《Machine Learning Yearning》翻译---绪论(1~4)
近来一直在看"深度学习"相关的东西,为了调节整天看论文和代码后几近抑郁的心情,每天会抽出时间看看吴恩达大神的新书《Machine Learning Yearning》,也尝试着自己进行翻译。这样一则可以提高英文,二则可以加深自己对神经网络的理解。
不知道是不是因为自己的水平不够,总感觉这本书的语言流畅性比较一般,因此在翻译过程中,本人并不是完全直译,会加入自己的理解并补充一点内容,因此如果要原汁原味,请无视本人的翻译直接看原文。
如发现里面有硬伤和错别字,还望指正!!!
下面开始正文:
1.为什么选择机器学习策略
机器学习是无数重要应用的基础,包括网站搜索(Google搜索等)、垃圾邮件过滤(GMail等)、语言识别(讯飞语言等)、产品推荐(亚马逊等)等等。假设你或者你的团队正在制作机器学习应用,并且想取得快速进展,这本书将帮你实现这一点。
例子:用猫咪图片创业
假如你正在创建一家公司,为爱猫人士提供无尽的猫咪图片。
你使用神经网络构建一个机器视觉系统来检测图片中的猫,以便能从海量图片中找到需要的猫咪。但悲剧的是,你的神经网络精确度并不满足要求,会找到一堆别的东西然后告诉你是猫,或者错过一些有猫的图片。你承受着巨大的压力要改善你的猫咪检测器,不然公司可能就凉了。这个时候你将怎么做?
可能你的团队经过头脑风暴,提出了很多的改善预案,比如:
- 获取更多数据:也就是收集更多猫咪的图片来训练神经网络。(强调训练集数量)
- 收集更多样化的训练样本集。例如:猫咪处于不同位置的图片;不同颜色的猫咪的图片;用设置各异的相机拍出来的猫咪图片等。(强调训练集差异化)
- 让猫咪分类器训练更长时间,也就是做更多次的梯度下降迭代,以求更接近全局最优解。(强调训练次数)
- 尝试一个更加庞大的网络,拥有更多的层、隐含单元和参数等。(强调网络结构不能过于简单)
- 尝试一个更小的网络。(这一般能提高训练和分类速度,效果应该不如大的网络)
- 尝试正值化参数(比如L2正值化)。(这里其实翻译成规则化会比较直观一点,但学术圈一般要用逼格高一点的词,因此"正值化")
- ...
如果你在这些可能的预案中选择了正确的一个或者几个,你将建立一个异常给力的猫咪图片平台,带领公司走向成功。但反之,你将浪费数以月计的时间,一事无成。那么,你将选哪个?
这本书将主要解决怎么选这一千古难题。通过很多的机器学习问题留下的线索告诉我们哪些是值得尝试的方向,哪些则纯属扯淡。学会解读这些线索将帮你节省数以月计甚至数以年计的开发时间。
2.怎么利用这本书来帮助你的团队
读完这本书,你将对如何为机器学习项目指明前进的方向有一个深刻的了解。
但你的团队成员可能不明白你为什么选择了一个特别的方向。为此,你可能希望你的团队定义一个单一的评估指标,以方便考核,然而他们未必会被你说服。这时你将怎么做呢?
这就是我将章节做的比较精简的原因:这样你就能在需要的时候将你团队需要知道的问题所对应的1-2页纸直接打印出来给他们看。
一点点优先级的改变有时可能对你的团队生产效率产生巨大的影响。通过帮助你的团队做出这样一些改变,我希望你能成为你团队中的超级英雄!

3.学习本书的先决条件和符号约定
如果你上过机器学习的课程,比如我在可汗学院的机器学习公开课,或者你有应用监督学习的经验,那么你将能很好的理解这本书。
本书会假设你熟悉监督学习(利用贴了标签的样本(x,y)训练从x映射到y的函数,虽然机器学习的形式有很多种,但今天有价值的机器学习实践主要来自于监督学习),包括:线性回归、逻辑回归和神经网络等算法。
且会频繁提到神经网络(现在大多会称为"深度学习",然而并不准确。当然你只需要对它有一个基础的了解即可)。
如果你还不熟悉上面提到的这些概念,可以观看我在可汗学院的深度学习教学视频中前三周的内容。http://ml-class.org

4.数据量级驱动机器学习进程
许多深度学习(神经网络)的想法已经出现了几十年了,为什么直到现在这些想法才流行起来了呢?
因为近些年出现了两个最大的推动力:
- 有效数据的增加:现在的人们会花大量的时间在数字电子设备上(笔记本电脑,手机等)。这些数字设备每时每刻都会生成海量的数据以供我们进行算法的训练。
- 计算规模的增加:我们在近几年才有用足够的计算能力来训练足够大的神经网络,这才使得我们拥有的海量数据的价值得以体现。
具体说来,即便你已经有了很多的数据,但如果你使用的是过去比较老的算法,比如"逻辑回归"。该算法会随着数据的增加到达平缓期(如下图所示),这意味着当数据输入到达一定的量之后,你再输入数据进去算法也不会有什么实质性的提升:
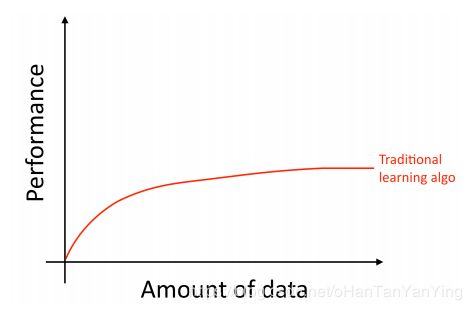
这就好像旧的算法不知道如何处理我们现在拥有的这么多的数据一样。
如果你在同一个监督任务上训练的是一个小的神经网络, 你的任务可能会完成得更好:
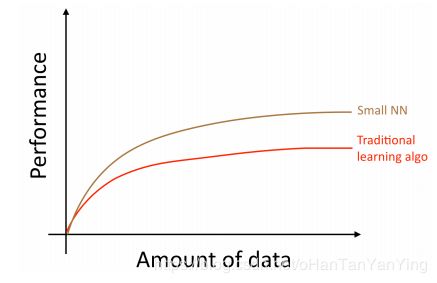
这里,"小的神经网络"指的是仅仅具有少量的隐含单元,层数和参数的网络。当然,随着你训练的网络规模越来越大,你的网络表现将会越来越好:

因此,在下面的两个条件都满足的情况下,你将可以获得一个表现良好的神经网络,如上图绿色的曲线所示:(i)训练一个非常大的神经网络;(ii)拥有海量的数据。
当然,很多的细节,比如神经网络的结构,也是非常重要的,而且这里面有很多的创新点。但今天最可靠的提高算法表现的方法依然是(i)训练一个更大的网络;(ii)获取更多数据。
而如何完成上面提到的这两步却是惊人的复杂,这本书将详细讨论这里面可能涉及到的细节。我们将从传统算法和神经网络都适用的一般策略开始,逐步构建出建立深度学习系统的现代策略。
