Hadoop(五)————Zookeeper以及HA(高可用全分布式集群搭建)
1、什么是Zookeeper




Broadcast模式极其类似于分布式事务中的2pc(two-phrase commit 两阶段提交):即leader提起一个决议,由followers进行投票,leader对投票结果进行计算决定是否通过该决议,如果通过执行该决议(事务),否则什么也不做。


首先看一下选举的过程,zk的实现中用了基于paxos算法(主要是fastpaxos)的实现。具体如下;此外恢复模式下,如果是重新刚从崩溃状态恢复的或者刚启动的的server还会从磁盘快照中恢复数据和会话信息。(zk会记录事务日志并定期进行快照,方便在恢复时进行状态恢复),选完leader以后,zk就进入状态同步过程。





znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的集中管理,集群管理,分布式锁等等。

znode 可以是临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除,Zookeeper 的客户端和服务器通信采用长连接方式,每个客户端和 服务器通过心跳来保持连接,这个连接状态称为 session,如果 znode 是临时节点,这个 session 失效,znode 也就删除了;持久化目录节点,这个目录节点存储的数据不会丢失;顺序自动编号的目录节点,这种目录节点会根据当前已近存在的节点数自动加 1,然后返回给客户端已经成功创建的目录节点名;临时目录节点,一旦创建这个节点的客户端与服务器端口也就是 session 超时,这种节点会被自动删除;临时自动编号节点。





znode以某种方式发生变化时,“观察”(watch)机制可以让客户端得到通知。可以针对ZooKeeper服务的“操作”来设置观察,该服务的其他 操作可以触发观察。比如,客户端可以对某个客户端调用exists操作,同时在它上面设置一个观察,如果此时这个znode不存在,则exists返回 false,如果一段时间之后,这个znode被其他客户端创建,则这个观察会被触发,之前的那个客户端就会得到通知。如果发生session close、authFail和invalid,那么所有类型的wather都会被触发
2、Zookeeper的搭建
2.1 上传zk安装包并解压(所使用的是zookeeper-3.4.5)
2.2 配置
现在一台节点上配置,然后通过scp命令将配置好的zookeeper-3.4.5直接复制到其他节点上即可。
1、在解压zookeeper-3.4.5的目录中进入到配置文件目录:cd zookeeper/conf
2、重命名配置文件:mv zoo_sample.cfg zoo.cfg
3、修改配置文件:vi zoo.cfg
dataDir=/home/hadoop/app/zookeeper-3.4.5/data
server.1=Slave5:2888:3888
server.2=Slave6:2888:3888
server.3=Slave7:2888:3888
修改完配置文件保存
4、在(dataDir=/home/hadoop/app/zookeeper-3.4.5/data)创建一个myid文件,里面内容是server.N中的N(server.2里面内容为2)
5、将配置好的zk拷贝到其他节点
scp -r /app/zookeeper-3.4.5/ Slave5:/app/
scp -r /app/zookeeper-3.4.5/ Slave6:/app/
scp -r /app/zookeeper-3.4.5/ Slave7:/app/
6、注意:在其他节点上一定要修改myid的内容
在Slave5应该讲myid的内容改为2 (echo "5" > myid)
在Slave6应该讲myid的内容改为3 (echo "6" > myid)
在Slave7应该讲myid的内容改为3 (echo "7" > myid)
7、启动集群
分别在Slave5 Slave6 Slave7上启动zk
./zkServer.sh start
通过jps命令查看进程
有这个QuorumPeerMain存在则说明启动成功
./zkServer.sh status可查看该节点的角色(如果出错可根据zookeeper-3.4.5\bin目录下zookeeper.out日志信息进行排错)3、HA
3.1 HA架构
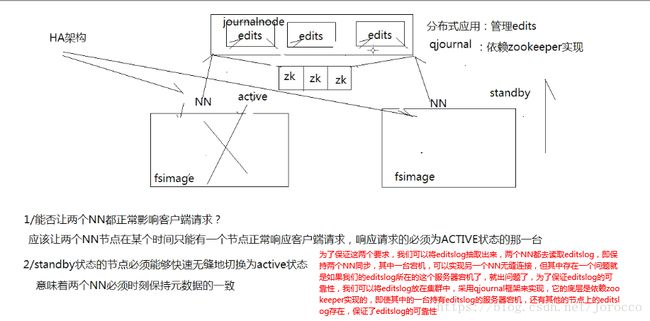
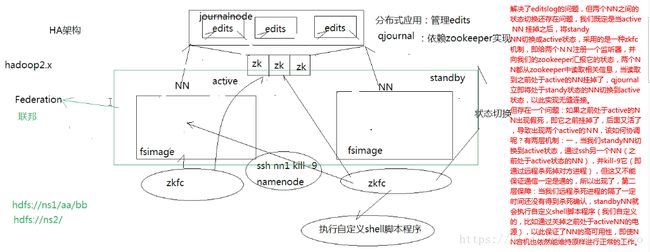
3.2 HA应用案例
3.3 HA高可用集群搭建
1、节点安排
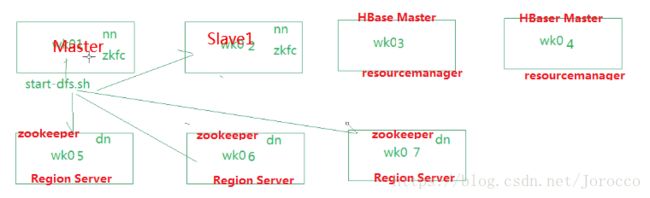
2、集群之间的远程通信配置及规划
远程通信免密登陆配置
进入每个节点上的~/.ssh目中删除所有文件,清洗干净再进行远程通信配置。
在能远程登陆其他机器的节点上,如Master节点上进行如下操作:
生成一对钥匙:ssh-keygen -t rsa
将公钥分别复制到Slave1 Slave3 Slave4 Slave5 Slave6 Slave7
ssh-coyp-id -i Slave1
ssh-coyp-id -i Slave3
ssh-coyp-id -i Slave4
ssh-coyp-id -i Slave5
ssh-coyp-id -i Slave6
ssh-coyp-id -i Slave7
这样在Master上就能免密登陆Slave1 Slave3 Slave4 Slave5 Slave6 Slave7机器
使用:
ssh Slave1
ssh Slave3
ssh Slave4
ssh Slave5
ssh Slave6
