[文献笔记]An Unsupervised Neural Attention Model for Aspect Extraction -- Ruidan He et al.
本文主要目的是梳理文章的思路,实际上文章中有些地方写得并不是很清晰,可能需要配合作者的开源实现进一步理解。文章末尾附录了原文链接,源码,以及其它相关资源。在今后的文章中,会对本文的内容进行复现。
- Abstract
- 1.Introduction
- 2.Related Work
- 3.Model Description
- 3.1. Sentence Embedding with Attention Mechanism
- 3.2. Sentence Reconstruction with Aspect Embeddings
- 3.3. Training Objective
- 3.4. Regularization Term
- 4.Experimental Setup
- 4.1. Datasets
- 4.2. Baseline Methods
- 4.3. Experimental Settings
- 5.Evaluation and Results
- 5.1. Aspect Quality Evaluation
- 5.2. Aspect Identification
- 5.3. Validating the Effectiveness of Attention Model
- 6.Conclusion
- 我的参考文献
Abstract
目前的工作都是把topic model(主题模型)的不同变体应用到aspect extraction(方面提取)中,它们通常难以产生高度一致的aspect。本文的工作就是,利用neural word embeddings(神经词嵌入)探索word co-occurrences(词同现)分布,以生成更一致的aspect(word embedding models倾向于将相似contexts(上下文)中出现的词映射到embedding空间中相近的位置)。进一步地,采用了attention mechanism(注意力机制)削弱不相关的词,大幅提高了aspect的coherence(一致性)。实验结果表明,本文的方法可以提取出更有意义和一致的aspect,大幅超过了baseline方法。
1.Introduction
在情感分析中,aspect extraction是最关键的任务之一,目的是提取出opinions(意见)针对的对象,例如“The beef was tender and melted in my mouth”中,aspect term(方面关键词)就是beef。aspect extraction分为两步:(1)从review corpus(“评论”语料库)提取所有的aspect term;(2)将相似的aspect term聚类(e.g. food: beef, pork, pasta…)。
目前在aspect extraction方面的工作可以分为三类:(1)rule-based:通常不把aspect terms按类分组;(2)supervised:需要标注并受限于数据集领域;(3)unsupervised:可以避免对标签的依赖。unsupervised方法中,LDA(Latent Dirichlet Allocation)是近年来的主流方法。(LDA的介绍可以参考“LDA数学八卦”)。LDA模型可以较好地描述混合aspect,然而在单个aspect推测上则效果很差:aspect经常包含不相关的词语。这有两个主要原因:传统LDA并不编码word co-occurrences统计特性,而word co-occurrences是topic的coherence的主要信息源(LDA假设每个词都是独立生成的);LDA给每个训练文档都估计一个topics分布,而review corpus往往很短,使得这个估计很困难。
本文的工作解决了LDA方法的弱点。首先,利用neural word embeddings将相似contexts中出现的词映射到embedding空间中相近的位置;然后,利用attention mechanism过滤句子中的word embeddings。aspect embeddings训练过程类似于autoencoder,利用维度规约提取embedded sentences中的共同因子,然后利用aspect embeddings的线性组合重构句子。这种方法被称作Attention-based Aspect Extraction,ABAE。
ABAE除了弥补了LDA-based方法的缺点,还具有intuitive和结构简单的特点,并能够比较容易地扩展到很大的训练数据集上。
2.Related Work
aspect extraction在最近一个decade中研究得很多。最初,大多采用手工定义规则的方法(寻找高频名词、名词短语),这些方法通常要求aspect terms约束在一组较少的名词上;supervised learning方法将aspect extraction转化为标准序列标注问题(HMM、CRF),这些特征可以手动提取也可以自动学习。这些方法用于aspect分类并不很精确,且需要很大的带标签数据集;最近流行的则是unsupervised方法,尤其是topic model,避免了对带标签数据的依赖。然而这些方法没有区分extraction和categorization的过程,还有上面已经提到过的一些缺点;此外,还有RBM-based(boltzmann machine)(同时提取aspect和相关的情感词语,但需要词性标签和情感词典)方法和BTM(双term topic model)(生成co-occurring词对)方法,本文主要和BTM方法对比。
neural attention模型在自然语言处理任务中很有用,应用在:machine translation、sentence summarization、sentiment classification、question answering中。attention mechanism只关心最相关的信息。本文把它应用到了unsupervised learning中,并展示了其效果。
3.Model Description
ABAE的最终目的是学习一组aspect embeddings,使得每个aspect可以通过embedding space附近的representative words解释。
