Day10.Kafka学习笔记
一、引言
- 什么是消息?
消息是系统间通信的载体,系统通讯(RPC)的介质,是分布式应用中不可或缺的一部分。
目前系统间发送消息的方式有两种:
①同步消息(即时消息),生产消费同时存在,必须建立会话;
②异步消息(离线消息),生产不关心消费,不必建立会话,消费者自行消费。 - 不同消息使用场景
即时消息:打电话,表单提交,webservice(soap),dubbo/springCloud
离线消息:发短息,发邮件,写信 —— 利用消息队列(队列特点FIFO) - 消息队列的使用场景 (三个常用)
异步:异步通信,可以并行处理些任务,提高效率,改进用户体验。
解耦:系统间解耦,生产或消费有一方宕机,不影响整体服务,即用户感受不到异样情况,后续恢复后,依然可以继续使用
削峰填谷:避免大量请求访问数据库;或者负载均衡,起到合理的调配服务
过滤:过滤敏感,不需要的消息
二、kafka
- Kafka是一种高吞吐量的分布式发布订阅消息系统。
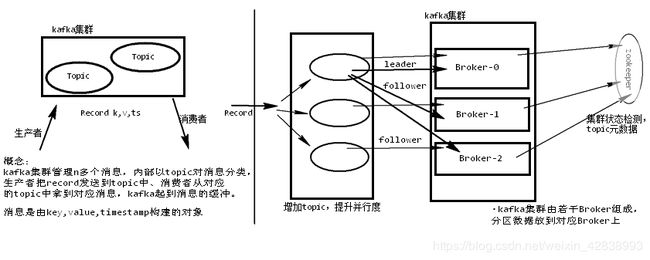
总结:
一个kafka的topic是以分区的形式存储在集群中,我们会给每个分区分配broker来当leader,同时也是其他分区的follower。一个broker可以是0~多个分区的leader,也可能是0~多个分区的follower
- 什么是集群脑裂?
集群的脑裂通常是发生在集群中部分节点之间不可达而引起的(或者因为节点请求压力较大,导致其他节点与该节点的心跳检测不可用)。当上述情况发生时,不同分裂的小集群会自主的选择出master节点,造成原本的集群会同时存在多个master节点。
三、名词解释
- Kafka的核心概念
| 名词 | 解释 |
|---|---|
| Producer | 消息的生成者 |
| Consumer | 消息的消费者 |
| ConsumerGroup | 消费者组,可以并行消费Topic中的partition的消息 |
| Broker | 缓存代理,Kafka集群中的一台或多台服务器统称broker. |
| Topic | Kafka处理资源的消息源(feeds of messages)的不同分类 |
| Partition | Topic物理上的分组,一个topic可以分为多个partion,每个partion是一个有序的队列。partion中每条消息都会被分 配一个 有序的Id(offset) |
| Message | 消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息 |
| Producers | 消息和数据生成者,向Kafka的一个topic发布消息的 过程叫做producers |
| Consumers | 消息和数据的消费者,订阅topic并处理其发布的消费过程叫做consumers |
- Producers的概念
①消息和数据生成者,向Kafka的一个topic发布消息的过程叫做producers
②Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;比如基于round-robin方式 或者通过其他的一些算法等;
③异步发送批量发送可以很有效的提高发送效率。kafka producer的异步发送模式允许进行批量发送,先将消息缓存到内存中,然后一次请求批量发送出去。 - broker的概念:
①Broker没有副本机制,一旦broker宕机,该broker的消息将都不可用。
②Broker不保存订阅者的状态,由订阅者自己保存。
③无状态导致消息的删除成为难题(可能删除的消息正在被订阅),Kafka采用基于时间的SLA(服务保证),消息保存一定时间(通常7天)后会删除。
④ 消费订阅者可以rewind back到任意位置重新进行消费,当订阅者故障时,可以选择最小的offset(id)进行重新读取消费消息 - Message组成
①Message消息:是通信的基本单位,每个producer可以向一个topic发布消息。
②Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的,每个topic又可以分成不同的partition每个partition储存一部分
③partion中的每条Message包含以下三个属性:
| offset | long |
|---|---|
| MessageSize | int32 |
| data | messages的具体内容 |
- Consumers的概念
消息和数据消费者,订阅topic并处理其发布的消息的过程叫做consumers.