ssh Slave7
分别进行测试
exit命令退出远程的机器,回到Master机器上。集群之间的规划安排

说明:
在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态。
3、集群配置
小技巧:在Master节点上将所有的配置配置好之后然后通过远程通信将配置好的JDK、Hadoop、Zookeeper复制到其他机器上。(PS:如果很清楚如何规划的化,其实也可以先将一台机器完全配置好之后,然后再将该台机器进行克隆出其他几台机器,这样就只需要修改一下主机名、配置IP地址、和IP映射以及修改一下作为zookeeper的3台机器的zoo.cfg和data下的myid就可以了)
3.1 安装配置Hadoop集群(使用的是Hadoop-2.4.1,JDk1.7)
2.1解压
tar -zxvf hadoop-2.2.0.tar.gz -C /Master/
2.2配置HDFS(hadoop2.0所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下)
#将hadoop添加到环境变量中
vim /etc/profile
export JAVA_HOME=/home/hadoop/app/java/jdk1.7.0_55
export HADOOP_HOME=/Master/hadoop-2.2.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
(如果需要配置在任意目录下都能启动hadoop或zookeeper等集群,可以在最后一个路径后面将那些命令所在的路径加进去比如:$HADOOP_HOME/sbin,因为start-dfs.sh等命令都在sbin下面,所以将其加入到路径里面就可以在任意目录下执行start-dfs.sh命令了)
#hadoop2.0的配置文件全部在$HADOOP_HOME/etc/hadoop下
cd /itcast/hadoop-2.2.0/etc/hadoop
2.2.1修改hadoo-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65
2.2.2修改core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://ns1/value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/app/hadoop-2.4.1/tmp/value>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>Slave5:2181,Slave6:2181,Slave7:2181value>
property>
configuration>
2.2.3修改hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservicesname>
<value>ns1value>
property>
<property>
<name>dfs.ha.namenodes.ns1name>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn1name>
<value>Master:9000value>
property>
<property>
<name>dfs.namenode.http-address.ns1.nn1name>
<value>Master:50070value>
property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2name>
<value>Slav1:9000value>
property>
<property>
<name>dfs.namenode.http-address.ns1.nn2name>
<value>Slav1:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://Slave4:8485;Slave5:8485;Slave6:8485/ns1value>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/home/hadoop/app/hadoop-2.4.1/journaldatavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.ns1name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>
sshfence
shell(/bin/true)
value>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/root/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>30000value>
property>
configuration
2.2.4修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
2.2.5修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>yrcvalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>Slave3value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>Slave4value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>Slave5:2181,Slave6:2181,Slave7:2181value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
