A/B Test
目录
- 1. A/B Test 定义
- 2. A/B Test 工作原理
- 3. 为什么要进行A/B Test
- 3.1 解决访客痛点
- 3.2 从现有流量中获得更高的投资回报率(ROI)
- 3.3 降低跳出率
- 3.4 低风险修改
- 3.5 取得统计上显著的改善
- 3.6 有益地重新设计您的网站
- 4 A/B Test流程
- 4.1 确定目标
- 4.2 创建变体
- 4.3 生成假设
- 4.4收集数据
- 4.5 运行试验
- 4.6分析结果
- 5 A/B test简例
- 6 A/B Test 注意的点
- 7 A/B Test实验设计
- 7.1 流量分配
- 7.2 实验效果
- 7.3 实验结束
- 8 A/B Test 要避免的9个错误
- 9 A/B Test 使用场景
1. A/B Test 定义
A/B测试(也称为分割测试或桶测试)是一种将网页或应用程序的两个版本相互比较以确定哪个版本的性能更好的方法。AB测试本质上是一个实验,其中页面的两个或多个变体随机显示给用户,统计分析确定哪个变体对于给定的转换目标(指标如CTR)效果更好。A/B测试就是一种有效的精细化运营手段。
企业希望访问者在其网站上采取行动(也称为转化),而网站推动该转化的速度称为“转化率”
2. A/B Test 工作原理
在A/B test中,你可以设置访问网页或应用程序屏幕并对其进行修改以创建同一页面的第二个版本。这个更改可以像单个标题或按钮一样简单,也可以是完整的页面重新设计。然后,一半的流量显示页面的原始版本(称为控件),另一半显示页面的修改版本(称为变体)。

当用户访问页面时,如上图灰色按钮(控件)和箭头所指红色按钮(变体),利用埋点可以对用户点击行为数据采集,并通过统计引擎进行分析(进行A/B test)。然后,就可以确定这种更改(变体)对于给定的指标(这里是用户点击率CTR)产生正向影响,负向影响或无影响。
3. 为什么要进行A/B Test
3.1 解决访客痛点
用户访问网站有他们的目标。无论用户的目标是什么,可能会遇到一些共同的痛点:这可能是很难找到CTA按钮(如购买、播放等),也可能是令人困惑的副本。**这会增加摩擦并最终影响转化率。**通过访客行为分析工具(如heatmap、 Google Analytics和网页调查)解决用户的痛点。
3.2 从现有流量中获得更高的投资回报率(ROI)
获取任何优质流量的成本可能是巨大的。A / B测试可让您最大程度地利用现有流量,并帮助您提高转化率,而不必花费大量时间获取新流量。
3.3 降低跳出率
判断网站性能的最重要指标之一就是跳出率。原因:例如太多的选择,期望值不匹配等等。由于不同的网站服务于不同的目标并迎合不同的受众,因此没有解决跳出率的固定方法。一种方法是通过A / B测试。通过A / B测试,您可以测试网站元素的多个变体,直到找到最佳版本为止。这可以改善用户体验,使访问者在您的网站上花费更多的时间并降低跳出率。
3.4 低风险修改
通过A / B测试对网页进行较小的增量更改,而不是重新设计整个页面。这样可以减少危害当前转换率的风险。通过A / B测试,您可以将资源用于最少的修改即可获得最大的输出,从而提高ROI。未经测试的更改可能会或可能不会奏效。测试然后进行更改可以使结果确定。
