SVM(一):线性支持向量机
1. 线性支持向量机
- 1.1 问题定义
- (1) 划分超平面
- (2) 点到超平面的距离
- (3)支持向量、间隔
- (4)最优超平面
- 1.2 对偶问题
- 1.3 问题求解
1.1 问题定义
(1) 划分超平面
二维样本空间中,划分平面可以表示为: w 1 x 1 + w 2 x 2 + b = 0 w_1x_1+w_2x_2+b=0 w1x1+w2x2+b=0
在高维样本空间中,划分超平面定义如下: w T x + b = 0 \boldsymbol w^T \boldsymbol x + b = 0 wTx+b=0
其中, w = ( w 1 , w 2 , . . . , w d ) \boldsymbol w = (w_1,w_2,...,w_d) w=(w1,w2,...,wd)为法向量,决定了超平面的方向; b b b为位移,决定了超平面与原点之间的距离。
设空间中任一点 x \boldsymbol x x在超平面的投影为 x ′ \boldsymbol x' x′,则 x = x ′ + λ w \boldsymbol x= \boldsymbol x′+ \lambda \boldsymbol w x=x′+λw
w T x + b = w T ( x ′ + λ w ) + b = w T x ′ + b + λ w w T = λ w T w \boldsymbol w^T \boldsymbol x +b = \boldsymbol w^T (\boldsymbol x'+\lambda w) + b = \boldsymbol w^T \boldsymbol x' +b + \lambda \boldsymbol w \boldsymbol w^T = \lambda \boldsymbol w^T \boldsymbol w wTx+b=wT(x′+λw)+b=wTx′+b+λwwT=λwTw
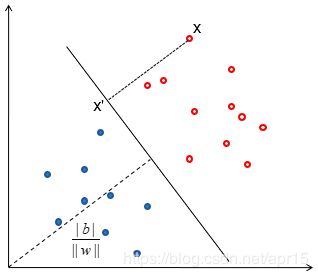
(2) 点到超平面的距离
样本空间中任意点 x \boldsymbol x x到超平面的距离为
γ = ∣ ∣ x − x ′ ∣ ∣ = ∣ ∣ λ w ∣ ∣ = λ ∣ ∣ w ∣ ∣ 2 ∣ ∣ w ∣ ∣ = ∣ w T x + b ∣ ∣ ∣ w ∣ ∣ \begin{aligned} \gamma & = ||\boldsymbol x - \boldsymbol x'|| \\ & = ||\lambda \boldsymbol w|| \\ & = \frac {\lambda {||\boldsymbol w||}^2}{||\boldsymbol w||} \\ & = \frac{|\boldsymbol w^{T} \boldsymbol x+b|}{|| \boldsymbol w||} \end{aligned} γ=∣∣x−x′∣∣=∣∣λw∣∣=∣∣w∣∣λ∣∣w∣∣2=∣∣w∣∣∣wTx+b∣
其中, ∣ ∣ w ∣ ∣ = ∑ i = 1 n w i 2 \left| \left| \boldsymbol w \right| \right|=\sqrt{\sum_{i=1}^{n}{w_{i}^{2}}} ∣∣w∣∣=∑i=1nwi2为 w w w的L2范数。
(3)支持向量、间隔
假设超平面能将训练样本正确分类,即对于 ( x i , y i ) ∈ D (\boldsymbol x_i,y_i) \in D (xi,yi)∈D,
{ w T x i + b > 0 , y i = + 1 w T x i + b < 0 , y i = − 1 \begin{cases} \boldsymbol w^T \boldsymbol x_i + b > 0, y_i=+1 & \\ \boldsymbol w^T \boldsymbol x_i + b < 0, y_i=-1 & \end{cases} {wTxi+b>0,yi=+1wTxi+b<0,yi=−1
⇔ y i ( w T x i + b ) > 0 ⇔ ∃ r > 0 , s . t . min y i ( w T x i + b ) = r \begin{aligned} & \Leftrightarrow y_i(\boldsymbol w^T \boldsymbol x_i + b)>0 \;\; \\ & \Leftrightarrow \exists r>0, s.t. \min y_i(\boldsymbol w^T \boldsymbol x_i + b)=r \end{aligned} ⇔yi(wTxi+b)>0⇔∃r>0,s.t.minyi(wTxi+b)=r
由于 w 与 b \boldsymbol w 与 b w与b可任意缩放,令 r = 1 r=1 r=1
⇔ y i ( w T x i + b ) ≥ 1 ⇔ { w T x i + b ≥ + 1 , y i = + 1 w T x i + b ≤ − 1 , y i = − 1 \begin{aligned} & \Leftrightarrow y_i(\boldsymbol w^T \boldsymbol x_i + b) \geq 1 \\ & \\ & \Leftrightarrow \begin{cases} \boldsymbol w^T \boldsymbol x_i + b \geq +1, y_i=+1 & \\ \boldsymbol w^T \boldsymbol x_i + b \leq -1, y_i=-1 & \end{cases} \end{aligned} ⇔yi(wTxi+b)≥1⇔{wTxi+b≥+1,yi=+1wTxi+b≤−1,yi=−1