2.2.6修改slaves文件(slaves是指定子节点的位置,因为要在Master上启动HDFS、在Slave3启动yarn,所以Master上的slaves文件指定的是datanode的位置,Slave3上的slaves文件指定的是nodemanager的位置)
slave5
slave6
slave7
2.3配置免密码登陆
#首先要配置Master到Slave1、Slave3、Slave4、Slave5、Slave6 Slave7的免密码登陆
#在Master上生产一对钥匙
ssh-keygen -t rsa
#将公钥拷贝到其他节点,包括自己
ssh-coyp-id Slave1
ssh-coyp-id Slave3
ssh-coyp-id Slave4
sh-coyp-id Slave5
ssh-coyp-id Slave6
ssh-coyp-id Slave7
#配置Slave3到Slave5、Slave6 、Slave7的免密码登陆
#在Slave3上生产一对钥匙
ssh-keygen -t rsa
#将公钥拷贝到其他节点
ssh-coyp-id Slave5
ssh-coyp-id Slave6
ssh-coyp-id Slave7
#注意:两个namenode之间要配置ssh免密码登陆,别忘了配置Slave1到Master的免登陆
在Slave1上生产一对钥匙
ssh-keygen -t rsa
ssh-coyp-id -i Master
2.4将配置好的hadoop拷贝到其他节点
scp -r /app/ Slave1:/
scp -r /app/ Slave3:/
scp -r /app/ Slave4:/
scp -r /app/ Slave5:/
scp -r /app/ Slave6:/
scp -r /app/ Slave7:/
到此以上7台机器环境一致,但它们会根据配置文件读取各自的角色。3.2 启动验证集群
3.2.1 启动zookeeper集群(分别在Slave5、Slave6、Slave7上启动zk)
cd /itcast/zookeeper-3.4.5/bin/
./zkServer.sh start
#查看状态:一个leader,两个follower
./zkServer.sh status
3.2.2 启动journalnode(在Master上启动所有journalnode,注意:是调用的hadoop-daemons.sh这个脚本,注意是复数s的那个脚本,分别在Slave5、Slave6、Slave7上也可以执行sbin/hadoop-daemon.sh start journalnode启动journalnode)
cd /itcast/hadoop-2.2.0
sbin/hadoop-daemons.sh start journalnode
#运行jps命令检验,Slave5、Slave6、Slave7上多了JournalNode进程
3.2.3格式化HDFS
#在Master上执行命令:
hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/home/hadoop/app/hadoop-2.4.1/tmp,然后将/home/hadoop/app/hadoop-2.4.1/tmp拷贝到Slave1的/itcast/hadoop-2.2.0/下。
scp -r tmp/ Slave1:/home/hadoop/app/hadoop-2.4.1/
3.2.3格式化ZK(在Master上执行即可)
hdfs zkfc -formatZK
3.2.4启动HDFS(在Master上执行)
sbin/start-dfs.sh
3.2.5启动YARN(#####注意#####:是在Slave3上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动)
sbin/start-yarn.sh
到此,hadoop2.2.0配置完毕,可以统计浏览器访问:
http://192.168.1.201:50070
NameNode 'Master:9000' (active)
http://192.168.1.202:50070
NameNode 'Slave1:9000' (standby)
验证HDFS HA
首先向hdfs上传一个文件
hadoop fs -put /etc/profile /profile
hadoop fs -ls /
然后再kill掉active的NameNode
kill -9 of NN>
通过浏览器访问:http://172.25.11.131:50070
NameNode 'Slave1:9000' (active)
这个时候Slave1上的NameNode变成了active
再执行命令:
hadoop fs -ls /
-rw-r--r-- 3 root supergroup 1926 2014-02-06 15:36 /profile
刚才上传的文件依然存在!!!
手动启动那个挂掉的NameNode
sbin/hadoop-daemon.sh start namenode
通过浏览器访问:http://192.168.1.201:50070
NameNode 'Master:9000' (standby)
验证YARN:
运行一下hadoop提供的demo中的WordCount程序:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /profile /out
OK,大功告成!!!