3.5 取得统计上显著的改善
由于A/B测试完全是数据驱动的,没有猜测、直觉的空间,您可以根据在页面花费的时间、演示请求数量、购物车废弃率、点击率等指标上的显著改进,轻松地确定“赢家”和“输家”。
3.6 有益地重新设计您的网站
重新设计的范围从轻微的CTA文本或颜色调整到特定的网页到网站的全面改版。实现一个版本或另一个版本的决定应始终基于数据驱动的A / B测试。 完成设计后,请勿退出测试。随着新版本上线,请测试网页的其他元素,以确保向访问者提供了最具吸引力的版本。
4 A/B Test流程
4.1 确定目标
目标是用于确定变体是否比原始版本更成功的指标。可以是点击按钮的点击率(CTR)、链接到产品购买的打开率、电子邮件注册的注册率等等。
4.2 创建变体
对网站原有版本的元素进行所需的更改。可能是更改按钮的颜色,交换页面上元素的顺序,隐藏导航元素或完全自定义的内容。
4.3 生成假设
一旦确定了目标,就可以开始生成A/B测试想法和假设,以便统计分析它们是否会优于当前版本。
4.4收集数据
针对指定区域的假设收集相对应的数据用于A/B test分析。
4.5 运行试验
此时,网站或应用的访问者将被随机分配控件或变体。测量,计算和比较他们与每种体验的相互作用,以确定每个用户体验的表现。
4.6分析结果
实验完成后,就可以分析结果了。A/B test分析将显示两个版本之间是否存在统计性显著差异。
5 A/B test简例
1. 实例背景简述
某司「猜你想看」业务接入了的新推荐算法,新推荐策略算法开发完成后,在全流量上线之前要评估新推荐策略的优劣,所用的评估方法是A/B test,具体做法是在全量中抽样出两份小流量,分别走新推荐策略分支和旧推荐策略分支,通过对比这两份流量下的指标(这里按用户点击衡量)的差异,可以评估出新策略的优劣,进而决定新策略是否全适合全流量。
2. 实例A/B test步骤
指标:CTR
变体:新的推荐策略
假设:新的推荐策略可以带来更多的用户点击。
收集数据:以下B组数据为我们想验证的新的策略结果数据,A组数据为旧的策略结果数据。均为伪造数据.
3. 分析结果(Python)
利用 python 中的 scipy.stats.ttest_ind 做关于两组数据的双边 t 检验,结果比较简单。但是做大于或者小于的单边检测的时候需要做一些处理,才能得到正确的结果。
from scipy import stats
import numpy as np
import numpy as np
import seaborn as sns
A = np.array([ 1, 4, 2, 3, 5, 5, 5, 7, 8, 9,10,18])
B = np.array([ 1, 2, 5, 6, 8, 10, 13, 14, 17, 20,13,8])
print('策略A的均值是:',np.mean(A))
print('策略B的均值是:',np.mean(B))
Output:
策略A的均值是:6.416666666666667
策略B的均值是:9.75
很明显,策略B的均值大于策略A的均值,但这就能说明策略B可以带来更多的业务转化吗?还是说仅仅是由于一些随机的因素造成的。
