R语言-推荐系统:基于电影评分的推荐系统
R语言-推荐系统:基于电影评分的推荐系统
评分系统是一种常见的推荐系统。可以使用R/PYTHON等语言基于协同过滤算法来构建一个电影评分预测模型。学习协同过滤算法、UBCF和IBCF。本实验目标为,实现一个基于电影评分的推荐系统,以此来根据用户的评分历史来为其推荐喜欢的电影,做出有效的电影推荐。
实验前推荐先阅读一些相关书籍或资料,例如电影评分预测模型、推荐系统实践等等。
数据准备:
1.R语言包:ggplot2包、recommenderlab包、eshape包(数据处理)。在recommenderlab包里面,针对realRatingMatrix数据类型,总共提供了6种模型,分别是:基于项目协同过滤(IBCF), 主成分分析(PCA), 基于流行度推荐(POPULAR),随机推荐(RANDOM),奇异值分解(SVD),基于用户协同过滤算法(UBCF)。
2.获取数据ml-100k:明尼苏达州大学的社会化计算研究中心官网上面下载这些免费数据集,网站链接为http://grouplens.org/datasets/movielens/。本实验使用数据为ml-100k。
数据预处理:
由于数据源本身并没有很大问题,所以只是进行了简单的处理并进行了EDA。同样是利用ggplot2包进行画图,对数据分布有更好的了解。
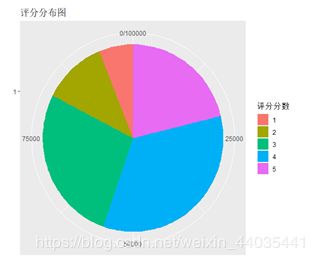
读取数据后,将多余数据删除,将数据分为用户ID,电影ID,电影评分,代码如下。电影评分为本次实验重点,通过饼图可看出用户给出三星和四星的情况最大,一星和二星的情况最少。其中三星、四星的个数记起来占全部评分的75%左右。用户关于电影的评分呈较明显的左偏分布。这说明用户对电影的评分通常较高,若新电影评分低于3.5时就可能已经失去了一半观众。
利用cast函数将数据转换为以用户为行、电影为列的评分矩阵,再将包含数据序号的列删除,最后可得分析所需的电影评分矩阵。之后使用recommenderlab包将数据转换为recommenderlab包所能使用的类型。
#读取数据
m1100k <- read.table("C:\\Users\\asus\\Documents\\1\\u.data",header = F,
stringsAsFactors = T)
#指定不读取表头,指定表中的列不是因子即数据型数据。
head(m1100k)
m1100k <- m1100k[,-4]
head(m1100k)
library(ggplot2)
#直方图
ggplot(m1100k, aes(x=V3)) + geom_histogram(binwidth = 0.09,color="grey")+labs(x="电影评分",title = "电影评分统计")
#饼图
ggplot(m1100k,x=V3,aes(x=factor(1),fill=factor(V3)))+geom_bar(width = 1)+
coord_polar(theta="y")+ggtitle("评分分布图")+
labs(x="",y="")+
guides(fill=guide_legend(title = '评分分数'))
library(reshape)
m1100k <- cast(m1100k, V1~V2, value="V3")
m1100k[1:3,1:6]
m1100k <- m1100k[,-1]
m1100k[1:3,1:6]
#查看类型并修改数据类型
class(m1100k)
class(m1100k) <- "data.frame"
library(recommenderlab)
m1100ka <- as.matrix(m1100k)
m1100kb <- as(m1100ka,"realRatingMatrix")建立推荐模型:
数据源评分矩阵是一个非常稀疏、含有许多空缺值的矩阵。协同过滤主要分为两个步骤,首先依据目标用户的已知电影评分找到与目标用户观影风格相似的用户群,然后计算该用户群对其他电影的评分,并作为目标用户的预测评分。评分矩阵的稀疏性并不影响协同过滤的工作效果,因此协同过滤较为和合适建立评分预测模型。
colnames(m1100kb) <- paste("M",1:1682, sep = "")
as(m1100kb, "matrix")[1:3,1:10]
# recommender函数,一指定使用前800条数据建模,二指定方法为“基于用户的协同过滤”
m1100k.model <- Recommender(m1100kb[1:800],method="UBCF")
#使用predict函数进行预测,一指定模型,二指定对801-803个用户进行预测,三指定预测类型为rating,即预测评分
ml.predict <- predict(m1100k.model, m1100kb[801:803],type="ratings")
as(ml.predict, "matrix")[1:3,1:6]
#由于predict函数默认预测类型即为topNList类型,因此无须再指定参数type,只需指定5,表示为每个用户推荐最佳的5部电影。
m1.predict2 <- predict(m1100k.model,m1100kb[801:803], n=5)
#在m1.predict2中存储的是三个用户最可能喜爱的5部电影,返回这些电影名称
as(m1.predict2,"list")
# 以上,要注意数据类型的转换模型的评估
对于评分预测模型的评估,最经典的参数是 RMSE(均平方根误差),另外还有均方误差(MSE和平均绝对误差(MAE)。通过构建多个预测模型,比较不同模型之间的优劣。其中的模型分别为基于项目协同过滤(IBCF)、主成分分析(PCA)、随机推荐(RANDOM)、奇异值分解(SVD)和基于用户协同过滤(UBCF)。
模型的评估,首先将原始数据分为训练集和测试集。其次测试集再拆分为know和unknown两部分。
know存放电影和用户,unknown存放真实评分。
evaluationScheme是专门用于评估方案的函数。一指定全体数据,二指定模型评估时将训练集与测试集分开测试,三指定抽取数据集中的90%作为训练集,四指定测试集中的know部分的项目个数,五表示预测成功的最小评分。
RMSE MSE MAE
[1,] 1.398348 1.955378 1.1053382
[2,] 1.054882 1.112776 0.8491461
[3,] 1.369378 1.875197 0.9986559
[4,] 1.059674 1.122909 0.8529590
model.eval <- evaluationScheme(m1100kb[1:943], method="split",train=0.9, given=15, goodRating=4)
model.random <- Recommender(getData(model.eval,"train"),method="RANDOM")
model.ubcf <-Recommender(getData(model.eval,"train"), method="UBCF")
model.ibcf <- Recommender(getData(model.eval,"train"),method="IBCF")
model.svd <- Recommender(getData(model.eval,"train"),method="SVD")
model.pop <- Recommender(getData(model.eval,"train"),method="POP")
#对于这五个模型,使用getdata函数将model.eval中的train部分作为数据集传入recommenger函数中。
#后面则是获取获取eval中know存放的ID数据作为预测目标,预测评分。
predict.random <- predict(model.random, getData(model.eval, "know"),type="ratings")
predict.ubcf <- predict(model.ubcf, getData(model.eval, "know"),type="ratings")
predict.ibcf <- predict(model.ibcf, getData(model.eval, "know"),type="ratings")
predict.svd<- predict(model.svd, getData(model.eval, "know"),type="ratings")
predict.pop <-predict(model.pop, getData(model.eval,"know"), type="ratings")
predict()
#calcPredictionAccuracy函数计算两组数据的均方根方差(RESM)均方误差(MSE)平均绝对误差(MAE)
#度量两组数据的相似程度,误差越小则预测结构越接近真实结果,模型预测效果也越好。
error <- rbind(calcPredictionAccuracy(predict.random,getData(model.eval,"unknow")),
calcPredictionAccuracy(predict.ubcf,getData(model.eval,"unknow")),
calcPredictionAccuracy(predict.ibcf,getData(model.eval,"unknow")),
calcPredictionAccuracy(predict.svd,getData(model.eval,"unknow")),
calcPredictionAccuracy(predict.pop, getData(model.eval,"unknow")))
error
实验所使用的模型中,在RMSE、MSE、MAE这三种误差中,最准确的误差是RMSE,当不同误差指向的最佳模型不一致时,以RMSE为主。通过函数计算得出的误差可知,基于用户的协同过滤和奇异值分解都有较小的误差值,其中,基于用户的协同过滤又小于基于项目协同过滤。因此,基于用户的协同过滤更稠密、也更有效。随机推荐和基于项目协同过滤的误差值都较大,这三种推荐方法不适合本案例。
以本案例来说,基于电影评分的推荐系统使用基于用户的协同过滤模型更合、更有效。通过对用户数据进行分析,可实现为用户推荐可能喜欢的电影。