配置如果遇到问题,先查看日志文件!!!再使用搜索引擎进行搜索求助! 3.3 一些其他的配置(可以使用默认的)
3.3.1 DataNode节点超时时间设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,
namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。
HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的
heartbeat.recheck.interval的单位为毫秒,
dfs.heartbeat.interval的单位为秒。
所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。
hdfs-site.xml中的参数设置格式:
<property>
<name>heartbeat.recheck.intervalname>
<value>2000value>
property>
<property>
<name>dfs.heartbeat.intervalname>
<value>1value>
property>3.3.2 HDFS冗余数据块的自动删除
在日常维护hadoop集群的过程中发现这样一种情况:
某个节点由于网络故障或者DataNode进程死亡,被NameNode判定为死亡,
HDFS马上自动开始数据块的容错拷贝;
当该节点重新添加到集群中时,由于该节点上的数据其实并没有损坏,
所以造成了HDFS上某些block的备份数超过了设定的备份数。
通过观察发现,这些多余的数据块经过很长的一段时间才会被完全删除掉,
那么这个时间取决于什么呢?
该时间的长短跟数据块报告的间隔时间有关。
Datanode会定期将当前该结点上所有的BLOCK信息报告给Namenode,
参数dfs.blockreport.intervalMsec就是控制这个报告间隔的参数。
hdfs-site.xml文件中有一个参数:
<property>
<name>dfs.blockreport.intervalMsecname>
<value>10000value>
<description>Determines block reporting interval in milliseconds.description>
property>其中3600000为默认设置,3600000毫秒,即1个小时,也就是说,块报告的时间间隔为1个小时,所以经过了很长时间这些多余的块才被删除掉。通过实际测试发现,当把该参数调整的稍小一点的时候(60秒),多余的数据块确实很快就被删除了。
3.3.3 Hadoop机架感知
1.背景
Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份,同机架内其它某一节点上一份,不同机架的某一节点上一份。这样如果本地数据损坏,节点可以从同一机架内的相邻节点拿到数据,速度肯定比从跨机架节点上拿数据要快;同时,如果整个机架的网络出现异常,也能保证在其它机架的节点上找到数据。为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本。如果在读取程序的同一个机架上有一个副本,那么就读取该副本。如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本。那么Hadoop是如何确定任意两个节点是位于同一机架,还是跨机架的呢?答案就是机架感知。
默认情况下,hadoop的机架感知是没有被启用的。所以,在通常情况下,hadoop集群的HDFS在选机器的时候,是随机选择的,也就是说,很有可能在写数据时,hadoop将第一块数据block1写到了rack1上,然后随机的选择下将block2写入到了rack2下,此时两个rack之间产生了数据传输的流量,再接下来,在随机的情况下,又将block3重新又写回了rack1,此时,两个rack之间又产生了一次数据流量。在job处理的数据量非常的大,或者往hadoop推送的数据量非常大的时候,这种情况会造成rack之间的网络流量成倍的上升,成为性能的瓶颈,进而影响作业的性能以至于整个集群的服务
2.配置
默认情况下,namenode启动时候日志是这样的:
2013-09-22 17:27:26,423 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/ 192.168.147.92:50010每个IP 对应的机架ID都是 /default-rack ,说明hadoop的机架感知没有被启用。
要将hadoop机架感知的功能启用,配置非常简单,在 NameNode所在节点的/home/bigdata/apps/hadoop/etc/hadoop的core-site.xml配置文件中配
<property>
<name>topology.script.file.namename>
/home/bigdata/apps/hadoop/etc/hadoop/topology.sh
property>个配置选项的value指定为一个可执行程序,通常为一个脚本,该脚本接受一个参数,输出一个值。接受的参数通常为某台datanode机器的ip地址,而输出的值通常为该ip地址对应的datanode所在的rack,例如”/rack1”。Namenode启动时,会判断该配置选项是否为空,如果非空,则表示已经启用机架感知的配置,此时namenode会根据配置寻找该脚本,并在接收到每一个datanode的heartbeat时,将该datanode的ip地址作为参数传给该脚本运行,并将得到的输出作为该datanode所属的机架ID,保存到内存的一个map中.