我们是想证明新开发的策略B效果更好,所以可以设置原假设和备择假设分别是:
H0:A>=B
H1:A < B
scipy.stats.ttest_ind(x,y)默认验证的是x.mean()-y.mean()这个假设。为了在结果中得到正数,计算如下:
stats.ttest_ind(B,A,equal_var= False)
output:
Ttest_indResult(statistic=1.556783470104261, pvalue=0.13462981561745652)
根据 scipy.stats.ttest_ind(x, y) 文档的解释,这是双边检验的结果。为了得到单边检验的结果,需要将 计算出来的 pvalue 除于2 取单边的结果(这里取阈值为0.05)。
求得pvalue=0.13462981561745652,p/2 > alpha(0.05), 所以不能够拒绝假设,暂时不能够认为策略B能带来多的用户点击。
6 A/B Test 注意的点
- 先验性:通过低代价,小流量的实验,在推广到全流量的用户。
- 并行性:不同版本、不同方案在验证时,要保证其他条件都一致。
- 分流科学性和数据科学性:分流科学是指对AB两组分配的数据要一致,数据科学性是指不能直接用均值转化率、均值点击率来进行AB test决策,而是要通过置信区间、假设检验、收敛程度来得出结论。
- 数据分析常用指标:
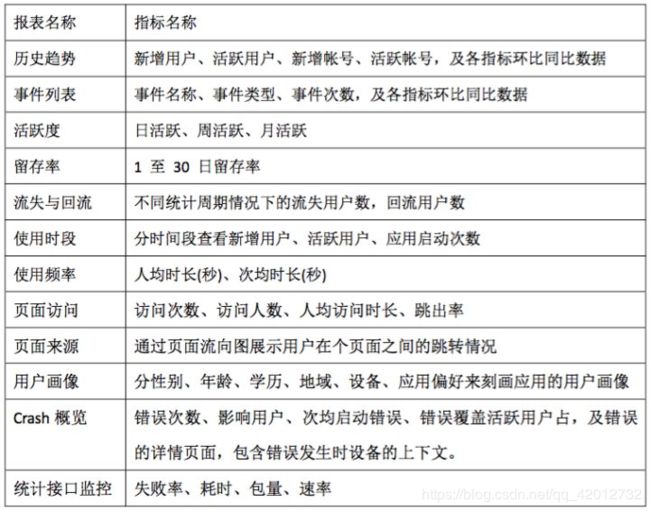
7 A/B Test实验设计
AB Test 实验一般有 2 个目的:
- 判断哪个更好:例如,有 2 个 UI 设计,究竟是 A 更好一些,还是 B 更好一些,我们需要实验判定
- 计算收益:例如,最近新上线了一个直播功能,那么直播功能究竟给平台带了来多少额外的 DAU,多少额外的使用时长,多少直播以外的视频观看时长等
实验的几个基本步骤一般如下:
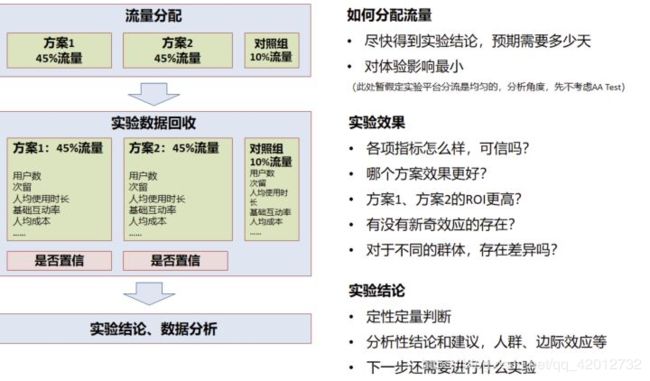
7.1 流量分配
实验设计时有两个目标:
- 希望尽快得到实验结论,尽快决策
- 希望收益最大化,用户体验影响最小
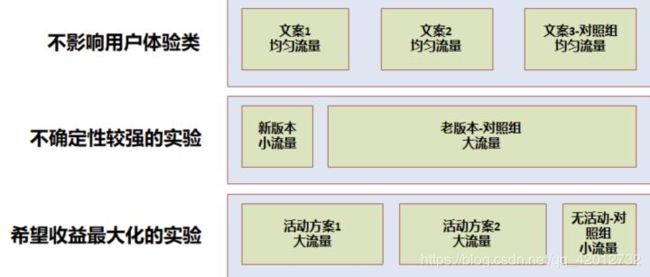
因此经常需要在流量分配时有所权衡,一般有以下几个情况:
- 不影响用户体验:如 UI 实验、文案类实验等,一般可以均匀分配流量实验,可以快速得到实验结论
- 不确定性较强的实验:如产品新功能上线,一般需小流量实验,尽量减小用户体验影响,在允许的时间内得到结论
- 希望收益最大化的实验:如运营活动等,尽可能将效果最大化,一般需要大流量实验,留出小部分对照组用于评估 ROI
根据实验的预期结果,大盘用户量,确定实验所需最小流量,可以通过一个网站专门计算所需样本量:(https://www.evanmiller.org/ab-testing/sample-size.html)
7.2 实验效果
需要回答几个问题
1. 方案 1 和方案 2,哪个效果更好?
要运用假设检验,对于留存率、渗透率等漏斗类指标,采用卡方检验;对于人均时长类等均值类指标,采用t 检验
2. 哪个 ROI 更高?
