集合collection
- 集合collection
- 简介
- 什么是集合框架
- 集合框架的好处
- 接口
- Collection接口
- 遍历接口Traversing Collections
- 聚合操作遍历集合
- for-each遍历结合
- 迭代器遍历结合
- 集合接口的批量操作
- Collection接口数组操作
- 遍历接口Traversing Collections
- Set接口
- Set接口的基本操作
- Set接口的批量操作
- Set接口的数组操作
- List接口
- Collection操作
- 按照位置访问与搜索操作
- 迭代器Iterators
- Range-View 操作
- List的算法
- Queue接口
- Deque接口
- 插入
- 移除
- 检索
- Map接口
- Map接口的基本操作
- Map接口的批量操作
- 集合视图Collection views
- 使用集合视图的原因Map Algebra代数
- 多重映射Multimaps
- 对象排序Object Ordering
- 定制化对象排序
- SortedSet接口
- SortedMap接口
- 接口的总结
- Collection接口
- 聚合操作Aggregate Operations
- 简介
集合(collection)
本章节介绍集合框架。在这里你将知道什么是集合已经它们是如何让你更轻松的变出更棒的代码。你将会学到集合框架的核心元素——接口、实现和算法。
简介
集合有时候也称为容器、集装箱(Container)——聚合多个元素到单一集合里的对象。集合被用来存储、检索、操作和交流汇总数组。典型的,它们代表组成自然组的数据项,比如扑克(卡片的集合)、邮件夹(信的集合)、电话簿(姓名和电话号码的映射)。
什么是集合框架?
表示和操纵集合的统一架构即是集合框架。所有的集合框架包含以下内容:
- 接口:这些都是表示集合的抽象数据类型。接口允许独立地操作集合的表现细节。在面向对象语言中,接口通常形成一个层次结构。
- 实现(implementations):这是集合接口实现的具体细节。本质上讲,他们是可服用的数据结构。
- 算法:这是执行有用计算的方法,比方说实现集合接口对象的排序、查找。算法是多态的,也就是集合接口内的同一个方法具有不同的实现。本质上讲,算法是可重用的功能。
且不说Java集合框架,比较著名的集合框架非C++标准模板库以及Smalltalk的集合架构莫属。以前,集合框架十分复杂,给人的印象便是十分难学。我们坚信,Java集合框架打破了这种惯例。
集合框架的好处
- 减少编码的工作量。通过提供有用的数据结构及其算法,集合框架可以让你只关注业务逻辑而不是底层的实现。通过促进互操作性,Java集合框架让你从编写通讯类、适配类中解放出来。
- 提升编码速度和质量:Java集合框架提供了高质量、高性能数据结构算法的实现。接口的不同实现可交换性使程序可以轻而易举的改变实现。不用做编写数据结构的苦差,从而剩余更多的时间和经历来提升代码质量和性能。
- 允许不相关APIs间具有互操作性。集合接口是来回传递集合的本地化语言。
- 减少学习和使用新API的时间。
- 减少设计新APIs所耗费的精力。不必重复制造轮子,可以使用标准的集合接口。
- 促进软件重用。新的符合标准集合接口的数据结构自然而然地被重用。实现接口的算法也是一样的。
接口
核心的集合接口封装不同类型的集合,如下图所示。这些接口允许独立地操作集合的表示细节。核心集合接口是Java集合框架的地基。如下图所示,核心集合接口构成了一个层级。
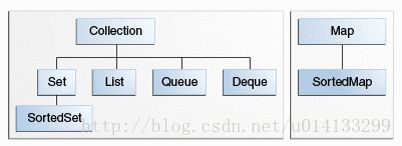
Set是特殊的集合(Collection),SortedSet是特殊的Set,等等。注意,层级包含两种不同的树——Map不是集合。
注意,所有核心的集合接口都是泛型的。例如:
public interface Collection<E>...语法告诉你,这个接口是泛型化的。当你声明一个集合实例的时候,应当指明它的类型。指定类型可以允许编译器在编译时,验证你放入集合元素类型的正确性,因此在一定程度上减少了运行时期的错误。
当你理解如何使用这些接口,你将会了更加理解Java集合框架。本章节主要讨论如何高效地使用这些接口,包括何时使用,使用哪个接口。你也将学到每个接口的编程风格以充分利用它们。
为了管理多个集合接口,Java平台不为每种集合类型的每个变体提供独立的接口(变体如不可变、固定大小等)。每个接口内的修改操作都被设计成可选的。如果执行一个不能支持的操作,就会抛出UnsupportedOperationException。
以下列举了核心集合接口的描述:
- 集合(Collection)。集合层级的根。集合表示一组对象(所熟知的元素:elements)。集合接口是所有集合实现的最小公分母,并在需要最大通用性的情况下用于传递集合并对它们进行操作。一些集合的类型允许元素重复,一些则不允许。一些集合是有序的,一些却是无序的。Java平台没有提供这些接口的直接实现,但提供了更具体子接口的实现,例如Set和List.
