深度文本匹配发展总结
1、背景介绍
文本匹配是自然语言处理中的一个核心问题,很多自然语言处理的任务都可以抽象成文本匹配问题,例如信息检索可以归结成查询项和文档的匹配,问答系统可以归结为问题和候选答案的匹配,对话系统可以归结为对话和回复的匹配。针对不同的任务选取合适的匹配模型,提高匹配的准确率成为自然语言处理任务的重要挑战。
2、数据集介绍
论文中经常用到的数据集:
- SNLI:570K条人工标注的英文句子对,label有三个:矛盾、中立和支持
- MultiNLI:433K个句子对,与SNLI相似,但是SNLI中对应的句子都用同一种表达方式,但是MultiNLI涵盖了口头和书面语表达,可能表示形式会不同(Mismatched)
- Quora 400k个问题对,每个问题和答案有一个二值的label表示他们是否匹配
- WikiQA
是问题是相对应的句子的数据集,相对比较小。
3、模型发展过程
深度学习应用在文本匹配上可以总结为以下四个阶段:1、单语义模型,单语义模型只是简单的用全连接、CNN类或RNN类的神经网络编码两个句子然后计算句子之间的匹配度,没有考虑到句子中短语的局部结构。2、多语义模型,多语义模型从多颗粒的角度解读句子,考虑到和句子的局部结构。3、匹配矩阵模型,匹配矩阵模型更多的考虑待匹配的句子间不同单词的交互,计算两两之间的匹配度,再用深度网络提取特征,更精细的处理句子中的联系。4、深层次的句子间模型,这是近几年state of the art的模型,随着attention等交互机制论文的发表,最新的论文用更精细的结构去挖掘句子内和句子间不同单词之间的联系,得到更好的效果。
- 1、单语义模型
- 2、多语义模型
- 3、匹配矩阵模型
- 4、深层次的句间交互模型
前3类模型只简单挑选一篇作介绍,了解发展过程,重点介绍第4类最新的论文。
3.1 单语义模型
单语义模型最经典是DSSM,这是一篇2013年的文章,它有两个创新点,一个是用一种3个字母word hashing代替词袋模型,降低了单词向量的维度(由于当时word2vec论文还未发表),第二个是用全连接的神经网络处理句子,揭开深度文本匹配的篇章。
论文:Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
所谓的3个字母的word hashing就是先在单词上加上#表示符标记开头和结尾,例如#good#,然后每3个符号进行拆分,即变成#goo, goo, ood, od#,然后用multi-hot的形式表示这个单词,数据集的英语词汇可能会有很多(论文中的数据集有500K),而3个英语字符的组合相对数量比较少,可以穷尽。
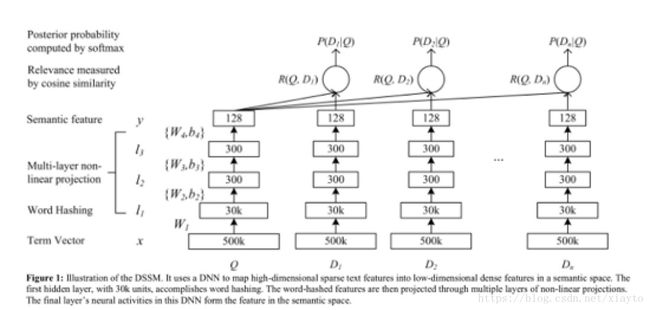
这是模型的结构图,输入Q是一个查询,D是各个候选文档,可以看到用词袋模型维度是500k,用word hashing 的方法可以将维度压缩到30k,然后通过全连接的神经网络对向量进行降维到128,接着两两计算余弦相似度得到匹配结果。
这个模型的缺陷在于:1、没有考虑到单词之间的时序联系,2、相似度匹配用的余弦相似度是一个无参的匹配公式。
3.2 多语义模型
多语义论文比较多,这里挑选一篇MV-LSTM作介绍。