对于 ROI 的计算,成本方面,每个实验组成本可以直接计算,对于收益方面,就要和对照组相比较,假定以总日活跃天(即 DAU 按日累计求和)作为收益指标,需要假设不做运营活动,DAU 会是多少,可以通过对照组计算,即:
- 实验组假设不做活动日活跃天 = 对照组日活跃天 * (实验组流量 / 对照组流量)
- 实验组收益 = 实验组日活跃天 - 实验组假设不做活动日活跃天
3. 长期来看哪个更好?
考虑新奇效应的问题了,一般在实验上线前期,用户因为新鲜感,效果可能都不错,因此在做评估的时候,需要观测指标到稳定态后,再做评估。(应剔除新奇效应的部分)
4. 不同群体有差异吗?
很多情况下,对新用户可能实验组更好,老用户对照组更好;对年轻人实验组更好,中年人对照组更好,
7.3 实验结束
- 反馈实验结论,包括直接效果(渗透、留存、人均时长等)、ROI
- 充分利用实验数据,进一步探索分析不同用户群体,不同场景下的差异,提出探索性分析
- 对于发现的现象,进一步提出假设,进一步实验论证
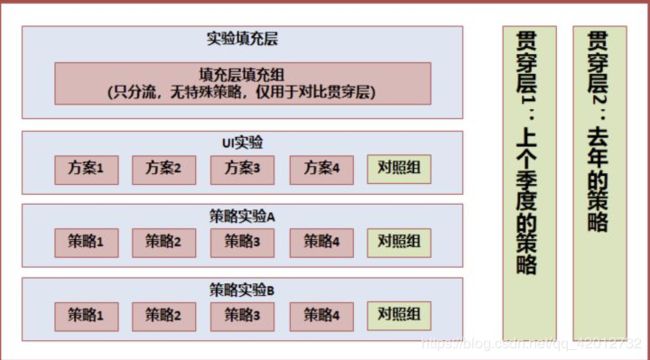
更高级的实验
层域管理模型。
- 对比每个产品细节迭代的结果
- 对比每个专项在一个阶段的贡献
- 对比整个项目在一个阶段的贡献
多个活动交集量化的实验设计,需要一个【贯穿】所有活动的对照组,在 AB 实验系统中通俗称作贯穿层。
业务迭代的同时,如何与自身的过去比较,贯穿层的设计其实不但可以应用在多个活动的场景,有些场景,我们的业务需要和去年或上个季度的自身对比,同时业务还不断在多个方面运用 AB Test 迭代。
8 A/B Test 要避免的9个错误
- 未规划优化路线图
- 一起测试太多元素
- 忽略统计意义
- 使用不平衡流量
- 持续时间不正确
- 无法遵循迭代过程
- 没有考虑外部因素
- 使用错误的工具
- 坚持纯香草A / B测试方法(从长远来看,坚持普通的A / B测试方法不会为您的组织带来奇迹)
9 A/B Test 使用场景
- AB test 系统搭建和维护需要一定成本,对技术也有一定要求,如果该系统做得不好,用了反而有害;用于衡量算法/产品优化。
- 离线测试不会对线上造成影响,ab实验则会
- 当产品在市场上的竞争环境激烈,项目上线需要争取有利时机时,AB Test不适用。AB Test适用于产品的发展期处于相对比较平稳的时候,防止决策错误导致数据下降;
- 多数的ab test系统并不具备决策推全后仍然持续观察的能力
- AB Test帮助从现有流量中提升ROI,不能获取新流量
- 只能做小范围的效果比较,不能衡量一个模型的迁移和泛化能力;
可参考《统计学》贾跃平,可汗学院统计学等书籍和视频。
点估计
区间估计
中心极限定理(样本估计总体的核心,可以对比看一下大数定理)
假设检验
其中假设检验部分为核心,其他辅助更好的理解该部分内容,比如区间估计可以理解为正向的推断统计,假设检验可以理解为反证的推断统计,关于假设检验本身,你可能还需要知道小概率事件、t分布、z分布、卡方分布、p值、alpha错误、belta错误等内容。
https://www.zhihu.com/question/20045543
https://www.cnblogs.com/zichun-zeng/p/9042779.html
https://vwo.com/ab-testing/