机器学习二十二:支持向量机回归SVR
AI
菌
在前四篇里面我们讲到了SVM的线性分类和非线性分类(核函数),以及在分类时用到的SMO算法。
这些都关注于SVM的分类问题。实际上SVM也可以用于回归模型,本篇就对如何将SVM用于回归模型做一个总结。
回归和分类从某种意义上讲,本质上是一回事。SVM分类,就是找到一个平面,让两个分类集合的支持向量或者所有的数据离分类平面最远;SVR回归,就是找到一个回归平面,让一个集合的所有数据到该平面的距离最近。
SVM回归模型的损失函数
回顾下我们前面SVM分类模型中,我们的目标函数是
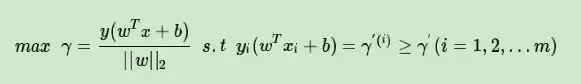
通常情况下我们令函数间隔γ′=为1。那么有:
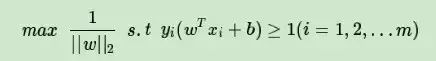
由于最大化:
![]()
等价于:
![]()
这样使拟合函数更为平坦,从而提高泛化能力
所以我们的目标函数变为:
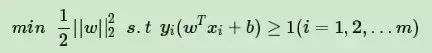
如果是加入一个松弛变量ξi≥0,则目标函数是
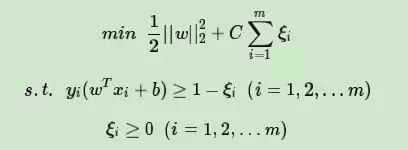
但是我们现在是回归模型,优化目标函数可以继续和SVM分类模型保持一致
但是约束条件呢?不可能是让各个训练集中的点尽量远离自己类别一边的的支持向量,因为我们是回归模型,没有类别。
对于回归模型,我们的目标是让训练集中的每个点(xi,yi) , 尽量拟合到一个线性模型yi =w∙ϕ(xi)+b 。对于一般的回归模型,我们是用均方差作为损失函数,但是SVM不是这样定义损失函数的。
SVM需要我们定义一个常量 ϵ>0,对于某一个点(xi,yi),如果
![]()
则完全没有损失,如果
![]()
则对应的损失为
![]()
这个均方差损失函数不同,如果是均方差,那么只要
![]()
也就是点不在拟合线段上时,那么就会有损失。
如下图所示,在蓝色条带里面的点都是没有损失的,但是外面的点的是有损失的,损失大小为红色线的长度。
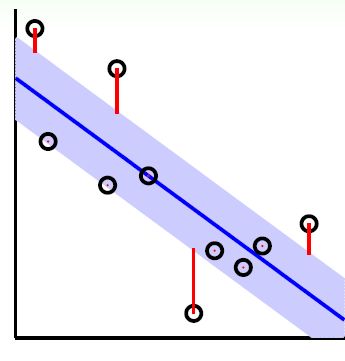
总结下,我们的SVM回归模型的损失函数度量为:
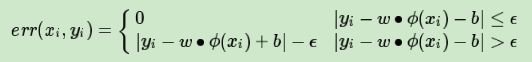
目标函数的原始形式
上一节我们已经得到了我们的损失函数的度量,现在可以可以定义我们的目标函数如下:
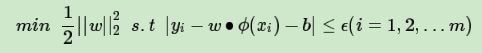
和SVM分类模型相似,回归模型也可以对每个样本(xi,yi)加入松弛变量ξi≥0,
但是由于我们这里用的是绝对值,实际上是两个不等式,我们定义为:
![]()
则我们SVM回归模型的损失函数度量在加入松弛变量之后变为:
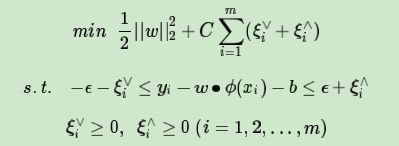
依然和SVM分类模型相似,常数C > 0
表示对超出误差 ε 的样本的惩罚程度,从而减小误差
我们可以用拉格朗日函数将目标优化函数变成无约束的形式,也就是拉格朗日函数的原始形式如下:
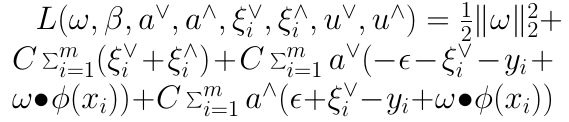
其中
![]()
均为拉格朗日系数
目标函数的对偶形式
上一节我们讲到了SVM回归模型的目标函数的原始形式,我们的目标是
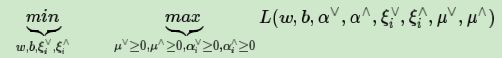
和SVM分类模型一样,这个优化目标也满足KKT条件,也就是说,我们可以通过拉格朗日对偶将我们的优化问题转化为等价的对偶问题来求解如下:
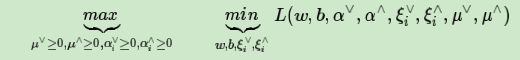
首先我们来求优化函数对于w,b,ξi∨,ξi∧的极小值,这个可以通过求偏导数求得:
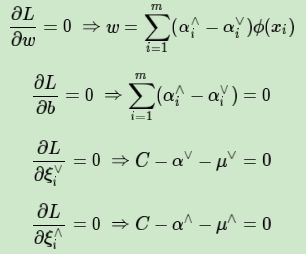
好了,我们可以把上面4个式子带入L(w,b,α∨,α∧,ξi∨,ξi∧,μ∨,μ∧)去消去w,b,ξi∨,ξi∧了
看似很复杂,其实消除过程和系列第一篇第二篇文章类似,由于式子实在是冗长,这里我就不写出推导过程了,最终得到的对偶形式为:
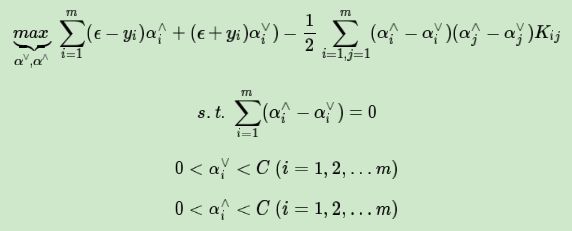
对目标函数取负号,求最小值可以得到和SVM分类模型类似的求极小值的目标函数如下:
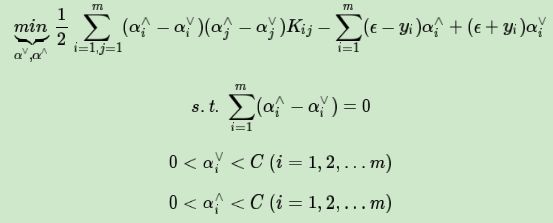
对于这个目标函数,我们依然可以用讲到过的SMO算法来求出对应的α∨,α∧,进而求出我们的回归模型系数w,b。
SVM 算法小结
这个系列终于写完了,这里按惯例SVM 算法做一个总结。SVM算法是一个很优秀的算法,在集成学习和神经网络之类的算法没有表现出优越性能前,SVM基本占据了分类模型的统治地位。目前则是在大数据时代的大样本背景下,SVM由于其在大样本时超级大的计算量,热度有所下降,但是仍然是一个常用的机器学习算法。
SVM算法的主要优点有:
1) 解决高维特征的分类问题和回归问题很有效,在特征维度大于样本数时依然有很好的效果。
2) 仅仅使用一部分支持向量来做超平面的决策,无需依赖全部数据。
3) 有大量的核函数可以使用,从而可以很灵活的来解决各种非线性的分类回归问题。
4)样本量不是海量数据的时候,分类准确率高,泛化能力强。
SVM算法的主要缺点有:
1) 如果特征维度远远大于样本数,则SVM表现一般。
2) SVM在样本量非常大,核函数映射维度非常高时,计算量过大,不太适合使用。
3)非线性问题的核函数的选择没有通用标准,难以选择一个合适的核函数。
4)SVM对缺失数据敏感。
AI
菌
之后会对scikit-learn中SVM的分类算法库和回归算法库做一个总结

不失初心,不忘初衷

AI玩转智能