- 集合(Set)。不能包含重复元素的集合。该接口模拟数学上的集合抽象,被用于表示集合,例如课程构成了学生的安排表,机器的操作。
- 清单、条目(List)。有序的(有时候称为序列)集合。List可以包含重复元素,List的使用者可以精确地控制到集合的每个元素的操作,如哪个地方插入,哪个地方获取元素。
- 队列(Queue)。在处理之前用于保存多个元素的集合。除了拥有Collection基本操作外,还可以进行插入、提取、检查(inspection)操作。
典型地但不是必须的,元素时FIFO(先入,先出)的。优先队列是个特殊的存在,即根据比较器或者元素的自然顺序排序元素。无论使用什么顺序,队列头部的元素总是会被进行remove或者poll操作。在FIFO队列中,所有新元素都是被插入到队尾。其它种类的队列或许使用其他的放置策略。
- 双端队列(Deque)。在处理之前用于保存多个元素的集合。除了拥有Collection基本操作外,还可以进行插入、提取、检查(inspection)操作。
双端队列可以用作FIFO或者LIFO(后入,先出)。在双端队列中,所有的新元素都可以在对位进行插入、移除、检索。
- 地图(Map)。将key映射到value的对象。Map不能包含重复的key。每个key可以映射到最多一个value。
最后两个核心集合接口仅仅是Set和Map的排序版:
- 排序的集合(SortedSet)。元素是升序的集合。提供几个额外的操作以最大限度发挥排序的优势。
- 排序Map(SortedMap)。key是升序的Map.
Collection接口
集合是一组对象(elements)。集合接口在期望的最大通用性情况下被用来传递对象的集合。例如你拥有一个Collection,它可能是List或者Set或者任何类型的Collection。以下代码用所有在c内的元素来初始化ArrayList:
List list = new ArrayList(c); Collection接口包含基本操作的方法,如size(),boolean isEmpty(), boolean contains(Object element), boolean add(E element), boolean remove(Object element), 和Iterator.
它也包含了操作整个集合的方法, 如boolean containsAll(Collection c), boolean addAll(Collection c), boolean removeAll(Collection c), boolean retainAll(Collection c), 和void clear()。
此外,额外的为数组操作的方法如Object[] toArray() and
jdk8及其之后,接口也暴露了 Stream 和Stream,以获取集合的序列流或者并发流。
集合表示一组对象。告诉你集合里有多少个元素(size,isEmpty);某个对象是否在集合中(contains);往集合内添加元素,移除集合里的元素(add,remove);提供集合的迭代器(iterator);
add方法被定义,这样集合允许元素重复和不可重复就有意义起来了。它保证add方法执行后集合会包含所添加元素,如果集合在调用add后会改变,则返回true。同理,remove操作也一样。
遍历接口(Traversing Collections)
有三种方式来遍历集合:
- 使用聚合操作(aggregate)。
- 使用for-each构造。
- 使用迭代器。
聚合操作遍历集合
JDK 8及其之后,遍历集合首选的方法就是在集合上获取流,然后执行聚合操作。聚合操作是使用lambda表达式来使程序更加有效,使用的代码行数更少。如:
myShapesCollection.stream()
.filter(e -> e.getColor() == Color.RED)
.forEach(e -> System.out.println(e.getName()));
//如果你的计算机有足够的核数,那么可以使用平行流
myShapesCollection.parallelStream()
.filter(e -> e.getColor() == Color.RED)
.forEach(e -> System.out.println(e.getName()));
//打印集合并用逗号分隔开
String joined = elements.stream()
.map(Object::toString)
.collect(Collectors.joining(", "));
//计算薪水的总数
int total = employees.stream()
.collect(Collectors.summingInt(Employee::getSalary)));集合框架提供了许多批量操作(bulk operations),如操纵则整个集合的方法 containsAll, addAll, removeAll。
for-each遍历结合
for-each构造让你可以在集合或数组上简洁地遍历。
for (Object o : collection)
System.out.println(o);迭代器遍历结合
一个迭代器(Iterator)是一个允许你遍历集合并有选择性的移除集合元素的对象。调用集合的iterator方法,你会得到一个迭代器。以下是迭代器的接口:
public interface Iterator<E> {
boolean hasNext(); //有元素,则返回true
E next(); //返回迭代器的下一个元素
void remove(); //optional
}注意,调用每个next()后只能调用一次remove()方法,否则抛出异常。
注意,Iterator.remove是迭代过程中唯一安全的操作方式。在迭代过程用其他方式修改底层代码,则集合的行为是不确定的(不安全)。
使用迭代器而不是用for-each construct当:
- 移除当前元素。for-each构造隐藏了迭代器,因此你不能调用remove。for-each构造内进行过滤操作是不安全的。
- 并行遍历多个集合。
以下程序教你如何在任意集合下进行过滤——即遍历并移除元素:
static void filter(Collection c) {
for (Iterator it = c.iterator(); it.hasNext(); )
if (!cond(it.next()))
it.remove();
}上面的例子体现了多态性的好处,任意Collection的子类都适用以上方法。
集合接口的批量操作
批量操作是在整个集合上进行操作(粒度大)。你可以用基本的操作来实现以下的操作,但是大多数情况下这种实现会十分无效。以下是一些批量的操作:
- containsAll。如果目标集合包含指定集合的所有元素,则返回true.