在kafka中,我们可以认为一个group是一个“订阅者”,一个topic中的每个partions只会被一个“订阅者”中的一个consumer消费,不过一个consumer可以消费多个partitions中的消息
注:
Kafka的设计原理决定,对于一个topic,同一个group不能多于partition个数的consumer同时消费,否则将意味着某些 consumer无法得到消息
四、kafka集群的搭建
-
kafka不需要Hadoop的配置,需要有一些基本的环境搭建。
安装jdk并配置环境变量、配置主机名和IP的映射关系、同步系统时钟、zookeeper集群并配置
-
启动三台机器的zookeeper服务,且正常启动
[root@CentOSX ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh start zoo.cfg
- 上传并解压
[root@CentOSX ~]# tar -zxf kafka_2.11-0.11.0.0.tgz -C /usr/
- 配置
[root@CentOSX ~]# vi /usr/kafka_2.11-0.11.0.0/config/server.properties
############################# Server Basics #########################
broker.id=0|1|2 #分别对应0、1、2
delete.topic.enable=true
############################# Socket Server Settings ################
listeners=PLAINTEXT://CentOSA|B|C:9092 #分别对应CentOSA、B、C
############################# Log Basics ############################
log.dirs=/usr/kafka-logs #tmp改成usr
############################# Log Retention Policy ##################
log.retention.hours=168 #消息缓存时间,默认168小时 一周
############################# Zookeeper #############################
zookeeper.connect=CentOSA:2181,CentOSB:2181,CentOSC:2181
- 启动kafka集群
[root@CentOSX ~]# cd /usr/kafka_2.11-0.11.0.0/
[root@CentOSX kafka_2.11-0.11.0.0]# ./bin/kafka-server-start.sh -daemon config/server.properties
- 关闭kafka集群
不支持,直接关闭,需要修改下。(将PIDS= 后面的内容修改如下)
[root@CentOSX kafka_2.11-0.11.0.0]# ./bin/kafka-server-start.sh -daemon config/server.properties
[root@CentOSA kafka_2.11-0.11.0.0]# vi bin/kafka-server-stop.sh
PIDS=$(jps | grep Kafka | awk '{print $1}')
if [ -z "$PIDS" ]; then
echo "No kafka server to stop"
exit 1
else
kill -s TERM $PIDS
fi
- Kafka测试
//创建分区
[root@CentOSA kafka_2.11-0.11.0.0]# ./bin/kafka-topics.sh --create --zookeeper CentOSA:2181,CentOSB:2181,CentOSC:2181 --topic topic01 --partitions 3 --replication-factor 3
//启动消费者
[root@CentOSB kafka_2.11-0.11.0.0]# ./bin/kafka-console-consumer.sh --bootstrap-server CentOSA:9092,CentOSB:9092,CentOSC:9092 --topic topic01 --from-beginning
//启动生产者
[root@CentOSC kafka_2.11-0.11.0.0]# ./bin/kafka-console-producer.sh --broker -list CentOSA:9092,CentOSB:9092,CentOSC:9092 --topic topic01
> hello kafka
五、Topic的基本操作
- 创建topic
[root@CentOSA kafka_2.11-0.11.0.0]# ./bin/kafka-topics.sh --create --zookeeper CentOSA:2181,CentOSB:2181,CentOSC:2181 --topic topic01 --partitions 3 --replication-factor 3
partitions:分区的个数,replication-factor副本因子
- 查看topic详情
[root@CentOSA kafka_2.11-0.11.0.0]# ./bin/kafka-topics.sh --describe --zookeeper CentOSA:2181,CentOSB:2181,CentOSC:2181 --topic topic01
Topic:topic01 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: topic01 Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: topic01 Partition: 1 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: topic01 Partition: 2 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
# 副本集,leader和两个follower 备份集 正常情况:R=I
- 查看所有Topic
[root@CentOSA kafka_2.11-0.11.0.0]# ./bin/kafka-topics.sh --list --zookeeper CentOSA:2181,CentOSB:2181,CentOSC:2181
topic01
topic02
topic03
- 删除topic
[root@CentOSA kafka_2.11-0.11.0.0]# ./bin/kafka-topics.sh --delete --zookeeper CentOSA:2181,CentOSB:2181,CentOSC:2181 --topic topic03
Topic topic03 is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
- 修改Topic
[root@CentOSA kafka_2.11-0.11.0.0]# ./bin/kafka-topics.sh --alter --zookeeper CentOSA:2181,CentOSB:2181,CentOSC:2181 --topic topic02 --partitions 2
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
六、JavaAPI操作Kafka
注意:因为是在集群环境下,所以要在C:\Windows\System32\drivers\etc下hosts文件追加
192.168.153.139 CentOSA
192.168.153.140 CentOSB
192.168.153.141 CentOSC
1、 导入依赖
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>0.11.0.0version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.17version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.2version>
