PyTorch学习笔记(一)Tensor运算
Environment
- OS: macOS Mojave
- Python version: 3.7
- PyTorch version: 1.4.0
- IDE: PyCharm
文章目录
- 0. 写在前面
- 1. 计算图
- 2. 求梯度
- 2.1 基本方法
- 2.2 手动清零梯度
- 2.3 求梯度的函数
0. 写在前面
本文记录了 PyTorch 中怎样对张量的运算和求梯度。
在旧版本的 PyTorch 中 (version 0.4.0 之前),torch.autograd.Variable 为主要的运算对象。Variable 封装了 Tensor,能够进行自动求导。
Variable 有 5 个主要的属性
data保存 Tensor 数据grad保存 data 的梯度grad_fn指向 Function 对象,用于反向传播时计算梯度requires_grad为是否需要梯度is_leaf为是否为是叶子结点(计算图中的概念)
从 versioin 0.4.0 开始,上述属性直接被赋予了 Tensor,直接使用 Tensor 作为主要的运算对象。
除了上述属性外,Tensor 还有 3 个主要的属性
dtype数据类型shape形状,即每个维度上的长度device所在的设备,GPU 或 CPU
1. 计算图
计算图用来描述运算过程,由结点(node)和边(edge)组成,结构上是一个有向无环图(directed acyclic graph, DAG)。
- 结点表示数据,为torch.Tensor对象,输入数据的结点称为叶子结点
- 边表示具体运算,如加、减、乘、除、卷积、池化等
PyTorch 采用动态图机制,
- 创建张量实际上就是创建叶子结点
- 对张量进行运算实际上是构建计算图,并且在图中进行前向传播的过程
(而 TensorFlow 采用静态图机制,要求先搭建图,再给入数据进行运算)
构建如下简单的计算图
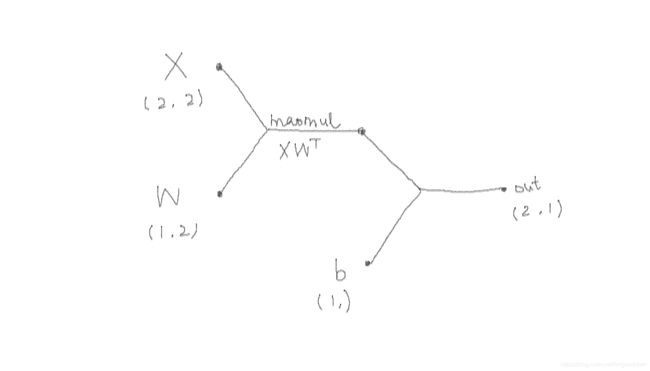
x = torch.tensor([
[1., 3],
[2, 4]
])
w = torch.tensor([
[1., 2],
], requires_grad=True)
# 与 NumPy 类似,PyTorch 中对 tensor 运算同样有 broadcast 机制
b = torch.tensor([3.], requires_grad=True)
mid = x @ w.T # 矩阵相乘,即 mid = torch.matmul(x, w.T)
out = mid + b # 即 out = torch.add(mid, b)
out_mean = out.mean()
print(out)
# tensor([[10.],
# [13.]], grad_fn=)
print(out_mean)
# tensor(11.5000, grad_fn=)
2. 求梯度
2.1 基本方法
Tensor.backward()方法进行后向传播,得到输入数据的梯度
out_mean.backward(
gradient=None,
retain_graph=False, # 默认 False。若 True,则保留计算图,但总是没必要
create_graph=False # 默认 False。若 True,则创建反向传播的计算图,可用于计算高阶导数
)
print(b.grad, w.grad)
# tensor([1.]) tensor([[1.5000, 3.5000]])
Tensor.retain_graph()方法保留非叶子结点的梯度
为了链式求导,PyTorch 将中间结点的 requires_grad 设置为 True,虽然这些结点的梯度在后向传播过程中进行了计算,但并不会被保留
print(mid.is_leaf) # False
print(mid.grad) # None
若需要保留非叶子结点的梯度,则要在构建计算图时调用 retain_graph 方法
mid = x @ w.T
mid.retain_grad()
out = mid + b
out_mean = out.mean()
print(mid.grad)
# tensor([[0.5000],
# [0.5000]])
2.2 手动清零梯度
若进行多次后向传播,梯度将会累加,而不是清零
mid = x @ w.T
out = mid + b
out_mean = out.mean()
out_mean.backward()
print('first backward:', b.grad, w.grad)
# first backward: tensor([1.]) tensor([[1.5000, 3.5000]])
mid = x @ w.T
out = mid + b
out_mean = out.mean()
out_mean.backward()
print('second backward:', b.grad, w.grad)