- addAll。将指定集合的所有元素添加到目标集合中。
- removeAll。移除指定集合和目标集合共有的元素。
- retainAll。交集:保留目标集合和指定集合共有的元素。
- clear。移除所有集合内的元素。
以上操作,如果目标集合被修改,则返回true。
以下代码是从一个集合中移除掉具体的元素:
//singleton()方法是静态工厂方法,返回的是不可变的
c.removeAll(Collections.singleton(e));Collection接口数组操作
toArray()方法是集合和旧的APIs(期望入参是arrays)之间的桥梁。数组操作允许集合元素被翻译成一个数组。简答的形式是创建一个新的Object数组(没有任何参数)。复杂一点的是允许调用者提供一个入参作为数组类型的输出。如:
Object[] a = c.toArray();
String[] a = c.toArray(new String[0]);Set接口
Set是Collection的一种,它不能包含重复的元素。它模拟数学抽象集合。Set接口仅包含从Collection接口继承而来的方法,以及添加对重复元素的限制。Set也添加了更为强大的equals和hashCode操作,这样即使实现的类型不同也能进行有意义的对比。如果两个Set集合内的元素一模一样,则这两个Set集合相同(equals)。
Java平台包含三种Set的实现:HashSet,TreeSet和LinkedHashSet。HashSet将元素存储在一个Hash table中,是性能最佳的实现。然而它并不保证也不关心迭代的顺序。TreeSet将元素存储在一颗红黑树中,据元素值排序,它比HashSet慢多了。LinkedHashSet用一个hash table和Linked list来实现,它保证了元素插入的顺序,它比HashSet代价稍微高些。
如果你想去掉集合中重复的元素,以下一行语句即可解决:
Collection noDups = new HashSet(c);
//JDK 8及其之后,用聚合操作,你可以很容易地将元素放入Set集合中
c.stream()
.collect(Collectors.toSet()); // no duplicates
//取people集合中的name,放到TreeSet中
Set set = people.stream()
.map(Person::getName)
.collect(Collectors.toCollection(TreeSet::new));
//保留插入顺序并去重
Collection noDups = new LinkedHashSet(c);
//去重并保留插入顺序
public static Set removeDups(Collection c) {
return new LinkedHashSet(c);
}
Set接口的基本操作
- size(): Set集合内元素的个数。
- isEmpty(): 判断为空。
- add(): 往集合内添加元素,添加成功返回true。
- remove(): 移除元素,成功返回true。
- iterator(): 返回Set集合的迭代器。
去重示例:
import java.util.*;
import java.util.stream.*;
public class FindDups {
public static void main(String[] args) {
Set distinctWords = Arrays.asList(args).stream()
.collect(Collectors.toSet());
System.out.println(distinctWords.size()+
" distinct words: " +
distinctWords);
}
}
//for-each
import java.util.*;
public class FindDups {
public static void main(String[] args) {
Set s = new HashSet();
for (String a : args)
s.add(a);
System.out.println(s.size() + " distinct words: " + s);
}
} 注意,代码总是涉及到其接口类型而不是实现类型。这是强烈推荐的编程实践,因为改变实现只需改变其构造函数即可(非常灵活)。而存储集合的变量或者参数都是使用Collection的实现类型而不是其接口类型。
此外,并不能保证程序会起作用,假如程序执行了非标准的实现操作,就会导致程序运行失败。
以上的代码使用HashSet来实现去重的,并不能保证其顺序,如果你想让去重后的结果为值有序,则将Set的实现改成TreeSet即可。
Set接口的批量操作
假设s1和s2是集合:
- s1.containsAll(s2)。如果s2是s1的子集,返回true。
- s1.addAll(s2)。 并集。
- s1.retainAll(s2)。交集。
- s1.removeAll(s2)。移除共有元素。
找到重复的元素以及不重复的元素:
import java.util.*;
public class FindDups2 {
public static void main(String[] args) {
Set uniques = new HashSet();
Set dups = new HashSet();
for (String a : args)
if (!uniques.add(a))
dups.add(a);
// Destructive set-difference
uniques.removeAll(dups);
System.out.println("Unique words: " + uniques);
