常用PySpark API(一): parallelize, collect, map, reduce等API的简单用法
参考:
1. https://www.cnblogs.com/sharpxiajun/p/5506822.html
2. https://blog.csdn.net/wc781708249/article/details/78228117
0. RDD数据类型
RDD(Resilient Distributed DataSet)是一种弹性分布式数据集,是Spark的核心,其可以有由稳定存储中的数据通过转换(transformation)操作得到。RDD数据是一种可以并行操作的数据,它在创建的时候已经分区,且每次对RDD操作的结果可以放到高速缓存中,省去了MapReduce频繁的磁盘IO。
针对RDD数据的操作/函数有两种类型:转换(transformation)和动作(action)。
transformation类型:从一个RDD转化到另一个RDD的函数。
action类型:非RDD与RDD之间的相互转化的函数。
下面将以实验及结果分析的形式,介绍常用的RDD操作的函数。
1. parallelize()、collect()和glom()
实验代码:
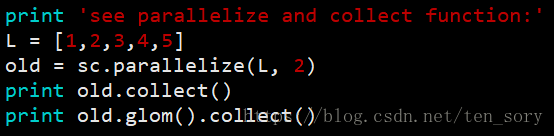
实验结果:

parallelize()函数将一个List列表转化为了一个RDD对象,collect()函数将这个RDD对象转化为了一个List列表。
parallelize()函数的第二个参数表示分区,默认是1,此处为2,表示将列表对应的RDD对象分为两个区。
后面的glom()函数就是要显示出RDD对象的分区情况,可以看出分了两个区,如果没有glom()函数,则不显示分区,如第一个结果所示。
2. map()和reduce()
map()类似于Python中的map,针对RDD对应的列表的每一个元素,进行map()函数里面的尼玛函数(这个函数是map函数的一个参数)对应的操作,返回的仍然是一个RDD对象。
reduce()是针对RDD对应的列表中的元素,递归地选择第一个和第二个元素进行操作,操作的结果作为一个元素用来替换这两个元素,注意,reduce返回的是一个Python可以识别的对象,非RDD对象。
实验代码:
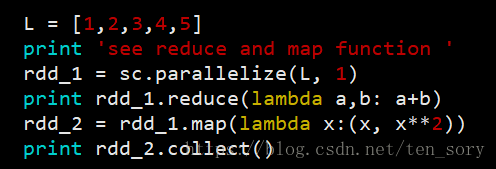
实验结果:

3. map()和flatMap()
上面已经介绍过了map,下面通过对比,就可以知道map()和flatMap()的区别。
实验代码:
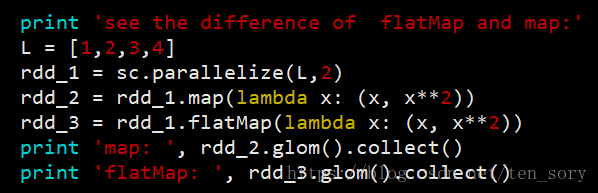
实验结果:

可以看出map和flatMap的区别,前者是用多个元素组成的元组(tuple)替换原来的单个元素,后者直接用多个元素替换单个元素。
4. filter()和distinct()
filter()用于删除/过滤,即删除不满足条件的元素,这个条件一lambda函数的形式作为参数传入filter()函数中。
distinct()用于去重,没有参数。
实验代码:

实验结果:

如图代码中,filter()使用的筛选条件是,选择奇数留下来。而distinct()确实做到了去掉重复元素。
5. reduce()、reduceByKey()和reduceByKeyLocally()
reduce()前面讲过,即最终只返回一个值,reduceByKey()和reduceByKeyLocally()均是将Key相同的元素合并。
区别在于,reduce()和reduceByKeyLocally()函数均是将RDD转化为非RDD对象,而reduceByKey()将RDD对象转化为另一个RDD对象,需要collect()函数才能输出。
实验代码:
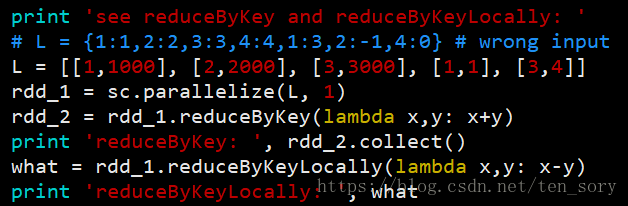
实验结果:

所以结果表明,二者有两个区别。a.前者需要collect(),后者不需要。 b.前者以list形式返回,后者是字典。
注意,这两个函数,允许的输入最好是[[key1,value1], [key2,value2],[key3,value3],......]的形式,其他的形式尚未试验。
6. join()
实验代码:

试验结果:

将两两具有相同key的元素的值,组成一个tuple座位这个key的value
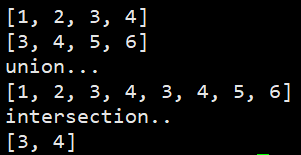
7. union()和intersection()
RDD.union(RDD)求两个RDD对象的所有元素的并,不去掉重复元素
intersection()求交集
实验代码:

实验结果:
其他详细的API,可以参考