首先,把词汇表中每个词 w w 用一个特征向量 ew∈Rd e w ∈ R d 表示。我们用word embeddings构造特征向量,把在context中经常co-occur的词映射到embedding space中较近的点。与词关联的特征向量对应于word embedding matrix E∈RV×d E ∈ R V × d 的行,V表示词汇表词数。我们希望学习embeddings of aspect,使aspect与words共享相同的embedding space,即aspect embedding matrix T∈RK×d T ∈ R K × d ,K表示定义的aspect数目,比V小很多。aspect embeddings用来近似词汇表中的aspect words,并利用attention mechanism过滤。
ABAE的每一个输入sample是review sentence中每个词的索引list。给定一个输入,进行以下两步操作:
![[文献笔记]An Unsupervised Neural Attention Model for Aspect Extraction -- Ruidan He et al._第1张图片](http://img.e-com-net.com/image/info8/515f414825d34989aed52154d290824d.jpg)
(1)通过降低权重的方式滤掉non-aspect单词(attention mechanism),并基于weighted word embeddings构建一个sentence embedding zs z s 。(2)用aspect embeddings 的线性组合重构sentence embedding。这个过程包含维度规约和重构,ABAE就是的目的就是将filtered sentences的sentence embeddings转换为它们的重构形式 rs r s ,并尽可能地降低失真,并尽可能保存K个embedded aspect中的aspect words信息。
[个人理解:1.将review的每个词表为one-hot wi w i ;2.映射为特征向量 ewi e w i ;3.基于weighted word embeddings构建sentence embedding zs z s ;4.经过两步利用aspect embeddings重构句子( zs−>pt−>rs z s − > p t − > r s )]
3.1. Sentence Embedding with Attention Mechanism
第一步是构建sentence embedding zs z s ,我们希望它能够捕获关于句子aspect最相关的信息。我们定义 zs z s 为word embeddings的加权和 ewi e w i (i=1,2,…,n,i为词在句子中的index),即:
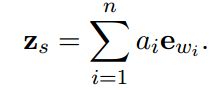
对于句子中每个词 wi w i ,我们都计算出一个正的权重 ai a i ,可以当作该词是句子主要topic关键词的概率。权重 ai a i 是通过attention model计算的,以word embeddings ewi e w i 和句子global context作为作为条件:
![[文献笔记]An Unsupervised Neural Attention Model for Aspect Extraction -- Ruidan He et al._第2张图片](http://img.e-com-net.com/image/info8/2f787ca770894e46800a1fa5b9c0c58d.jpg)
作者相信这种每个词embeddings的平均 ys y s 可以表示句子global context信息(额,相信…)。 M∈Rd×d M ∈ R d × d 是训练得到的,用来将global context embedding和word embedding做一个映射(M起过滤作用)。我们可以把attention mechanism分解为两步:(1)给定一个句子,我们用它每个词embedding的平均作为global context embedding;(2)然后,通过1)利用M矩阵过滤词语,捕捉词语和K个aspect之间的相关性。2)计算过滤后的词语和global context embedding的内积,捕捉过滤后的词语和句子之间的相关性。
3.2. Sentence Reconstruction with Aspect Embeddings
我们已经得到了sentence embedding,我们接下来考虑如何计算sentence embedding的重构。这包含了两步,类似于autoencoder:
(1)可以认为重构向量是aspect embeddings的线性组合:
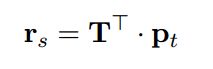
其中 pt p t 是K个aspect embeddings的权重向量,每个分量表示该句子属于这个aspect的概率。
(2)我们可以通过下面的计算获得 pt p t ,将 zs z s 从d维降低到K维,然后利用softmax标准化:
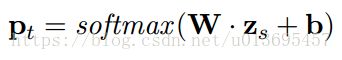
W和b可以训练得到。
3.3. Training Objective
ABAE通过训练来减少重构误差,本文采用contrastive max-margin(对比最大边缘)目标函数。对于每个输入句子,随机地采样m个句子作为负样本。将每个负样本表示为 ni n i ,为这个句子的平均word embedding(类似于求 ys y s 的过程)。训练目的是使得 rs r s 和该正样本 zs z s 相似,同时和m个负样本 ni n i 尽可能不同:
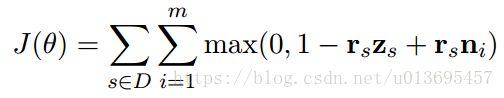
最小化该目标函数即可。D表示训练数据集, θ={E,T,M,W,b} θ = { E , T , M , W , b } 是训练参数。
3.4. Regularization Term
aspect embedding matrix T在训练中可能遇到redundancy problems。为了保证学得的aspect embeddings的多样性,我们在J中增加一个正则化因子,以鼓励每个aspect embedding的独特性:
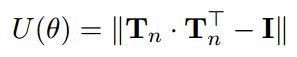
