PCA(Principal Component Analysis)是机器学习中对数据进行降维的一种方法。主要目的是在不丢失原有数据信息的情况下降低机器学习算法的复杂度,及资源消耗。本篇文章将使用python对特征进行降维。
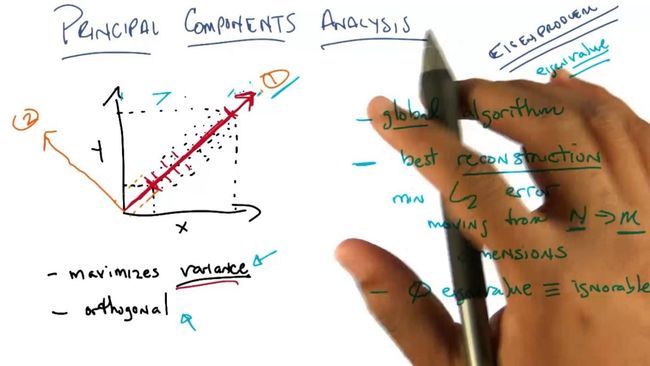
PCA通过线性变换将原始数据中可能相关的数据转换为一组线性不相关的数据。以本篇文章中所使用的贷款用户特征数据来说,其中包含了贷款用户的借款金额,利息,利率,年收入,信用卡账户数量等多个维度的信息。而这些信息中不同维度的数据间可能会存在关联,例如,当我们知道了借款金额和利率后,就可以计算出利息。这种情况下,我们保留其中的两个维度就可以保证原有信息完整。因此我们可以将这3个维度的数据减少为2个维度。下面我们将使用Python来说明使用PCA对贷款数据进行降维过程。
准备工作
首先导入所需要的库文件,这里是我们常用的数值计算库numpy,科学计算库pandas和数据预处理库preprocessing以及PCA算法库。后面我们将对使用这些库文件对贷款数据进行导入,读取,标准化处理。
|
1
2
3
4
5
6
7
8
|
#导入数值计算库
import
numpy as np
#导入科学计算库
import
pandas as pd
#导入数据预处理库
from
sklearn.preprocessing
import
StandardScaler
#导入PCA算法库
from
sklearn.decomposition
import
PCA
|
读取并查看数据表
第二步导入贷款数据,并创建名为LoanStats3a的贷款数据表。通过查看数据表中的内容可以发现,这个数据表中包含了贷款用户的信息以及还款状态信息。其中,除了贷款状态(loan_status)列以外,其他的列都是贷款的特征数据,我们将对这些贷款的特征数据进行降维。
|
1
2
|
#读取贷款状态数据从创建名为LoanStats3a的数据表
LoanStats3a
=
pd.DataFrame(pd.read_csv(
'LoanStats3a.csv'
))
|
|
1
2
|
#查看数据表内容
LoanStats3a.head()
|
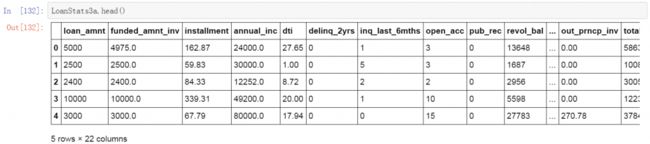
数据表中可能会包含一些空值,我们将包含有空值的数据进行删除处理。
|
1
2
|
#删除包含空值的特征
LoanStats3a
=
LoanStats3a.dropna()
|
查看数据表中详细的列名称,后面创建特征数据表时会用到。
|
1
2
3
4
5
6
7
8
9
|
#查看特征的名称
LoanStats3a.columns
Index([
'loan_amnt'
,
'funded_amnt_inv'
,
'installment'
,
'annual_inc'
,
'dti'
,
'delinq_2yrs'
,
'inq_last_6mths'
,
'open_acc'
,
'pub_rec'
,
'revol_bal'
,
'total_acc'
,
'out_prncp'
,
'out_prncp_inv'
,
'total_pymnt'
,
'total_pymnt_inv'
,
'total_rec_prncp'
,
'total_rec_int'
,
'total_rec_late_fee'
,
'recoveries'
,
'collection_recovery_fee'
,
'last_pymnt_amnt'
,
'loan_status'
],
dtype
=
'object'
)
|
获取数据特征
将贷款数据表中的贷款特征数据单独提取出来,用于后面的降维操作。
|
1
2
3
4
5
6
7
|
#设置特征表X
X
=
np.array(LoanStats3a[[
'loan_amnt'
,
'funded_amnt_inv'
,
'installment'
,
'annual_inc'
,
'dti'
,
'delinq_2yrs'
,
'inq_last_6mths'
,
'open_acc'
,
'pub_rec'
,
'revol_bal'
,
'total_acc'
,
'out_prncp'
,
'out_prncp_inv'
,
'total_pymnt'
,
'total_pymnt_inv'
,
'total_rec_prncp'
,
'total_rec_int'
,
'total_rec_late_fee'
,
'recoveries'
,
'collection_recovery_fee'
,
'last_pymnt_amnt'
]])
|
查看一下特征的维度,一共包含有21个维度和39785条数据。后面我们会通过PCA算法降至3个维度。
|
1
2
3
|
#查看特征的维度
X.shape
(
39785
,
21
)
|
进一步查看特征数据表X会发现,其中的不同维度的数据间量级相差较大,因此需要预先对数据进行标准化处理。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#查看特征数据
X
array([[
5.00000000e
+
03
,
4.97500000e