# second backward: tensor([2.]) tensor([[3., 7.]])
因此,要将已有梯度清零时需要调用 Tensor.grad.zero_()
mid = x @ w.T
out = mid + b
out_mean = out.mean()
out_mean.backward()
print('first backward:', b.grad, w.grad)
# first backward: tensor([1.]) tensor([[1.5000, 3.5000]])
b.grad.zero_()
w.grad.zero_()
mid = x @ w.T
out = mid + b
out_mean = out.mean()
out_mean.backward()
print('second backward:', b.grad, w.grad)
# second backward: tensor([1.]) tensor([[1.5000, 3.5000]])
PyTorch 中,以单个下划线 _ 结尾的方法或函数通常表示 in-place 操作,对原 Tensor 对象进行操作而不返回新对象。注意,对于叶子结点,可以对 Tensor.grad 进行 in-place 操作,而不能对 Tensor 对象进行 in-place 操作
w = torch.tensor([
[1., 2],
], requires_grad=True)
w.zero_() # 报错
# RuntimeError: a leaf Variable that requires grad has been used in an in-place operation.
2.3 求梯度的函数
torch.autograd.backward()函数
实际上,基本的 Tensor.backward() 方法实际上调用了该函数。
torch.autograd.backward() 函数还可以对多个输出使用,可以用在一些有 aux 输出的神经网络,如 Inception v3。以这个小计算图例子
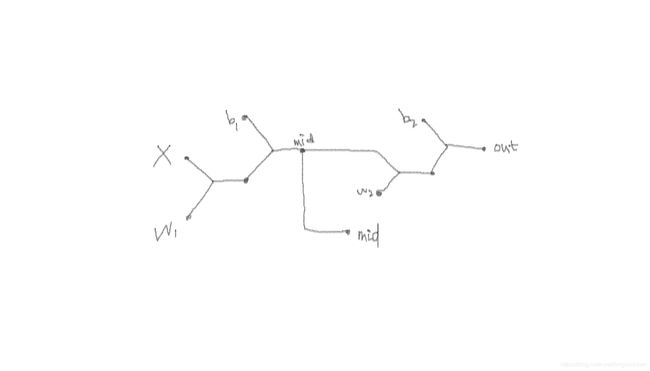
x = torch.tensor([1.])
w1 = torch.tensor([2.], requires_grad=True)
b1 = torch.tensor([3.], requires_grad=True)
w2 = torch.tensor([4.], requires_grad=True)
b2 = torch.tensor([5.], requires_grad=True)
mid = torch.add(torch.mul(x, w1), b1)
out = torch.add(torch.mul(mid, w2), b2)
torch.autograd.backward(
tensors=torch.cat((mid, out)), # 用于求解梯度的张量,如 loss
# 多个输出需要计算梯度时,grad_tensors参数传入每个输出的权重
grad_tensors=torch.tensor((0.2, 0.8)), # 视为系数,每个导数将乘以对应的系数
create_graph=False
)
print(w1.grad, b1.grad, w2.grad, b2.grad)
# tensor([3.4000]) tensor([3.4000]) tensor([4.]) tensor([0.8000])