I I 是单位矩阵, Tn T n 是将 T T 的每一行标准化得到的, Tn⋅TnT T n ⋅ T n T 中非对角线元素对应于两个不同的aspect的乘积。当每两个aspect的乘积是0时,U为最小值。因此,U的作用是鼓励 T T 每一行之间的正交性,这就惩罚了不同aspect间的redundancy。最终的目标函数为:
![]()
λ λ 用来控制惩罚的力度。
4.Experimental Setup
4.1. Datasets
采用两个数据集:
![[文献笔记]An Unsupervised Neural Attention Model for Aspect Extraction -- Ruidan He et al._第3张图片](http://img.e-com-net.com/image/info8/08c03f3289b547059f095718818e7116.jpg)
Citysearch corpus:一个restaurant review语料库,其中一个子集做了手工aspect标注,用来评估aspect identification。
BeerAdvocate:一个beer review语料库。也包含一个标注了aspect label的子集。
4.2. Baseline Methods
为了评估ABAE的性能,将它和多个baseline进行了比较:
(1)LocLDA,2010. 基于LDA标准实现,将每一个句子当作一个文档。
(2)k-means. 用k-means聚类生成上面提到的T矩阵,然后固定T矩阵。
(3)SAS,2012. 混合topic model,同时发现aspect和与之相关的opinions。效果在topic model中很好。
(4)BTM,2013. 双term topic model,是专门针对短文设计的。相比于通常的LDA,对无序word-pair 的co-occurrences的生成建模(不是bigram中连续的两个词,只考虑同现性),缓解了短文档的数据稀疏性问题。
4.3. Experimental Settings
我们对review corpora进行预处理:去掉标点符号、stop words、和出现次数少于10的词。baselines采用它们的开源实现,超参数则在一个held-out集合上采用网格搜索的方式,基于主题一致度量(后面还会解释)。对于每个topic model都运行1000个Gibbs采样的迭代。
至于ABAE模型,则基于每个数据集上的负样本采样,用word2vec训练出的word vectors初始化word embedding matrix E。embedding size设置为200,window size设置为10,negative size设置为5。用来训练word embeddings的参数在不同数据上没有进行调整;对于aspect embedding matrix T,则在word embeddings上聚类出几个簇中心来初始化;其它参数则随机初始化。
在restaurant上设置14个aspect,在beer上则设置10到20个aspect,实验结果表明差异并不明显,因此也设置为14。最后,手动将每个推断的aspect根据高排名的代表性词,将它映射到gold-standard aspect之一(人为比较)。在ABAE中,aspect的representative words可以通过查看embedding space与aspect余弦距离最小的几个词确定。
5.Evaluation and Results
5.1. Aspect Quality Evaluation
下表展示了ABAE在restaurant数据上推断的14个aspect中的代表词汇。[gold aspect就是手工定义的标签组,左侧的inferred aspect是手动起的名字]
![[文献笔记]An Unsupervised Neural Attention Model for Aspect Extraction -- Ruidan He et al._第4张图片](http://img.e-com-net.com/image/info8/260ff0b0e1824b7883efda3fd3676871.jpg)
与gold-aspect相比,ABAE学习到的aspect更加细致。
为了客观地评价aspect的质量,我们使用coherence score作为度量标准(这个方法和人类的判断符合得很好)。给定aspect z和其中的top N个词 Sz={wz1,wz2,...,wzn} S z = { w 1 z , w 2 z , . . . , w n z } ,相关得分定义为:
![[文献笔记]An Unsupervised Neural Attention Model for Aspect Extraction -- Ruidan He et al._第5张图片](http://img.e-com-net.com/image/info8/98755c58c167420693d7d63ada0c43e3.jpg)
D1(w) D 1 ( w ) 是文档中单词w的频率, D2(w1,w2) D 2 ( w 1 , w 2 ) 是单词 w1,w2 w 1 , w 2 的联合频率。coherence score越高证明aspect越好。定义average coherence score为:
![]()
下图给出了各个算法的’top n’ – ‘average coherence score’曲线。
![[文献笔记]An Unsupervised Neural Attention Model for Aspect Extraction -- Ruidan He et al._第6张图片](http://img.e-com-net.com/image/info8/4db07aea2ab045a594f4ccbac050e49c.jpg)
实验结果表明:
(1)ABAE表现是最好的;(2)BTM是最好的LDA方法,因为它考虑的是biterm的生成;(3)k-means方法好于所有的LDA方法,说明neural word embedding比LDA可以更好地捕捉co-occurrence。
此外,还有必要评估算法找到的aspect人们是否赞同。本文利用三个人作为裁判,如果认为一个aspect top 50中的词语大多数都一致的表示某个aspect,则认为这个aspect是一致的。下表展示了结果,展现出ABAE的效果是最好的:
![[文献笔记]An Unsupervised Neural Attention Model for Aspect Extraction -- Ruidan He et al._第7张图片](http://img.e-com-net.com/image/info8/a4e9235db74544ecbebc8e8f58abfd13.jpg)
实际操作时,让人们判断这个词是否符合这个aspect并打勾,上图展示了不同的top n时,词语符合aspect的精度,这个结果与之前的coherence score是一致的,且表现了ABAE很好的性能。
5.2. Aspect Identification
我们对两个数据集评估语句级aspect鉴别效果,以评判算法的预测结果和labels的符合程度(precision、recall、 F1 F 1 )。
对于一个review句子,ABAE首先根据 pt p t 中的最高权重给其指定一个推断的aspect标签,然后我们根据inferred aspect和gold-aspect对照表,确定该推断的aspect对应的gold-aspect。
对于restaurant数据集,我们跟随先前研究的实验设置,以便和其它的工作相比较。(1)我们只采用single-label的句子,以避免模糊性;(2)我们只评估3个主要的aspect(Food、Staff、Ambience),因为其它的aspect没有明显的模式甚至用词和写作风格,对于人类都难以辨别。除了baseline模型,我们还比较了其它模型,包括ME-LDA、SERBM。其中SERBM是目前为止在restaurant上表现最好的方法,但是它依赖大量的先验知识。
对于restaurant数据集,实验结果如下图所示。ABAE在aspect(Staff、Ambience)上的 F1 F 1 指标是最好的;ABAE在aspect(Food)上 F1 F 1 指标差于SERBM,但是precision却非常高。实际上,ABAE在attention mechanism下,如果句子中出现一些general descriptions,且没有特别明确的food词汇,就会把它分配到aspect(Staff)上面去。例如“The food is prepared quickly and efficiently.”,quickly和efficiently 是和aspect(Staff)关联很大的,而虽然出现了food这个词,这个句子却倾向于对service的描述,因此分配到aspect(Staff)可能更合适;ABAE比k-means方法在这里表现好很多,(相比于extracting coherent aspect上相当的表现),这是因为attention mechanism的引入使得算法能够聚焦于aspect-related words。
![[文献笔记]An Unsupervised Neural Attention Model for Aspect Extraction -- Ruidan He et al._第8张图片](http://img.e-com-net.com/image/info8/1595129967a444e3abb024b06f850751.jpg)
对于beer数据集,除了上面提到的五个aspect,我们还增加了aspect(Taste+Smell)(比restaurant多3个aspect),这是因为taste和smell比较相似,所以结合起来看。这个数据集上的结果如下图。
![[文献笔记]An Unsupervised Neural Attention Model for Aspect Extraction -- Ruidan He et al._第9张图片](http://img.e-com-net.com/image/info8/18470c8da68549c48ddd9b2e2e967aab.jpg)
结果表明,ABAE效果明显比其它好,尤其是在 F1 F 1 指标上。同时,需要注意所有算法在taste和smell上都得分较差,理由上面已经讨论过了。
5.3. Validating the Effectiveness of Attention Model
![[文献笔记]An Unsupervised Neural Attention Model for Aspect Extraction -- Ruidan He et al._第10张图片](http://img.e-com-net.com/image/info8/cb5cfaadacfd4ffaacbb64998cc7100e.jpg)
上图显示了几个例句上attention model分配的weights of words。模型学到的权重和人类的感觉符合得很好,为了评估attention model对ABAE性能的影响,我们比较保留和去掉attention mechanism的ABAE算法。如下图所示:
![[文献笔记]An Unsupervised Neural Attention Model for Aspect Extraction -- Ruidan He et al._第11张图片](http://img.e-com-net.com/image/info8/b9c60ab77fb840f099978668f1df9e64.jpg)
可以看到引入attention mechanism后,算法的效果得到了全面的提升。
6.Conclusion
本文演示了ABAE算法相比于LDA模型的效果,ABAE可以明确地捕获词co-occurrence模式并克服数据稀疏的问题。我们的实验结果表明,ABAE不仅仅可以学习大量高质的aspect,比之前的方法也更高效。本文是第一个提出无监督的神经方法用来aspect extraction的。ABAE是对LDA-based方法一个有前途的替代。
我的参考文献
- [原文]http://www.aclweb.org/anthology/P/P17/P17-1036.pdf
- [原文一个不太好的翻译]https://www.jianshu.com/p/241cb238e21f
- [LDA数学八卦]http://www.52nlp.cn/lda-math-%E6%B1%87%E6%80%BB-lda%E6%95%B0%E5%AD%A6%E5%85%AB%E5%8D%A6
- [开源代码]https://github.com/ruidan/Unsupervised-Aspect-Extraction
- [aspect extraction 模型总结]https://blog.csdn.net/tiny_diudiu/article/details/79770342