论文:A Deep Architecture for Semantic Matching with Multiple Positional Sentence Representations
这篇论文采用双向LSTM处理两个句子,然后对LSTM隐藏层的输出进行两两计算匹配度,作者认为这是一个Multi-View(MV)的过程,能够考察每个单词在不同语境下的含义。同时用双向LSTM处理句子,相当于用变长的窗口逐步的解读句子,实现多颗粒度考察句子的效果。
这篇论文有3个创新点:1、使用了当时比较新型的双向LSTM模型,这种模型能考虑到句子的时序关系,能捕捉到长距离的单词依赖,而且采用双向的模型,能够减轻这种有顺序的模型权重偏向句末的问题。2、用Interaction tensor计算句子之间的两两匹配度,从多个角度解读句子。3、匹配计算公式采用了带参数的计算公式。
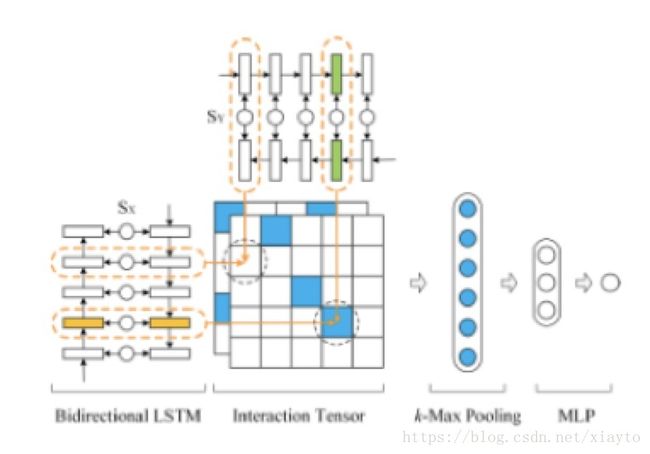
这是模型的结构图,用Bi-LSTM同时处理两个句子,每个单词节点会对应两个隐藏层的输出,用每个单词的输出进行单词间两两的相似度匹配计算,形成一个匹配矩阵,这里的相似度计算采用了带参数的公式:
因为语言的表示有多样性,带参数的公式比不带参数的公式显得更加合理,然后对匹配矩阵进行K-Max的动态池化操作,也就是挑选K个最大的特征,最后采用全连接层进行维度压缩和分类。
3.3 匹配矩阵模型
匹配矩阵模型挑选论文:Text Matching as Image Recognition
这篇论文从3个角度构建匹配矩阵,更精细的考虑句子间单词的两两关系,构建出3个矩阵进行叠加,把这些矩阵看作是图片,用卷积神经网络对矩阵进行特征提取。
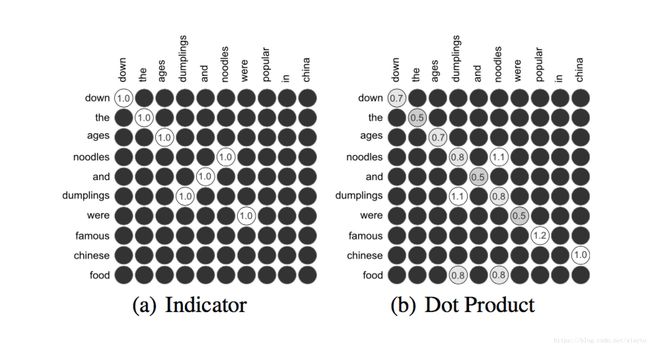
论文中一共有3种方式构建匹配矩阵,文中展示的是其中两种,Indicator是一个这个句子的单词是否在另一个句子中出现的指示矩阵,第二个是单词之间的点积,第三个是余弦相似度。三个匹配矩阵叠加再用CNN在矩阵上进行特征提取是这篇整体的思想。
3.4 深层次的句间交互模型
背景知识介绍:这些深层次的模型每个单词都是采用glove的预训练和characters卷积拼接作为单词的embedding输入。glove是类似于word2vec的词向量训练模型,word2vec是考虑单词上下文的局部信息,而glove用了全局的共现矩阵,同时考虑到了局部和整体的信息,characters卷积是对每个字母随机赋予一个向量,对单词的所有字母卷积得出特征作为单词的补充特征,这些特征是为了缓解OOV的问题,OOV就是训练集中出现了语料库中没出现过的单词。另外模型可能还会用到EM特征和POS特征,EM特征是excat match特征,就是这个单词在另一个句子中是否出现。POS是词性的特征,每个单词的词性作独热表示后纳入模型考虑。
3.4.1 BiMPM
Bilateral Multi-Perspective Matching for Natural Language Sentences
双边多角度句子匹配,这篇文章的创新点在于:1、双边,认为句子不应该仅仅考虑一个方向,从问句出发到答句,也应该从答句去反推问句。2、多角度,在考虑句子间的交互关系时采用了4种不同的方式。这篇文章发表在2017年的ijcai,模型取得了很好的效果,但是缺点在于参数很多,运算速度比较慢。