如下图所示,距离超平面最近的训练样本点是得上式等号成立,称为支持向量(Support vector)。
支持向量到超平面的距离之和为 γ = 2 ∣ ∣ w ∣ ∣ \gamma = \frac{2}{|| \boldsymbol w||} γ=∣∣w∣∣2,称为间隔(margin)。
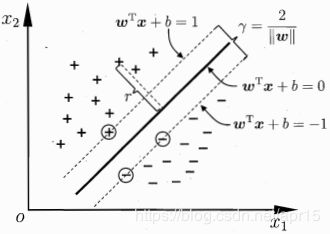
(4)最优超平面
能将两类样本划分的超平面有无数多个,具有最大分类间隔的超平面,称为最优超平面。
为找到具有最大间隔的划分超平面,需要 max w , b 1 ∣ ∣ w ∣ ∣ s . t . y i ( w T x i + b ) ≥ 1 ( i = 1 , 2 , . . . m ) \max_{\boldsymbol w,b} \;\; \frac{1}{||\boldsymbol w||} \;\; s.t. \;\; y_i(\boldsymbol w^T \boldsymbol x_i + b) \geq 1 (i =1,2,...m) w,bmax∣∣w∣∣1s.t.yi(wTxi+b)≥1(i=1,2,...m)
即 min w , b 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y i ( w T x i + b ) ≥ 1 ( i = 1 , 2 , . . . m ) \min_{\boldsymbol w,b} \;\; \frac{1}{2}||\boldsymbol w||^2 \;\; s.t. \;\; y_i(\boldsymbol w^T \boldsymbol x_i + b) \geq 1 (i =1,2,...m) w,bmin21∣∣w∣∣2s.t.yi(wTxi+b)≥1(i=1,2,...m)
1.2 对偶问题
目标函数 1 2 ∣ ∣ w ∣ ∣ 2 2 \frac {1}{2}||\boldsymbol w||_2^2 21∣∣w∣∣22是凸函数,同时约束条件不等式是仿射的,是一个凸二次规划(convex quadratic programming)问题,可以用优化计算包求解(适用于维度较低的情况)。
另一种更高效的办法是,通过拉格朗日函数(对每条约束添加拉格朗日乘子 α i ≥ 0 \alpha_i \geq 0 αi≥0)将的优化目标转化为无约束的优化函数: L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 m α i [ 1 − y i ( w T x i + b ) ] (1) L(\boldsymbol w,b,\boldsymbol \alpha) = \frac{1}{2}||\boldsymbol w||^2 + \sum\limits_{i=1}^{m}\alpha_i [ 1 - y_i(\boldsymbol w^T \boldsymbol x_i + b)] \tag {1} L(w,b,α)=21∣∣w∣∣2+i=1∑mαi[1−yi(wTxi+b)](1)其中 α = ( α 1 , α 2 , . . . , α m ) \boldsymbol \alpha = (\alpha_1,\alpha_2,...,\alpha_m) α=(α1,α2,...,αm)
由于引入了朗格朗日乘子,优化目标变成: min w , b max α i ≥ 0 L ( w , b , α ) (2) \min_{\boldsymbol w,b}\; \max_{\alpha_i \geq 0} L(\boldsymbol w,b,\boldsymbol \alpha) \tag {2} w,bminαi≥0maxL(w,b,α)(2)
该优化函数满足满足KTT条件,即
{ α i ≥ 0 1 − y i f ( x i ) ≤ 0 α i ( y i f ( x i ) − 1 ) = 0 f ( x i ) = w T x i + b (3) \begin{cases} \alpha_i \geq 0 \\ \\ 1-y_if(\boldsymbol x_i) \leq 0 \\ \\ \alpha_i(y_if(\boldsymbol x_i)-1)=0 \end{cases} \;\;\; f(\boldsymbol x_i) = \boldsymbol w^T \boldsymbol x_i + b \tag {3} ⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧αi≥01−yif(xi)≤0αi(yif(xi)−1)=0f(xi)=wTxi+b(3)
对于任意训练样本 ( x i , y i ) (\boldsymbol x_i,y_i) (xi,yi),必有 α i = 0 \alpha_i=0 αi=0或 y i f ( x i ) = 1 y_if(\boldsymbol x_i)=1 yif(xi)=1。