dependency>
- JavaAPI操作Topic管理
/**
* 管理kafka的Topic
* AdminClient
* Created by Turing on 2018/12/12 18:43
*/
public class KafkaAdminDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,"CentOSA:9092,CentOSB:9092,CentOSC:9092");
//AdminClient
AdminClient adminClient = KafkaAdminClient.create(props);
//创建Topic
Collection<NewTopic> topics=new ArrayList<NewTopic>();
topics.add(new NewTopic("topic01",3, (short) 3)); //3个分区,3个副本因子
topics.add(new NewTopic("topic02",3, (short) 3));
topics.add(new NewTopic("topic03",3, (short) 3));
ListTopicsResult listTopics = adminClient.listTopics();
KafkaFuture<Set<String>> names = listTopics.names();
for (String s : names.get()) {
System.out.println(s);
}
adminClient.close();
}
}
- 消费者
/**
* KafkaConsumer 消费者
* Created by Turing on 2018/12/12 18:59
*/
public class KafkaConsumerDemo {
public static void main(String[] args) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"CentOSA:9092,CentOSB:9092,CentOSC:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); //key 反序列化
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); //value 反序列化
props.put(ConsumerConfig.GROUP_ID_CONFIG,"g1"); //指定组
//Topic对消费者的消费形式,消费者以组的形式存在,组内消息某人消费了,其余人不会再消费它。
KafkaConsumer<String,String> kafkaConsumer= new KafkaConsumer<String, String>(props);
//订阅感兴趣的Topics
kafkaConsumer.subscribe(Arrays.asList("topic01"));
//获取Records
while(true){ //循环去消费
ConsumerRecords<String, String> records = kafkaConsumer.poll(1000); //每1秒获取数据一次
if(records!=null && records.count()>0){// if(records!=null && !records.isEmpty())
for (ConsumerRecord<String, String> record : records) {
String key=record.key();
String value=record.value();
long timestamp=record.timestamp();
int partition=record.partition(); //消息属于那个分区
long offset=record.offset(); //消息在分区的顺序
System.out.println(key+" : "+value+" timestamp:"+timestamp+" 分区:"+partition+" offset:"+offset);
}
}
}
}
}
- 生产者
/**
* KafkaProducer 生产者
* Created by Turing on 2018/12/12 19:05
*/
public class KafkaProducerDemo {
public static void main(String[] args) {
Properties props=new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"CentOSA:9092,CentOSB:9092,CentOSC:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); //key 序列化
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); //value 序列化
//创建生产者
KafkaProducer<String,String> kafkaProducer=new KafkaProducer<String, String>(props);
//创建消息
for(int i=1;i<10;i++){ //1~9
ProducerRecord<String,String> record=new ProducerRecord<String,String>("topic01","0"+i+"00","用户编号是"+i+" ,性别:"+(i%2));
//发布消息
kafkaProducer.send(record);
}
//flush
kafkaProducer.flush();
//关闭生产者
kafkaProducer.close();
}
}
- 如何在消息系统中传递对象
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>3.7version>
dependency>
public class ObjectSerializer implements Serializer<Object> {...}
public class ObjectDeserializer implements Deserializer<Object> {...}
//①自己的类implements Serializable
public class User implements Serializable
//②两个自定义序列化
public class ObjectSerializer implements Serializer<Object> {
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
}
@Override
public byte[] serialize(String topic, Object data) {
return SerializationUtils.serialize((Serializable) data);
}
@Override
public void close() {
}
}
public class ObjectDeserializer implements Deserializer<Object> {
@Override
public void configure(Map<String, ?> configs, boolean isKey) {
}
@Override
public Object deserialize(String topic, byte[] data) {
return SerializationUtils.deserialize(data);
}
@Override
public void close() {
}
}
//③在生产者和消费者中序列化和反序列化用自定义的类
//Consumer中
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, ObjectDeserializer.class);
//Producer中
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, ObjectSerializer.class);