System.out.println("Duplicate words: " + dups);
}
}
//output
Unique words: [left, saw, came]
Duplicate words: [i] Set symmetricDiff = new HashSet(s1);//去重
symmetricDiff.addAll(s2);//并集
Set tmp = new HashSet(s1);//去重
tmp.retainAll(s2);//交集
symmetricDiff.removeAll(tmp);//s1与s2并集 - s1与s2交集 Set接口的数组操作
和Collection接口相比,它具有Collection所有的数组操作,除此之外,它不具备任何额外的数组操作。
List接口
List是Collection的插入有序版本,有时被称为序列(sequence)。List可以包含重复元素。除了从Collection那里继承而来的方法外,还提供额外的方法:
- 根据位置访问元素(Positional access)。根据元素在list内的位置操作元素。如
get,set,add,addAll, 和remove. - 搜索(Search)。搜索指定元素在list中的位置并返回,如
indexOf和lastIndexOf. - 迭代器(
Iteration)。继承Iterator语义,且充分利用list的自然序列。如listIterator。 - 观察范围(range_view)。
subList方法提供list内部的范围操作。
Java平台包含两种类型的List实现,一种是ArrayList,这是性能比较好的一种。另一种是LinkedList,常用于对查询要求不高,但是插入、移除频繁的操作。
Collection操作
从Collection那里继承而来的方法含义和之前的一样,只不过remove操作总是移除掉list第一个出现的指定元素。add 和 addAll操作总是将新的元素追加到list的末尾。如:
//list2追加到list1末尾
list1.addAll(list2);
//list2追加到list3后
List list3 = new ArrayList(list1);
list3.addAll(list2);
//JDK 8及其之后,聚合name到list
List list = people.stream()
.map(Person::getName)
.collect(Collectors.toList()); 和Set一样,List也重写了equals和hashCode方法,因此两个list元素可以进行逻辑的对比是否相等而不用理会List的具体实现。如果两个List内的元素位置一样,对应位置的元素一样,则这两个List集合相等。
按照位置访问与搜索操作
交换List集合内的两个元素:
public static void swap(List a, int i, int j) {
E tmp = a.get(i);
a.set(i, a.get(j));
a.set(j, tmp);
}
//源代码中是
@SuppressWarnings({"rawtypes", "unchecked"})
public static void swap(List list, int i, int j) {
// private method
final List l = list;
//l.set(j, l.get(i))返回j位置旧值
l.set(i, l.set(j, l.get(i)));
} 不管实现类型,下面的多态算法是交换List内部的两个元素:
//Collections方法内 it is fair 几率均等
public static void shuffle(List list, Random rnd) {
for (int i = list.size(); i > 1; i--)
swap(list, i - 1, rnd.nextInt(i));
}
//打印打乱顺序的List集合
import java.util.*;
public class Shuffle {
public static void main(String[] args) {
List list = new ArrayList();
for (String a : args)
list.add(a);
Collections.shuffle(list, new Random());
System.out.println(list);
}
}
//优化打印
public class Shuffle {
public static void main(String[] args) {
List list = Arrays.asList(args);
Collections.shuffle(list);
System.out.println(list);
}
} 上面的shuffle方法,因为rnd是公正的,故所有的排列是机会均等的;因为只需要交换list.size()-1次,因此也是快速的。
迭代器(Iterators)
和你所预想的一样Iterator返回List的迭代器,迭代器会以适当的顺序遍历List集合。List也提供了一个更加强大的迭代器,称为ListIterator,它允许你从两个方向(往前、往后)遍历List;遍历List的同时修改List;获取迭代器当前的位置索引。
ListIterator除了包含从Iterator继承而来的方法hasNext, next和 remove之外,还拥有hasPrevious,previous 以及当前迭代器迭代到哪个位置的索引信息。
//从集合末尾向前迭代
for (ListIterator it = list.listIterator(list.size()); it.hasPrevious(); ) {
Type t = it.previous();
...