若 α i = 0 \alpha_i=0 αi=0,则该样本不会在求和式中出现,也就不会对 f ( x ) f(\boldsymbol x) f(x)有任何影响;
若 α i > 0 \alpha_i>0 αi>0,则必有 y i f ( x i ) = 1 y_if(\boldsymbol x_i)=1 yif(xi)=1,该样本点在最大间隔边界上,是一个支持向量。
这显示出支持向量基的一个重要性质:最终模型仅与支持向量有关
因此,根据拉格朗日对偶条件,原问题的对偶问题如下:
max α i ≥ 0 min w , b L ( w , b , α ) (4) \max_{\alpha_i \geq 0} \;\min_{\boldsymbol w,b}\; L(\boldsymbol w,b,\boldsymbol \alpha) \tag {4} αi≥0maxw,bminL(w,b,α)(4)
极大极小问题:先求优化函数对于 w w w和 b b b的极小值,再求拉格朗日乘子 α \alpha α的极大值
L ( w , b , α ) L(\boldsymbol w,b,\boldsymbol \alpha) L(w,b,α)关于 w \boldsymbol w w和 b b b极小值可以通过对 w \boldsymbol w w和 b b b分别求偏导得到:
∂ L ∂ w = 0 ⇒ w = ∑ i = 1 m α i y i x i (5) \frac{\partial L}{\partial \boldsymbol w} = 0 \;\Rightarrow \boldsymbol w = \sum\limits_{i=1}^{m}\alpha_iy_i \boldsymbol x_i \tag {5} ∂w∂L=0⇒w=i=1∑mαiyixi(5) ∂ L ∂ b = 0 ⇒ ∑ i = 1 m α i y i = 0 (6) \frac{\partial L}{\partial b} = 0 \;\Rightarrow \sum\limits_{i=1}^{m}\alpha_iy_i = 0 \tag {6} ∂b∂L=0⇒i=1∑mαiyi=0(6)将 w w w的值代入 L ( w , b , α ) L(\boldsymbol w,b,\boldsymbol \alpha) L(w,b,α):
min w , b L ( w , b , α ) = ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j s . t . ∑ i = 1 m α i y i = 0 , α i ≥ 0 , i = 1 , 2 , . . . m (7) \begin{aligned}\min_{w,b}\; L(\boldsymbol w,b,\boldsymbol \alpha) & = \sum\limits_{i=1}^{m}\alpha_i - \frac{1}{2}\sum\limits_{i=1}^{m}\sum\limits_{j=1}^{m}\alpha_i\alpha_jy_iy_j\boldsymbol x_i^T \boldsymbol x_j \\ s.t. \; & \sum\limits_{i=1}^{m}\alpha_iy_i = 0, \\ & \alpha_i \geq 0, \; i=1,2,...m \end{aligned} \tag {7} w,bminL(w,b,α)s.t.=i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxji=1∑mαiyi=0,αi≥0,i=1,2,...m(7)
原问题最终转换为如下形式的对偶问题:
max α i ≥ 0 ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j (8) \max_{\alpha_i \geq 0} \;\; \sum\limits_{i=1}^{m}\alpha_i - \frac{1}{2}\sum\limits_{i=1}^{m}\sum\limits_{j=1}^{m}\alpha_i\alpha_jy_iy_j\boldsymbol x_i^T \boldsymbol x_j \tag {8} αi≥0maxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj(8) s . t . ∑ i = 1 m α i y i = 0 , α i ≥ 0 , i = 1 , 2 , . . . m s.t. \begin{aligned} \\ & \; \sum\limits_{i=1}^{m}\alpha_iy_i = 0, \\ & \alpha_i \geq 0, \; i=1,2,...m \end{aligned} s.t.i=1∑mαiyi=0,αi≥0,i=1,2,...m此时,优化函数仅有 α \boldsymbol \alpha α做为参数,可采用SMO(Sequential Minimal Optimization)求解。
1.3 问题求解
SMO算法则采用了一种启发式的方法,它每次只优化两个变量,将其他的变量都视为常数,将复杂的优化算法转化为一个简单的两变量优化问题.
