机器学习十九:LinearSVM的软间隔最大化模型
AI
菌
在机器学习十八:支持向量机(LinearSVM)中,我们对线性可分SVM的模型和损失函数优化做了总结。
在解决线性可分数据集的分类问题时,求得拉格朗日乘子、w、b就得到分离超平面,然后就可以进行分类
最后我们提到了有时候不能线性可分的原因是线性数据集里面多了少量的异常点,由于这些异常点导致了数据集不能线性可分
本篇就对线性支持向量机如何处理这些异常点的原理方法做一个总结。
一 LinearSVM面临的问题
有时候本来数据的确是可分的,也就是说可以用 线性分类SVM的学习方法来求解,但是却因为混入了异常点,导致不能线性可分
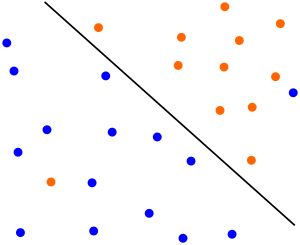
比如下图,本来数据是可以按下面的实线来做超平面分离的,可以由于一个橙色和一个蓝色的异常点导致我们没法按照线性支持向量机中的方法来分类。
另外一种情况没有这么糟糕到不可分,但是会严重影响我们模型的泛化预测效果
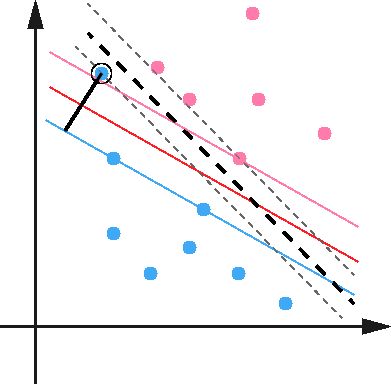
比如下图,本来如果我们不考虑异常点,SVM的超平面应该是下图中的红色线所示,但是由于有一个蓝色的异常点,导致我们学习到的超平面是下图中的粗虚线所示,这样会严重影响我们的分类模型预测效果
如何解决这些问题呢?SVM引入了软间隔最大化的方法来解决。
二 LinearSVM的软间隔最大化
所谓的软间隔,是相对于硬间隔说的,我们可以认为上一篇线性分类SVM的学习方法属于硬间隔最大化。
回顾下硬间隔最大化的条件:
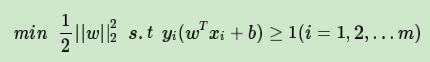
接着我们再看如何可以软间隔最大化呢?
SVM对训练集里面的每个样本 (xi,yi) 引入了一个松弛变量:
![]()
这使函数间隔加上松弛变量大于等于1,也就是说:
![]()
对比硬间隔最大化,可以看到我们对样本到超平面的函数距离的要求放松了,之前是一定要大于等于1,现在只需要加上一个大于等于0的松弛变量能大于等于1就可以了
当然,松弛变量不能白加,这是有成本的,每一个松弛变量ξi, 对应了一个代价ξi,这个就得到了我们的软间隔最大化的SVM学习条件如下:
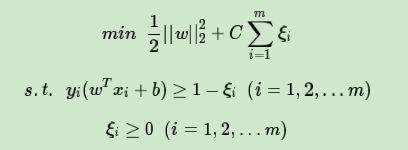
这里,C>0为惩罚参数,可以理解为我们一般回归和分类问题正则化时候的参数
C越大,对误分类的惩罚越大,C越小,对误分类的惩罚越小
也就是说,我们希望
![]()
尽量小,误分类的点尽可能的少
C是协调两者关系的正则化惩罚系数。在实际应用中,需要调参来选择。
三 目标函数的优化
和线性可分SVM的优化方式类似,我们首先将软间隔最大化的约束问题用拉格朗日函数转化为无约束问题如下:

其中 μi≥0,αi≥0,均为拉格朗日系数
也就是说,我们现在要优化的目标函数是:
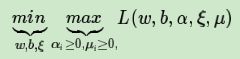
这个优化目标也满足KKT条件,也就是说,我们可以通过拉格朗日对偶将我们的优化问题转化为等价的对偶问题来求解如下:

我们可以先求优化函数对于w,b,ξ的极小值, 接着再求拉格朗日乘子α和 μ的极大值
首先我们来求优化函数对于w,b,ξ的极小值,这个可以通过求偏导数求得:
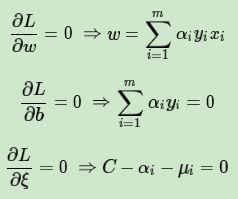
好了,我们可以利用上面的三个式子去消除w和b了:
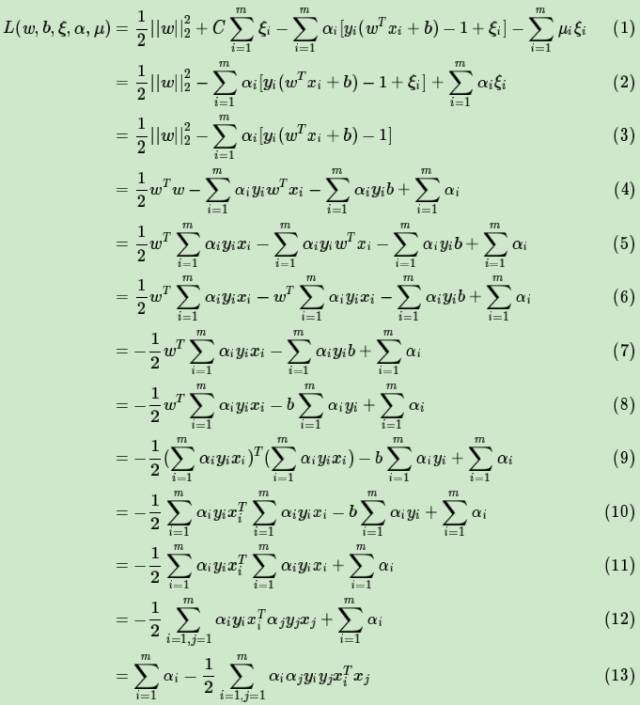
其中
(1)式到(2)式用到了
![]()
(2)式到(3)式合并了同类项
(3)式到(4)式用到了范数的定义
![]()
(4)式到(5)式用到了上面的
![]()
(5)式到(6)式把和样本无关的wT提前
(6)式到(7)式合并了同类项
(7)式到(8)式把和样本无关的b提前
(8)式到(9)式继续用到
![]()
(9)式到(10)式用到了向量的转置。由于常量的转置是其本身,所有只有向量xi被转置,
(10)式到(11)式用到了上面的

(11)式到(12)式使用了
![]()
的乘法运算法则
(12)式到(13)式仅仅是位置的调整
现在我们看看我们的优化目标的数学形式:
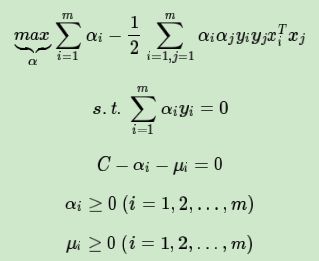
对于
![]()
这3个式子,我们可以消去μi,只留下αi,也就是说 0≤αi≤C 同时将优化目标函数变号,求极小值,如下:

和我们上一篇LinearSVM 的式子进行对比;
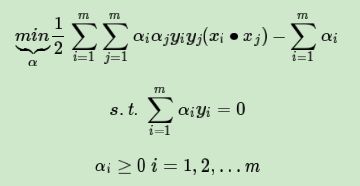
仔细观察可以发现,这个式子和我们上一篇线性可分SVM的一样,唯一不一样的是约束条件
仅仅是多了一个约束条件
![]()
我们依然可以通过SMO算法来求上式极小化时对应的α向量就可以求出和w和b了
四 软间隔最大化时的支持向量
在硬间隔最大化时,支持向量比较简单,就是满足函数间隔 γ′>1(举例取1,你也可以选择其他数值)
而函数间隔定义如下:
![]()
根据KKT条件中的对偶互补条件:
![]()
如果
![]()
则有
![]()
即点在支持向量上,否则如果
![]()
则有
![]()
即样本在支持向量上或者已经被正确分类
在软间隔最大化时,则稍微复杂一些,因为我们对每个样本 (xi,yi) 引入了松弛变量 ξi
我们从下图来研究软间隔最大化时支持向量的情况,第i个点到对应类别支持向量的距离为
![]()
根据软间隔最大化时KKT条件中的对偶互补条件
![]()
a) 如果α=0,那么yi(wTxi+b)−1≥0,即样本在支持向量上或者已经被正确分类。如图中所有远离支持向量的点
b) 如果0≤α≤C,那么ξi=0,yi(wTxi+b)−1=0,即点在支持向量上。如图中在虚线支持向量上的点
c) 如果α=C,说明这是一个可能比较异常的点,需要检查此时ξi
i)如果0≤ξi≤1,那么点被正确分类,但是却在超平面和自己类别的支持向量之间。如图中的样本2和4.
ii)如果ξi=1,那么点在分离超平面上,无法被正确分类。
iii)如果ξi>1,那么点在超平面的另一侧,也就是说,这个点不能被正常分类。如图中的样本1和3.

LinearSVM的算法过程总结
这里我们对软间隔最大化时的线性可分SVM的算法过程做一个总结
输入是线性可分的m个样本
![]()
其中x为n维特征向量。y为二元输出,值为1,或者-1
输出是分离超平面的参数和w∗和b∗和分类决策函数。
算法过程如下:
1)选择一个惩罚系数C>0, 构造约束优化问题

2)用SMO算法求出上式最小时对应的α向量的值α∗向量
3) 计算
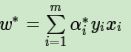
4) 找出所有的S个支持向量,即满足
![]()
对应的样本(xs,ys),通过

计算出每个支持向量(xx,ys)对应的bs∗,计算出这些

所有的bs∗对应的平均值即为最终的

这样最终的分类超平面为:w∗∙x+b∗=0,最终的分类决策函数为:
AI
菌
这里的模板都是通过设置布局背景来组合搭配的,需要调出布局设置来更换背景图片,使用定位功能可以改变大小

不失初心,不忘初衷

AI玩转智能