模型的整体框架图,输入是预训练的glove embeddings 和 chars embeddings,经过BiLSTM的编码之后,对每一个step的LSTM的输出进行从p到q和从q到p的两两配对,有四种组合方式,然后将所有的结果进行拼接和预测结果。

论文设计了4种匹配方式:
匹配的公式采用了带参数的余弦相似度:
(a) Full,是一个句子中的每个单词,更另外一个句子中最后一个隐藏层的输出作匹配,前向的LSTM是最后一个,后向的LSTM是第一个。
(b) Maxpooling,与另一个句子每一个隐藏层的输出作匹配,取最大值。
(c) Attentive,利用这个单词的embedding和另一个句子各个单词的embeddings分别计算余弦相似度,然后用softmax归一化做成attention权重,加权求和再进行带参余弦相似度计算。
(d) Max-Attentive,与Attentive相似,先计算出attention的权重,取其中权重最大的,做相似度匹配。
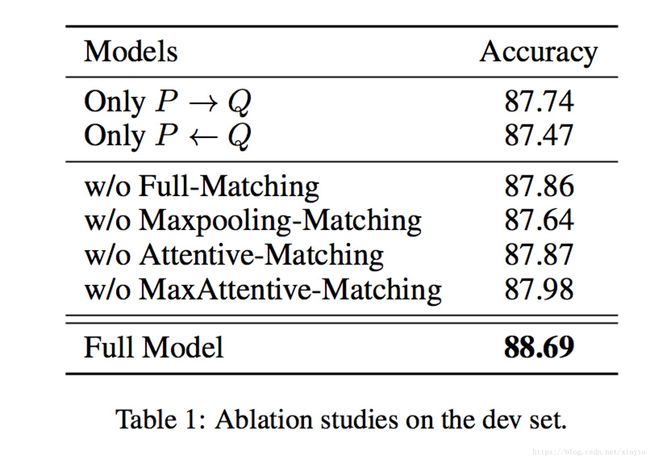
从这个实验结果可以看出,双边的操作,和4种匹配方式都分别起到了作用,他们组合在一起得到最好的实验效果。
3.4.2 DIIN
Natural Language Inference over Interaction Space
这篇论文的创新点在于考虑到了同句间不同单词之间的交互关系,另外就是模型中采用了2016年CVPR的best paper的model DenseNet。DenseNet可以在经过复杂的深度神经网络之后,还可以很大程度上保留原始特征的信息。

这是模型的整体框架图,可以看到模型的输入有4个部分的特征,就是背景介绍中的4个。然后用highway network对特征进行编码,这个编码的输出构造一个句子内的attention,具体就是里面的公式 α(a,b) α ( a , b ) ,对单词a和单词b的向量和它们的点积进行拼接,再做一个线性的映射得到一个权重参数,经过softmax归一化后成为句内attention的权重参数,然后是参考了LSTM的设计,对highway出来的向量和带了句内交互的attention项的向量用门机制进行了过滤,得到每个单词的向量表示,然后将向量表示两两之间做一个匹配形成匹配矩阵,最后用DenseNet对匹配矩阵进行特征提取。
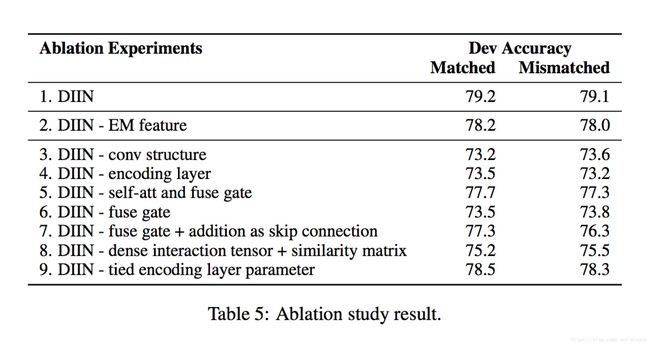
这个实验可以看到模型的各个部件都起到了作用,还有起到作用的大小程度。
3.4.3 DRCN
Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information
这篇论文的创新点在于:1、采用了固定的glove embedding和可变的glove embedding拼接并提升了模型效果。2、采用stack层级结构的LSTM,在层级结构上加入了DenseNet的思想,将上一层的参数拼接到下一层,一定程度上在长距离的模型中保留了前面的特征信息。3、由于不断的拼接导致参数增多,用autoencoder进行降维,并起到了正则化效果,提升了模型准确率。
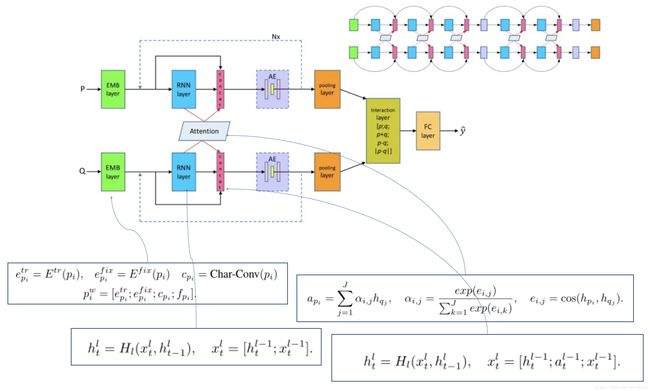