由于 ∑ i = 1 m α i y i = 0 \sum\limits_{i=1}^{m}\alpha_iy_i = 0 i=1∑mαiyi=0.假如将 α 3 , α 4 , . . . , α m \alpha_3, \alpha_4, ..., \alpha_m α3,α4,...,αm固定,那么 α 1 , α 2 \alpha_1, \alpha_2 α1,α2之间的关系也确定了。初始化参数后,SMO不断执行以下两个步骤直至收敛:
- 选取一对需更新的变量 α i \alpha_i αi和 α j \alpha_j αj;
- 固定 α i \alpha_i αi和 α j \alpha_j αj以外的参数,求解获得更新后的 α i \alpha_i αi和 α j \alpha_j αj。
解出最优化对应的 α \boldsymbol \alpha α的值 α ∗ \boldsymbol \alpha^* α∗后,可求出 w ∗ = ∑ i = 1 m α i ∗ y i x i w^{*} = \sum\limits_{i=1}^{m}\alpha_i^{*}y_i \boldsymbol x_i w∗=i=1∑mαi∗yixi
对于任意支持向量 ( x s , y s ) (\boldsymbol x_s,y_s) (xs,ys)都有 y s f ( x s ) = 1 y_sf(\boldsymbol x_s)=1 ysf(xs)=1,即 y s ( ∑ i ∈ S α i y i x i T x s + b ) = 1 y_s(\sum\limits_{i \in S}\alpha_iy_i \boldsymbol x_i^T \boldsymbol x_s+b) = 1 ys(i∈S∑αiyixiTxs+b)=1
S S S为所有支持向量的集合,即满足 α s > 0 \alpha_s > 0 αs>0对应的样本 ( x s , y s ) (\boldsymbol x_s,y_s) (xs,ys),理论上可任意选取支持向量通过上式,求得 b b b。
一般采取一种更为鲁棒的方法,即计算出每个支持向量 ( x s , y s ) (\boldsymbol x_s, y_s) (xs,ys)对应的 b s ∗ b_s^{*} bs∗,对其求平均值得到
b ∗ = 1 S ∑ i = 1 S ( 1 y s − ∑ i ∈ S α i y i x i T x s ) b^{*} = \frac{1}{S}\sum\limits_{i=1}^{S}(\frac{1}{y_s} - \sum\limits_{i \in S}\alpha_iy_i\boldsymbol x_i^T \boldsymbol x_s) b∗=S1i=1∑S(ys1−i∈S∑αiyixiTxs)
最终得到分类超平面 w ∗ T x + b ∗ = 0 \boldsymbol w^{* T} \boldsymbol x + b^{*} = 0 w∗Tx+b∗=0,分类决策函数为 f ( x ) = s i g n ( w ∗ T x + b ∗ ) f(\boldsymbol x) = sign(\boldsymbol w^{* T} \boldsymbol x + b^{*}) f(x)=sign(w∗Tx+b∗)