} ListIterator所提供的方法如下:
//无参构造函数,指针指向List的开头
ListIterator listIterator();
//有参构造,从index位置开始遍历
ListIterator listIterator(int index);
hasPrevious()//是否有前一个元素
previous()//返回前一个元素,cursor往回移动;next是往前移动
int nextIndex();//下一个位置索引
int previousIndex(); ListIterator迭代器的游标总是介于两个元素之间,如下代码示例:
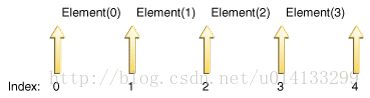
//List有四个元素
List list = Arrays.asList(
"element", "element2", "element3", "element4");
ListIterator it = list.listIterator();
System.out.println(it.previousIndex());
System.out.println(it.next());
System.out.println(it.next());
System.out.println(it.next());
System.out.println(it.next());
System.out.println(it.nextIndex());
//output
-1
element
element2
element3
element4
4 ListIterator迭代器应用场景
//起初游标处于-1到0之间,运行it.next()游标处于0到1之间
public int indexOf(E e) {
for (ListIterator it = listIterator(); it.hasNext(); )
if (e == null ? it.next() == null : e.equals(it.next()))
return it.previousIndex();
// Element not found
return -1;
}
public static void replace(List list, E val, E newVal) {
for (ListIterator it = list.listIterator(); it.hasNext(); )
if (val == null ? it.next() == null : val.equals(it.next()))
it.set(newVal);
}
public static
void replace(List list, E val, List newVals) {
for (ListIterator it = list.listIterator(); it.hasNext(); ){
if (val == null ? it.next() == null : val.equals(it.next())) {
it.remove();
for (E e : newVals)
it.add(e);
}
}
} Range-View 操作
subList(int fromIndex, int toIndex)即是Range-View操作,对目标集合截取子集合,是半开区间即[fromIndex,toIndex)。
view隐含的意思修改subList操作的结果会影响到源List,同样,修改源List**也会影响**到subList返回的子集合。
应用场景,范围查找、洗牌发牌
int i = list.subList(fromIndex, toIndex).indexOf(o);
int j = list.subList(fromIndex, toIndex).lastIndexOf(o);
public class Deal {
public static void main(String[] args) {
if (args.length < 2) {
System.out.println("Usage: Deal hands cards");
return;
}
int numHands = Integer.parseInt(args[0]);
int cardsPerHand = Integer.parseInt(args[1]);
// Make a normal 52-card deck.
String[] suit = new String[] {
"spades", "hearts",
"diamonds", "clubs"
};
String[] rank = new String[] {
"ace", "2", "3", "4",
"5", "6", "7", "8", "9", "10",
"jack", "queen", "king"
};
List deck = new ArrayList();
for (int i = 0; i < suit.length; i++)
for (int j = 0; j < rank.length; j++)
deck.add(rank[j] + " of " + suit[i]);
// Shuffle the deck.
Collections.shuffle(deck);
if (numHands * cardsPerHand > deck.size()) {
System.out.println("Not enough cards.");
return;
}
for (int i = 0; i < numHands; i++)
System.out.println(dealHand(deck, cardsPerHand));
}
public static List dealHand(List deck, int n) {
int deckSize = deck.size();
List handView = deck.subList(deckSize - n, deckSize);
//深拷贝
List hand = new ArrayList(handView);
//subList操作的结果也会如实反映在源List即deck
handView.clear();
return hand;
}
} List的算法
- sort。使用归并排序,是稳定的算法(排序后,相同元素的位置还是保持不变)。
- shuffle。伪随机洗牌。
- reverse。
- rotate。旋转
rotate(List list, int distance)。 - swap。
- replaceAll。
- fill。
- copy。
- binarySearch。
- indexOfSubList。
- lastIndexOfSubList。
Queue接口
队列是在处理之前保存元素的集合。除了基本的集合(Collection)操作之外,队列还提供了额外的插入、移除和检查操作。Queue接口如下所示:
public interface Queue<E> extends Collection<E> {
E element(); //返回头部元素,empty时 抛出异常
//往队里中添加元素,不允许加入null值。
//不用add而用offer的原因是队列容量受限,会抛出异常
boolean offer(E e);
E peek();//返回头部元素,但不移除,empty时返回null
E poll();//返回并移除头部元素,empty时返回Null
E remove();//返回并移除头部元素,empty时抛出异常
}每一个Queue方法以两种形式存在:
- 操作失败,则抛出异常。
- 操作失败,则返回特定的值,如null或false。
如下表所示:
| 操作的类型 | 抛出异常 | 返回特殊的值 |
|---|---|---|
| insert | add(e) | offer(e) |
| remove | remove(e) | poll(e) |
| examine | element(e) | peek(e) |
典型地,Queue都是先进先出(FIFO:first in first out)的,一个例外就是根据值组织元素的优先队列(详见对象排序)。无论什么对象以何种方式排序,通过remove,poll操作都可以移除掉队列头部元素。在FIFO的队列中,新元素被插入对位。其它种类的队列可能会使用其他的添加规则。每一个实现Queue接口的队列都必须指定排序的规则。
Queue的实现类是有可能限制其持有元素的个数的,这种队列是有界的。一些位于java.util.concurrent内的Queue实现类是有界的,但位于java.util内的Queue实现类是无界的。
从Collection内继承而来的add方法,如果使用它来添加元素时违反了Queue的容量会抛出IllegalStateException异常,因此单独地为这种场景提供了offer操作,如果添加不成功,它并不会抛出异常,只会返回false。
remove,poll都是移除队列头元素,究竟是哪一个元素被移除,那是排序策略函数的事情了。当队列为empty时,remove操作会抛出NoSuchElementException而poll操作返回null。
element,peek操作只会返回队列头部元素。当队列为empty时,element操作会抛出NoSuchElementException而peek操作返回null。
队列的实现通常不允许插入null元素,Queue的实现类LinkedList类是一个特例。LinkedList允许插入null元素的原因是历史原因造成的,但是你应该尽量不要插入null元素,因为poll,peek操作在空队列的情况下返回null(究竟是空队列的原因,还是因为元素本身就是null?不得而知,故应尽量不插入null元素)。
Queue的实现类通常不重写equals,hashCode,而是直接使用Object那一套。
Queue的实现类不定义 blocking queue方法,而在并发编程中又经常用到。这些等待元素的出现或空间可用的方法定义在java.util.concurrent.BlockingQueue中,它也是继承自Queue接口。
举个例子
//输入一个整数,以降序方式加入到队列中,
//再每隔1秒钟一个个从队列头中移除出去。
public class Countdown {//倒计时功能,只为解释说明优先队列的行为
public static void main(String[] args) throws InterruptedException {
int time = Integer.parseInt(args[0]);
Queue queue = new LinkedList();
for (int i = time; i >= 0; i--)
queue.add(i);
while (!queue.isEmpty()) {
System.out.println(queue.remove());
Thread.sleep(1000);
}
}
}
//集合排序,只为解释说明优先队列的行为
//用Collections.sort()更为自然,普通,推荐
static List heapSort(Collection c) {
Queue queue = new PriorityQueue(c);
List result = new ArrayList();
while (!queue.isEmpty())
result.add(queue.remove());
return result;
} Deque接口
通常和deck发音一样,一个Deque是一个双端队列。双端队列是元素的线性集合,支持在两个端点处插入和移除元素。Deque接口是比Stack 和Queue拥有更加丰富的抽象数据类型,因为它即实现了Stack又实现了Queue。Deque接口定义了在Deque实例两段处访问元素的方法。方法包括插入、移除、检索元素。预定义的类如ArrayDeque和LinkedList都实现了Deque接口。
注意到Deque接口可以被用作FIFO的队列,也可以用作LIFO的栈。Deque接口内的方法被分割成三部分。
插入
方法addFirst,offerFirst是在Deque实例前插入元素。方法addLast,offerLast是在Deque实例末尾插入元素。当Deque实例的容量是有限制的应当优先选择offerFirst和offerLast,因为其它两个方法可能会抛出异常。
移除
方法removeFirst,pollFirst是在Deque实例前移除元素。方法removeLast,pollLast是在Deque实例末尾移除元素。当Deque为空时,方法pollFirst和pollLast返回null,而其它两个方法会抛出异常。
检索
方法 getFirst 和peekFirst 是 Deque 实例检索首元素的方法. 不会从 Deque 实例中移除元素. 类似地, 方法 getLast 和peekLast是检索 末位元素. 如果 deque为empty,则方法 getFirst 和getLast 抛出异常,然而方法 peekFirst 和peekLast 却返回NULL.
以下总结出了12个插入、移除、检索Deque的方法:
操作类型 首元素 末元素
插入 `addFirst(e)` `addLast(e)`
`offerFirst(e)` `offerLast(e)`
移除 `removeFirst(e)` `removeLast(e)`
`pollFirst(e)` `pollLast(e)`
检索 `getFirst(e)` `getLast(e)`
`peekFirst(e)` `peekLast(e)`
除了以上的基本操作方法之外,Deque接口也提供了其它的方法,如removeFirstOccurence,这个方法是移除第一次存在于Deque接口内的元素,如果不存在,则Deque实例保持不变。类似的方法是removeLastOccurence,它是移除最后一次存在于Deque接口内的元素,如果存在则返回true,否则返回false.