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, DefaultPartitioner.class);
- 生产者发送消息的负载均衡策略
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, XxxPartitioner.class);//自定义
public class XxxPartitioner implements Partitioner {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
//自定义你想要的分区规则
return hash(key)%分区数;
}
public void close() {}
}
- 消费订阅两种形式
KafkaConsumer<String,User> consumer=new KafkaConsumer<String, User>(config);
//订阅topic
consumer.subscribe(Arrays.asList("topic02"));
必须设置
消费组,可以实现组内消费者的rebalance
TopicPartition p1 = new TopicPartition("topic02", 0);
List<TopicPartition> topicPartitions = Arrays.asList(p1);
consumer.assign(topicPartitions);
consumer.seek(p1,2);
手动设置offset偏移量
七、了解Kafka Stream(kafka流式计算)
示例:实时统计字符中单词数
- 依赖
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-streamsartifactId>
<version>0.11.0.0version>
dependency>
- admin
public class KafkaAdminDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,"CentOSA:9092,CentOSB:9092,CentOSC:9092");
//AdminClient
AdminClient adminClient = KafkaAdminClient.create(props);
//创建Topic
Collection<NewTopic> topics=new ArrayList<NewTopic>();
topics.add(new NewTopic("TextLinesTopic",3, (short) 3)); //输入
topics.add(new NewTopic("WordsWithCountsTopic",3, (short) 3)); //输出
adminClient.createTopics(topics);
ListTopicsResult listTopics = adminClient.listTopics();
KafkaFuture<Set<String>> names = listTopics.names();
for (String s : names.get()) {
System.out.println(s);
}
adminClient.close();
}
}
- 数据处理逻辑——java7
public class KafkaStreamingDemoJava7 {
public static void main(String[] args) {
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "CentOSA:9092,CentOSB:9092,CentOSC:9092");
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> textLines = builder.stream("TextLinesTopic");
// 001 hello world
// 001 hello
// 001 world
KTable<String, Long> wordCounts = textLines
.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String line) {
return Arrays.asList(line.split(" "));
}
})
.groupBy(new KeyValueMapper<String, String, String>() {
@Override
public String apply(String key, String value) {
return value;
}
})
.count("Counts");
wordCounts.to(Serdes.String(), Serdes.Long(), "WordsWithCountsTopic");
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}
}
- 数据处理逻辑——java8
一个接口只有一个方法,我们称为函数接口,适用于lambda 表达式
public class KafkaStreamingJavaJava8 {
public static void main(String[] args) {
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "CentOSA:9092,CentOSB:9092,CentOSC:9092");
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> textLines = builder.stream("TextLinesTopic");
KTable<String, Long> wordCounts = textLines
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split(" ")))
.groupBy((key, word) -> word)
.count("Counts");
wordCounts.to(Serdes.String(), Serdes.Long(), "WordsWithCountsTopic");
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}
}
- 消费者Consumer
public class KafkaConsumerDemo {
public static void main(String[] args) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"CentOSA:9092,CentOSB:9092,CentOSC:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG,"g2");
KafkaConsumer<String,Long> kafkaConsumer= new KafkaConsumer<String, Long>(props);
//订阅感兴趣的Topics
kafkaConsumer.subscribe(Arrays.asList("WordsWithCountsTopic"));
//获取Records
while(true){
ConsumerRecords<String, Long> records = kafkaConsumer.poll(1000);
if(records!=null && records.count()>0){
for (ConsumerRecord<String, Long> record : records) {
String key=record.key();
Long value=record.value();
System.out.println(key+" : "+value);
}
}
}
}
}
- 测试
[root@CentOSA kafka_2.11-0.11.0.0]# ./bin/kafka-console-producer.sh --broker-list CentOSA:9092,CentOSB:9092,CentOSC:9092 --topic TextLinesTopic
八、总结
- 消息队列的使用场景(3个)
异步、解耦、削峰填谷 - kafka架构图
- 基于API操作
- 消息队列,组内均分,组间广播