模型的输入是可变的glove向量和非可变的glove向量,chars卷积特征和一些标示特征(例如EM特征),然后经过BiLSTM对每个单词的特征编码,同时这里会加入attention机制考虑两个句子间的交互关系,计算隐藏层输出余弦相似度,softmax归一化成attention权重,加权求和后得到attention的向量,当前的单词特征向量、attention的向量、上一层的LSTM该step隐藏层输出向量同时作为当前step的输入,然后采用stack LSTM的结构叠加多层LSTM,论文中一个叠加了5层,随着层数的增加,每一层step的输入会越来越大,所以在最后两层加入了autoencoder对参数进行降维,最后用全连接网络进行预测。

这个实验可以看到各个部件起到的作用。
4、DIIN在中文数据集上测试
https://github.com/xiayto/DIIN_for_ccks
这里是用wiki的中文语料库用word2vec训练字向量,然后进行匹配,同时进行了附近中文字的卷积操作补充了局部结构的特征,对char卷积特征和EM特征的加入效果作了比较,但是由于POS词性特征需要分词和重新训练语料库,没有加入,有兴趣的朋友可以分词之后再对句子进行编码,加入POS特征可能可以取得更好的效果。
附:从pdf中提取文字,训练中文word2vec小工具
https://github.com/xiayto/word2vec
5、工程应用上的思考
- 1、虽然深度学习能够很大的提高匹配的准确率,但是同时也需要很长的计算时间,对话过程中长时间的等待会很大的降低用户体验,根据任务场景选择模型显得比较重要。
- 2、不是所有的数据集都有大量标注好的句子让模型训练,如何用迁移学习的方法,用大数据集的模型提升小数据集的模型效果,或者用半监督、无监督的方法提升模型效果、或者对数据集进行数据增强是后面要接着研究的方向。
参考文献:
1、DSSM : Learning deep structured semantic models for web search using clickthrough data, PS Huang et al.
2、ARC:Convolutional Neural Network Architectures for Matching Natural Language Sentences, B Hu et al.
3、MV-LSTM : A Deep Architecture for Semantic Matching with Multiple Positional Sentence Representations, S Wan et al
4、MatchPyramid:Text Matching as Image Recognition, L pang et al.
5、BiMPM:Bilateral Multi-Perspective Matching for Natural Language Sentences, Z Wang et al.
6、DIIN:Natural Language Infefence Over Interaction space, Y Gong et al.
7、DRCN:Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information, S Kim et al.