Map接口
Map是将key映射到value的对象。Map不能包含两个一样的key,但是多个key可以映射到同一个value。Map接口包含基本的操作,例如put,get,remove,containskey,size,empty,批量操作,如putAll,clear。以及集合视图,如keySet,entrySet,values。
Java平台包含三种目的的Map实现:hashMap,TreeMap,LinkedHashMap.他们和Set接口类似。
本章节主要讨论Map接口。但首先先举几个jdk1.8的聚合操作例子。在面向对象的编程世界中,模拟真实世界的对象是普片的任务,因此将员工按照部门分组是合理的:
// Group employees by department
Map<Department, List<Employee>> byDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment));或者计算一个部门的工资:
// Compute sum of salaries by department
Map<Department, Integer> totalByDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.summingInt(Employee::getSalary)));或者统计学生成绩是否通过
// Partition students into passing and failing
Map> passingFailing = students.stream()
.collect(Collectors.partitioningBy(s -> s.getGrade()>= PASS_THRESHOLD)); 你也可以将人们以城市分组
// Classify Person objects by city
Map<String, List<Person>> peopleByCity
= personStream.collect(Collectors.groupingBy(Person::getCity));或者将集合按照城市和状态归类
// Cascade Collectors
Map<String, Map<String, List<Person>>> peopleByStateAndCity
= personStream.collect(Collectors.groupingBy(Person::getState,
Collectors.groupingBy(Person::getCity)))更深入的聚合操作和lambda表达式请看聚合操作章节。
Map接口的基本操作
Map的基本操作包括put,get,containsKey,containsValue,size和isEmpty,它的表现和Hashtable的一模一样。下面的代码统计入参出现的频率:
public class Freq {
public static void main(String[] args) {
Map m = new HashMap();
// Initialize frequency table from command line
for (String a : args) {
Integer freq = m.get(a);
m.put(a, (freq == null) ? 1 : freq + 1);
}
System.out.println(m.size() + " distinct words:");
System.out.println(m);
}
} 用到的诡计就是本程序中put语句的第二个参数。如果key存在,则为1,否则个数增加1。
//输入参数
if it is to be it is up to me to delegate
//输出
8 distinct words:
{to=3, delegate=1, be=1, it=2, up=1, if=1, me=1, is=2}如果想输出的顺序是按照字母表来的,那么输出如下:
8 distinct words:
{be=1, delegate=1, if=1, is=2, it=2, me=1, to=3, up=1}如果想要让输出保持输入的顺序,那么
8 distinct words:
{if=1, it=2, is=2, to=3, be=1, up=1, me=1, delegate=1}和Set、List一样,equals和hashCode方法也是必须的,这样Map才能任意类型情况下判断两个map实例是否相等。假如两个map实例的key和value映射一模一样,则这两个map实例逻辑相等。
一个栗子,k,v是Map的实现类型,而m是一个和Map
Map<K, V> copy = new HashMap<K, V>(m);Map接口的批量操作
//清空Map
clear
//dumping one Map into another
putAll
//如果入参为空则使用默认值,否则使用入参覆盖默认值
static <K, V> Map<K, V> newAttributeMap(Map<K, V>defaults, Map<K, V> overrides) {
Map result = new HashMap(defaults);
result.putAll(overrides);
return result;
} 集合视图Collection views
集合视图即是可以使Map用Collection方式来展示:
keySet—Map内key的集合。values—Map内value的Collection,不是set,因为value可能有重复值。entrySet—Map内key-value对的集合,Map内嵌入一个Map.Entry的接口。
集合视图的唯一目的是迭代Map:
//遍历key
for (KeyType key : m.keySet())
System.out.println(key);
// Filter a map based on some
// property of its keys.
for (Iterator it = m.keySet().iterator(); it.hasNext(); )
if (it.next().isBogus())
it.remove();
for (Map.Entry e : m.entrySet())
System.out.println(e.getKey() + ": " + e.getValue()); 有些人担心,每次返回Map的集合视图都会实例化一个Collection,这大可放心,Map集合视图是单实例的。
有了这3个集合视图,那么在迭代的时候就可以进行移除操作。
有了entrySet视图,就可以通过Map.Entry的setValue进行修改值的操作。
collection视图提供几种移除元素的方法—remove,removeAll,retainAll和clear操作,此外还有Iterator.remove。
使用集合视图的原因:Map Algebra(代数)
第一个Map集合是否是否包含第二个Map集合
if (m1.entrySet().containsAll(m2.entrySet())) {
...
}两个Map集合内的key集合是否相等
if (m1.keySet().equals(m2.keySet())) {
...