+
03
,
1.62870000e
+
02
, ...,
0.00000000e
+
00
,
0.00000000e
+
00
,
1.71620000e
+
02
],
[
2.50000000e
+
03
,
2.50000000e
+
03
,
5.98300000e
+
01
, ...,
1.17080000e
+
02
,
1.11000000e
+
00
,
1.19660000e
+
02
],
[
2.40000000e
+
03
,
2.40000000e
+
03
,
8.43300000e
+
01
, ...,
0.00000000e
+
00
,
0.00000000e
+
00
,
6.49910000e
+
02
],
...,
[
5.00000000e
+
03
,
1.32500000e
+
03
,
1.56840000e
+
02
, ...,
0.00000000e
+
00
,
0.00000000e
+
00
,
0.00000000e
+
00
],
[
5.00000000e
+
03
,
6.50000000e
+
02
,
1.55380000e
+
02
, ...,
0.00000000e
+
00
,
0.00000000e
+
00
,
0.00000000e
+
00
],
[
7.50000000e
+
03
,
8.00000000e
+
02
,
2.55430000e
+
02
, ...,
0.00000000e
+
00
,
0.00000000e
+
00
,
2.56590000e
+
02
]])
|
特征数据标准化
使用StandardScaler对贷款特征数据进行标准化处理,去除不同数据的单位限制,将它们转化为无量纲的纯数值。
|
1
2
3
|
#对特征数据进行标准化处理
sc
=
StandardScaler()
X_std
=
sc.fit_transform(X)
|
标准化后的数据被缩放到了同一个同一个较小的区间中。现在可以使用PCA对这些特征数据进行降维处理了。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#查看标准化后的特征数据
X_std
array([[
-
0.83479906
,
-
0.76153543
,
-
0.77474943
, ...,
-
0.13847351
,
-
0.08400349
,
-
0.56418651
],
[
-
1.16971587
,
-
1.10838129
,
-
1.26794505
, ...,
0.03030355
,
-
0.07658255
,
-
0.57587995
],
[
-
1.18311254
,
-
1.12239527
,
-
1.15067707
, ...,
-
0.13847351
,
-
0.08400349
,
-
0.45654882
],
...,
[
-
0.83479906
,
-
1.27304549
,
-
0.80361171
, ...,
-
0.13847351
,
-
0.08400349
,
-
0.60280906
],
[
-
0.83479906
,
-
1.36763982
,
-
0.81059992
, ...,
-
0.13847351
,
-
0.08400349
,
-
0.60280906
],
[
-
0.49988226
,
-
1.34661886
,
-
0.33171579
, ...,
-
0.13847351
,
-
0.08400349
,
-
0.54506427
]])
|
使用PCA对特征降维
创建一个PCA对象,并且将n_components的参数值设置为3。这里如果n_components的参数值为空将保留所有的特征。
|
1
2
|
#创建PCA对象,n_components=3
pca
=
decomposition.PCA(n_components
=
3
)
|
使用PCA对标准化后的贷款特征数据进行降维处理。
|
1
2
|
#使用PCA对特征进行降维
X_std_pca
=
pca.fit_transform(X_std)
|
查看降维后的贷款特征数据,从之前的21变成3。贷款数据条目数没有变化,依然是39785条。
|
1
2
3
|
#查看降维后特征的维度
X_std_pca.shape
(
39785
,
3
)
|
以下是降维后的贷款特征数据表。
|
1
2
3
4
5
6
7
8
9
|
#查看降维后的特征表
X_std_pca
array([[
-
2.15602968
,
0.47264478
,
-
0.09039787
],
[
-
3.5622926
,
0.89531087
,
-
0.44500729
],
[
-
3.17079954
,
0.90669216
,
-
0.57821776
],
...,
[
-
2.38199031
,
0.08409512
,
-
0.15199005
],
[
-
1.33735898
,
-
1.45552179
,
1.0660925
],
[
-
2.05023498
,
0.63465247
,
-
0.35337066
]])
|