sl 0:00 /usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/data/mysql --plugin-dir=
mysql 3005 2011 3084 0 39 Jan15 ? Sl 0:00 /usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/data/mysql --plugin-dir=
mysql 3005 2011 3085 0 39 Jan15 ? Sl 0:00 /usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/data/mysql --plugin-dir=
mysql 3005 2011 3086 0 39 Jan15 ? Sl 0:00 /usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/data/mysql --plugin-dir=
mysql 3005 2011 3087 0 39 Jan15 ? Sl 0:05 /usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/data/mysql --plugin-dir=
3. pstack
pstack显示每个进程的栈跟踪,PHP的fpm主进程,发现这玩意是走的epoll:
[email protected]:~# pstack 1892
#0 0x00000030e9ae8fb3 in __epoll_wait_nocancel () from /lib64/libc.so.6
#1 0x0000000000856a74 in fpm_event_epoll_wait ()
#2 0x000000000084afff in fpm_event_loop ()
#3 0x0000000000845ee7 in fpm_run ()
#4 0x000000000084d900 in main ()
You have new mail in /var/spool/mail/root
How to view threads of a process on Linux
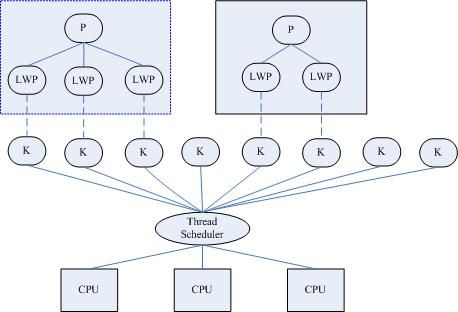
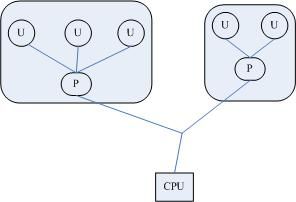
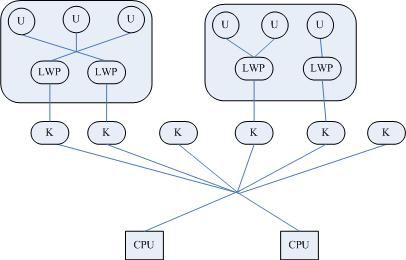
Threads are a popular programming abstraction for parallel execution on modern operating systems. When threads are forked inside a program for multiple flows of execution, these threads share certain resources (e.g., memory address space, open files) among themselves to minimize forking overhead and avoid expensive IPC (inter-process communication) channel. These properties make threads an efficient mechanism for concurrent execution.
In Linux, threads (also called Lightweight Processes (LWP)) created within a program will have the same "thread group ID" as the program's PID. Each thread will then have its own thread ID (TID). To the Linux kernel's scheduler, threads are nothing more than standard processes which happen to share certain resources. Classic command-line tools such as psor top, which display process-level information by default, can be instructed to display thread-level information.
Here are several ways to show threads for a process on Linux.
Method One: PS
In ps command, "-T" option enables thread views. The following command list all threads created by a process with .
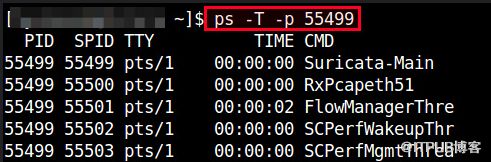
The "SID" column represents thread IDs, and "CMD" column shows thread names.
Method Two: Top
The top command can show a real-time view of individual threads. To enable thread views in the top output, invoke topwith "-H" option. This will list all Linux threads. You can also toggle on or off thread view mode while top is running, by pressing 'H' key.
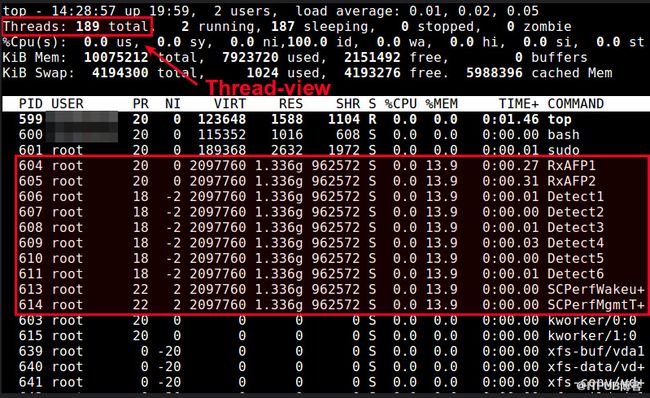
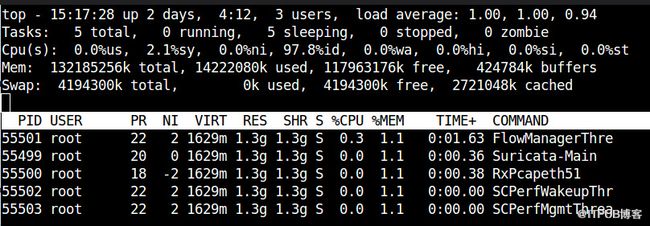
To restrict the top output to a particular process and check all threads running inside the process:
Method Three: Htop
A more user-friendly way to view threads per process is via htop, an ncurses-based interactive process viewer. This program allows you to monitor individual threads in tree views.
To enable thread views in htop, launch htop, and press to enter htop setup menu. Choose "Display option" under "Setup" column, and toggle on "Three view" and "Show custom thread names" options. Presss to exit the setup.
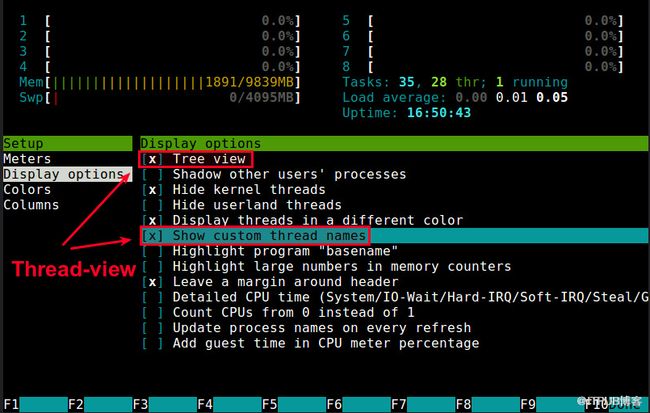
Now you will see the follow threaded view of individual processes.