}验证一个Map集合内的Key集合是否包含必填属性,并不包含非法属性
static boolean validate(Map attrMap, Set requiredAttrs, SetpermittedAttrs) {
boolean valid = true;
Set attrs = attrMap.keySet();
if (! attrs.containsAll(requiredAttrs)) {
Set missing = new HashSet(requiredAttrs);
missing.removeAll(attrs);
System.out.println("Missing attributes: " + missing);
valid = false;
}
if (! permittedAttrs.containsAll(attrs)) {
Set illegal = new HashSet(attrs);
illegal.removeAll(permittedAttrs);
System.out.println("Illegal attributes: " + illegal);
valid = false;
}
return valid;
} 共有key集合
SetcommonKeys = new HashSet(m1.keySet());
commonKeys.retainAll(m2.keySet()); 同理
//差集
m1.entrySet().removeAll(m2.entrySet());
m1.keySet().removeAll(m2.keySet());
多重映射Multimaps
一个key对应多个value,如Map
对象排序(Object Ordering)
一个列表可以通过以下方式进行排序:
Collections.sort(l)如果List由String元素构成,那么它将按照字母顺序进行排序。如果构成元素是Date,那么它将以时间顺序进行排序。String,Date都实现了Comparable接口。Comparable的实现类提供了自然排序的方法。下列表格列举了常见的实现了Comparable的接口。
实现了Comparable的类:
| 类名称 | 自然排序规则 |
|---|---|
Byte |
有符号数字(Signed numerical) |
Character |
无有符号数字(Unsigned numerical`) |
Long |
有符号数字(Signed numerical) |
Integer |
有符号数字(Signed numerical) |
Short |
有符号数字(Signed numerical) |
Double |
有符号数字(Signed numerical) |
Float |
有符号数字(Signed numerical) |
BigInteger |
有符号数字(Signed numerical) |
BigDecimal |
有符号数字(Signed numerical) |
Boolean |
Boolean.FALSE < Boolean.TRUE |
File |
按照名称排序,如何排序取决于系统的种类 |
String |
字典顺序 |
Date |
时间顺序 |
CollationKey |
取决于具体Locale的字典顺序 |
如果你尝试排序一个没有实现Comparable接口的类的实例集合,那么会报错,而不管你是使用Collections.sort(list) 还是使用Collections.sort(list) 。一个元素可以和另一个元素比较被称为相互可比(mutually comparable),虽然不同种类的元素可以进行相互比较,但是上表所列举的都禁止进行组间比较。
定制化对象排序
详情请点击我
值得借鉴的地方就是对比的地方,如下所示:
//三目运算符比较简洁,虽然看起来比较费劲
public int compareTo(Name n) {
int lastCmp = lastName.compareTo(n.lastName);
return (lastCmp != 0 ? lastCmp : firstName.compareTo(n.firstName));
}
//先对比是否相等,在对比大小 三目运算符是从左到右执行
public static int compare(long x, long y) {
return (x < y) ? -1 : ((x == y) ? 0 : 1);
}SortedSet接口
SortedSet是一个维护其内元素升序排序的集合(Set)。排序的方式是依据元素的自然排序(即实现Comparable接口)或者调用SortedSet构造函数时所传入的入参Comparator。除了普通的Set操作,SortedSet还提供了以下操作:
- 范围视图。允许在
SortedSet上执行任意范围的操作。 - 端点。返回
SortedSet首元素或者尾元素。 - 获取比较器
Comparator。如果有的话就返回。
SortedSet接口定义的方法如下:
public interface SortedSet<E> extends Set<E> {
// Range-view
SortedSet subSet(E fromElement, E toElement);
SortedSet headSet(E toElement); //截取指定元素之前的元素集合
SortedSet tailSet(E fromElement);
// Endpoints
E first();
E last();
// Comparator access
Comparator super E> comparator();
} SortedMap接口
同理SortedMap接口有如下方法:
public interface SortedMap<K, V> extends Map<K, V>{
Comparator super K> comparator();
SortedMap subMap(K fromKey, K toKey);
SortedMap headMap(K toKey);
SortedMap tailMap(K fromKey);
K firstKey();
K lastKey();
} 接口的总结
Collection的核心是Java集合框架的核心。
Java集合框架层次结构由两部分不同的接口树构成:
- 第一颗树以
Collection为起头,为所有继承或实现Collection提供了基本的操作,如add和remove。它的子接口有Set,List,Queue。 Set接口不允许有重复元素。子接口SortedSet为其内元素排好序。List接口提供插入有序的集合,当你需要精确控制每一个元素是使用它。你可以从指定位置检索List内的元素。Queue接口是FIFO,提供了额外的插入、提取和检查操作。Deque可支持FIFO,LIFO。可以在双端进行插入、提取和检查操作。- 第二颗树以
Map接口起头,和HashTable类似,将key映射到value。 Map的子接口SortedMap通过Comparator接口维持一个k-v升序的顺序。
聚合操作(Aggregate Operations)
请移步lambda表达式教程。