至于脚本的编写,就需要将真实的网络拓朴和机架信息了解清楚后,通过该脚本能够将机器的ip地址和机器名正确的映射到相应的机架上去。一个简单的实现如下:
#!/bin/bash
HADOOP_CONF=/home/bigdata/apps/hadoop/etc/hadoop
while [ $# -gt 0 ] ; do
nodeArg=$1
exec<${HADOOP_CONF}/topology.data
result=""
while read line ; do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ]||[ "${ar[1]}" = "$nodeArg" ]; then
result="${ar[2]}"
fi
done
shift
if [ -z "$result" ] ; then
echo -n "/default-rack"
else
echo -n "$result"
fi
donetopology.data,格式为:节点(ip或主机名) /交换机xx/机架xx
192.168.147.91 tbe192168147091 /dc1/rack1
192.168.147.92 tbe192168147092 /dc1/rack1
192.168.147.93 tbe192168147093 /dc1/rack2
192.168.147.94 tbe192168147094 /dc1/rack3
192.168.147.95 tbe192168147095 /dc1/rack3
192.168.147.96 tbe192168147096 /dc1/rack3
需要注意的是,在Namenode上,该文件中的节点必须使用IP,使用主机名无效,而Jobtracker上,该文件中的节点必须使用主机名,使用IP无效,所以,最好ip和主机名都配上。
这样配置后,namenode启动时候日志是这样的:
2013-09-23 17:16:27,272 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /dc1/rack3/ 192.168.147.94:50010
说明hadoop的机架感知已经被启用了。
查看HADOOP机架信息命令:
./hadoop dfsadmin -printTopology
Rack: /dc1/rack1
192.168.147.91:50010 (tbe192168147091)
192.168.147.92:50010 (tbe192168147092)
Rack: /dc1/rack2
192.168.147.93:50010 (tbe192168147093)
Rack: /dc1/rack3
192.168.147.94:50010 (tbe192168147094)
192.168.147.95:50010 (tbe192168147095)
192.168.147.96:50010 (tbe192168147096)3.增加数据节点,不重启NameNode
假设Hadoop集群在192.168.147.68上部署了NameNode和DataNode,启用了机架感知,执行bin/hadoop dfsadmin -printTopology看到的结果:
Rack: /dc1/rack1
192.168.147.68:50010 (dbj68)
现在想增加一个物理位置在rack2的数据节点192.168.147.69到集群中,不重启NameNode。
首先,修改NameNode节点的topology.data的配置,加入:192.168.147.69 dbj69 /dc1/rack2,保存。
192.168.147.68 dbj68 /dc1/rack1
192.168.147.69 dbj69 /dc1/rack2然后,sbin/hadoop-daemons.sh start datanode启动数据节点dbj69,任意节点执行bin/hadoop dfsadmin -printTopology 看到的结果:
Rack: /dc1/rack1
192.168.147.68:50010 (dbj68)
Rack: /dc1/rack2
192.168.147.69:50010 (dbj69)
说明hadoop已经感知到了新加入的节点dbj69。
注意:如果不将dbj69的配置加入到topology.data中,执行sbin/hadoop-daemons.sh start datanode启动数据节点dbj69,datanode日志中会有异常发生,导致dbj69启动不成功。
2013-11-21 10:51:33,502 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for block pool Block pool BP-1732631201-192.168.147.68-1385000665316 (storage id DS-878525145-192.168.147.69-50010-1385002292231) service to dbj68/192.168.147.68:9000
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.net.NetworkTopology$InvalidTopologyException): Invalid network topology. You cannot have a rack and a non-rack node at the same level of the network topology.
at org.apache.hadoop.net.NetworkTopology.add(NetworkTopology.java:382)
at org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager.registerDatanode(DatanodeManager.java:746)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.registerDatanode(FSNamesystem.java:3498)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.registerDatanode(NameNodeRpcServer.java:876)
at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolServerSideTranslatorPB.registerDatanode(DatanodeProtocolServerSideTranslatorPB.java:91)
at org.apache.hadoop.hdfs.protocol.proto.DatanodeProtocolProtos$DatanodeProtocolService$2.callBlockingMethod(DatanodeProtocolProtos.java:20018)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:453)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1002)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1701)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1697)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1408)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:1695)
at org.apache.hadoop.ipc.Client.call(Client.java:1231)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:202)
at $Proxy10.registerDatanode(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:601)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:164)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:83)
at $Proxy10.registerDatanode(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolClientSideTranslatorPB.registerDatanode(DatanodeProtocolClientSideTranslatorPB.java:149)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.register(BPServiceActor.java:619)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:221)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:660)
at java.lang.Thread.run(Thread.java:722)4.节点间距离计算
有了机架感知,NameNode就可以画出下图所示的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离,得到最优的存放策略,优化整个集群的网络带宽均衡以及数据最优分配。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R2/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode