YOLOv5 实现目标检测(训练自己的数据集实现猫猫识别)
一、概要
2020年6月10日,Ultralytics在github上正式发布了YOLOv5。YOLO系列可以说是单机目标检测框架中的潮流前线了,YOLOv5并不是一个单独的模型,而是一个模型家族,包括了YOLOv5s(最小)、YOLOv5m、YOLOv5l、YOLOv5x(最大)。

由于YOLOv5是在PyTorch中实现的,它受益于成熟的PyTorch生态系统,支持更简单,部署更容易,相对于YOLOv4,YOLOv5具有以下优点:
- 速度更快。在YOLOv5 Colab notebook上,运行Tesla
P100,我们看到每张图像的推理时间仅需0.007秒,这意味着每秒140帧(FPS),速度是YOLOv4的2倍还多。 - 精度更高。在Roboflow对血细胞计数和检测(BCCD)数据集的测试中,只训练了100个epochs就达到了大约0.895的平均精度(mAP)。诚然EfficientDet和YOLOv4的性能相当,但在准确率没有任何损失的情况下,看到如此全面的性能提升是非常罕见的。
- 体积更小。YOLOv5的权重文件是27兆字节。YOLOv4(采用Darknet架构)的权重文件是244兆。YOLOv5比YOLOv4小了近90%!这意味着YOLOv5可以更容易地部署到嵌入式设备上。
既然YOLOv5如此之棒,那我们就体验以下大神们的开源成果吧!
github地址:https://github.com/ultralytics/yolov5 [大概4M左右]
大神们还很贴心的把官方模型放到了谷歌网盘中,如果有梯子,可以下载下来直接测试一下。博主这边没梯子,不过也无关紧要啦,毕竟我们用YOLOv5是监测具体的某项东西,需要自己用数据集来训练模型,官方给的模型也不一定适合我们的业务场景。
至于YOLOv5的原理这里就不多讲了(其实是讲不清),感兴趣的可以自行搜索。话不多说,直接上干货!

二、环境配置
2.1 基本配置
首先将YOLOv5项目下载到本地,然后配置虚拟环境conda create -n pytorch1.5 python==3.7,在YOLOv5中尽量使用python3.7。项目的测试平台为:
操作系统:windows10
IDE:Pycharm
python版本:anaconda Pyhon3.7
pytorch版本:torch 1.5.1
cuda版本:10.1
显卡:RTX 2060
接着进入虚拟环境,使用pip安装必要模块(建议换成国内的源后进行安装):
pip install numpy==1.17
pip install opencv-python
pip install tqdm
pip install pillow
pip install tensorboard
pip install pyyaml
pip install git
pip install pandas
pip install scikit-image
pip install Cython
2.2 pycocotools安装
本项目需要pycocotools模块,COCO是一个大型的图像数据集,用于目标检测、分割、人的关键点检测、素材分割和标题生成,在python中用COCO数据集需要安装pycocotools。但是在windows环境下无法直接通过pip安装pycocotools,安装方法如下:
先安装Visual C++ 2015 build tools:Microsoft Visual C++ Build Tools 2015,安装好后,在Terminal中执行下面命令:
pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
执行后即可安装完毕。
2.3 apex安装
apex是一款基于 PyTorch 的混合精度训练加速神器,单纯的inference实际上不需要apex模块,如果还要训练自己的数据集,就需要安装这个模块,安装方法如下:
在github上把apex项目下载或者git到本地,链接为:https://github.com/NVIDIA/apex。
在terminal中激活pytorch的环境,并且进入到apex的文件夹下,在terminal中执行:
python setup.py install
执行之后即安装完毕。
具体安装教程可以参考该博文:https://blog.csdn.net/mrjkzhangma/article/details/100704397
执行后可以执行pip list命令查看当前环境下的所有模块,如果看到环境中有刚才安装的的模块,则环境已经配置完毕!
三、YOLOv5 实现训练
3.1 准备工作
首先从github上下载下来YOLOv5,楼主这里改名为yolov5-master-cat,因为是识别小猫猫的。然后在data目录下新建Annotations, images, ImageSets, JPEGImages, labels 五个文件夹。
其中images和JPEGImages存放的是原始的图片数据集,Annotations存放的是标记后生成的xml文件,labels存放的是保存标记内容的txt文件,ImageSets存放的是训练数据集和测试数据集的分类情况。

3.2 标记数据集
工欲善其事必先利其器,没有合适的训练数据集去训练模型,哪怕YOLOv5这个目标识别框架再优秀那也只是个花架子啊。所以第一步我们要去准备我们的训练数据集,楼主这里要识别的是家里的两只活泼可爱黏人乖巧听话的小猫猫,所以准备了五六十张猫猫的照片。制作数据集时,通常使用labelImge标注工具,具体用法这里不多做阐述,因为楼主用了另一种感觉更好用的标记工具:精灵标记助手。使用起来那是相当的顺手啊,不仅操作简单上手快,还可以保存之前标注的数据集,方便后续对数据集标注内容的修改,而且相比于labelImge,RectLabel这些标注工具,精灵标记助手除了支持图片标注外,还支持文本标注,视频标注,而且还免费,真的算是业界良心了。
下载地址:http://www.jinglingbiaozhu.com/
参考博文:https://blog.csdn.net/youmumzcs/article/details/79657132
精灵标记助手标记界面如图所示:
数据集标记好后,将原始图片数据集放到images和JPEGImages文件夹中,两个文件夹均放置所有的原始图片,如图所示。
将精灵标记助手所生成的xml文件全部放入到Annotations文件夹中,如图所示。

3.3 构建数据集
在yolov5-master-cat的根目录下新建一个文件makeTxt.py,代码如下:
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
接着再新建另一个文件voc_label.py,代码如下:
# xml解析包
import xml.etree.ElementTree as ET
import pickle
import os
# os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ['person', 'boat', 'guard']
# 进行归一化操作
def convert(size, box): # size:(原图w,原图h) , box:(xmin,xmax,ymin,ymax)
dw = 1./size[0] # 1/w
dh = 1./size[1] # 1/h
x = (box[0] + box[1])/2.0 # 物体在图中的中心点x坐标
y = (box[2] + box[3])/2.0 # 物体在图中的中心点y坐标
w = box[1] - box[0] # 物体实际像素宽度
h = box[3] - box[2] # 物体实际像素高度
x = x*dw # 物体中心点x的坐标比(相当于 x/原图w)
w = w*dw # 物体宽度的宽度比(相当于 w/原图w)
y = y*dh # 物体中心点y的坐标比(相当于 y/原图h)
h = h*dh # 物体宽度的宽度比(相当于 h/原图h)
return (x, y, w, h) # 返回 相对于原图的物体中心点的x坐标比,y坐标比,宽度比,高度比,取值范围[0-1]
# year ='2012', 对应图片的id(文件名)
def convert_annotation(image_id):
'''
将对应文件名的xml文件转化为label文件,xml文件包含了对应的bunding框以及图片长款大小等信息,
通过对其解析,然后进行归一化最终读到label文件中去,也就是说
一张图片文件对应一个xml文件,然后通过解析和归一化,能够将对应的信息保存到唯一一个label文件中去
labal文件中的格式:calss x y w h 同时,一张图片对应的类别有多个,所以对应的bunding的信息也有多个
'''
# 对应的通过year 找到相应的文件夹,并且打开相应image_id的xml文件,其对应bund文件
in_file = open('data/Annotations/%s.xml' % (image_id), encoding='utf-8')
# 准备在对应的image_id 中写入对应的label,分别为
#
out_file = open('data/labels/%s.txt' % (image_id), 'w', encoding='utf-8')
# 解析xml文件
tree = ET.parse(in_file)
# 获得对应的键值对
root = tree.getroot()
# 获得图片的尺寸大小
size = root.find('size')
# 获得宽
w = int(size.find('width').text)
# 获得高
h = int(size.find('height').text)
# 遍历目标obj
for obj in root.iter('object'):
# 获得difficult ??
difficult = obj.find('difficult').text
# 获得类别 =string 类型
cls = obj.find('name').text
# 如果类别不是对应在我们预定好的class文件中,或difficult==1则跳过
if cls not in classes or int(difficult) == 1:
continue
# 通过类别名称找到id
cls_id = classes.index(cls)
# 找到bndbox 对象
xmlbox = obj.find('bndbox')
# 获取对应的bndbox的数组 = ['xmin','xmax','ymin','ymax']
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
print(image_id, cls, b)
# 带入进行归一化操作
# w = 宽, h = 高, b= bndbox的数组 = ['xmin','xmax','ymin','ymax']
bb = convert((w, h), b)
# bb 对应的是归一化后的(x,y,w,h)
# 生成 calss x y w h 在label文件中
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
# 返回当前工作目录
wd = getcwd()
print(wd)
for image_set in sets:
'''
对所有的文件数据集进行遍历
做了两个工作:
1.讲所有图片文件都遍历一遍,并且将其所有的全路径都写在对应的txt文件中去,方便定位
2.同时对所有的图片文件进行解析和转化,将其对应的bundingbox 以及类别的信息全部解析写到label 文件中去
最后再通过直接读取文件,就能找到对应的label 信息
'''
# 先找labels文件夹如果不存在则创建
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
# 读取在ImageSets/Main 中的train、test..等文件的内容
# 包含对应的文件名称
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
# 打开对应的2012_train.txt 文件对其进行写入准备
list_file = open('data/%s.txt' % (image_set), 'w')
# 将对应的文件_id以及全路径写进去并换行
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
# 调用 year = 年份 image_id = 对应的文件名_id
convert_annotation(image_id)
# 关闭文件
list_file.close()
分别运行makeTxt.py和voc_label.py。
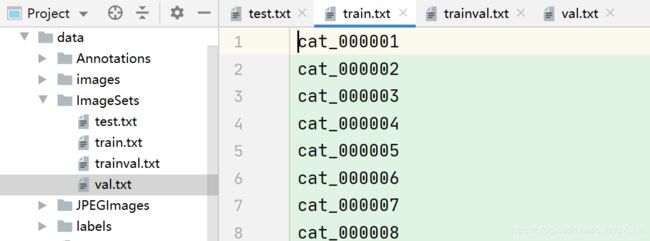
makeTxt.py主要是将数据集分类成训练数据集和测试数据集,默认按照9:1的比例进行随机分类,运行后ImagesSets文件夹中会出现四个文件,主要是生成的训练数据集和测试数据集的图片名称,如下图。同时data目录下也会出现这四个文件,内容是训练数据集和测试数据集的图片路径。
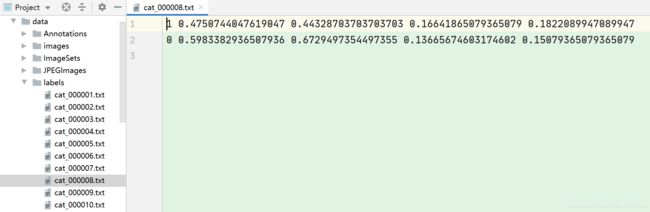
voc_label.py主要是将图片数据集标注后的xml文件中的标注信息读取出来并写入txt文件,运行后在labels文件夹中出现所有图片数据集的标注信息,如下图:
到此,本次训练所需的数据集已经全部准备好了。
3.4 文件修改
3.4.1 数据集方面的yaml文件修改
首先在data目录下,复制一份coco.yaml文件并将其重命名为cat.yaml,放在data目录下,并对cat.yaml中的参数进行配置。其中train,val,test后面分别为训练集和测试集图片的路径, nc为数据集的类别数,我这里只分了两类,names为类别的名称。这几个参数均按照自己的实际需求来修改。代码如下:
# COCO 2017 dataset http://cocodataset.org
# Download command: bash yolov5/data/get_coco2017.sh
# Train command: python train.py --data ./data/coco.yaml
# Dataset should be placed next to yolov5 folder:
# /parent_folder
# /coco
# /yolov5
# train and val datasets (image directory or *.txt file with image paths)
train: data/train.txt # 118k images
val: data/val.txt # 5k images
test: data/test.txt # 20k images for submission to https://competitions.codalab.org/competitions/20794
# number of classes
nc: 2
# class names
names: ['Gingerbread', 'Coconut-milk']
# Print classes
# with open('data/coco.yaml') as f:
# d = yaml.load(f, Loader=yaml.FullLoader) # dict
# for i, x in enumerate(d['names']):
# print(i, x)
3.4.2 网络参数方面的yaml文件修改
接着在models目录下的yolov5m.yaml文件进行修改,这里取决于你使用了哪个模型就去修改对于的文件,该项目中使用的是yolov5m模型。需要修改的代码如下:
# parameters
nc: 2 # number of classes
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
3.4.3 train.py中的一些参数修改
最后,在根目录中对train.py中的一些参数进行修改,主要参数解释如下:
# 训练的epoch,1个epoch等于使用训练集中的全部样本训练一次,值越大模型越精确,训练时间也越长。
parser.add_argument('--epochs', type=int, default=300)
# batch_size指一次训练所选取的样本数,显卡垃圾的话,就调小点
parser.add_argument('--batch-size', type=int, default=8)
# 使用网络参数方面的yaml文件
parser.add_argument('--cfg', type=str, default='models/yolov5m.yaml', help='*.cfg path')
# 使用数据集方面的yaml文件
parser.add_argument('--data', type=str, default='data/boat.yaml', help='*.data path')
# 网络输入图片大小,默认[640,640],nargs='+'表示参数可设置一个或多个
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='train,test sizes')
# 训练时启用矩形训练,可显著的减少推理时间
parser.add_argument('--rect', action='store_true', help='rectangular training')
# 值为空时,训练时默认使用计算机自带的显卡或CPU
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
3.5 训练模型
全部配置好后,直接执行train.py文件开始训练,这时候就到了考验显卡的时候,可以耐心的等上一两个小时,可以吃个瓜,看个小电影啥的,千万别手痒玩什么3A大作,否则电脑爆炸还得重新训练。
训练好后会在根目录下的weight文件夹得到如下文件:

其中best.pt是300次训练中得到的最好的一个权重,last.pt是最后一次训练所得的权重。
四、YOLOv5 实现检测
有了训练好的权重后,就可以就行目标检测测试了。直接在根目录的detect.py中进行调试,主要参数解释如下:
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# 使用训练所产生的权重
parser.add_argument('--weights', type=str, default='weights/best.pt', help='model.pt path')
# 需要进行目标检测的视频的路径
parser.add_argument('--source', type=str, default='data/猫猫识别.mp4', help='source') # file/folder, 0 for webcam
# 检测后所输出视频结果的路径
parser.add_argument('--output', type=str, default='inference/output', help='output folder') # output folder
# 网络输入图片大小
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
# 目标置信阈值,检测到的对象属于特定类(狗,猫,香蕉,汽车等)的概率
parser.add_argument('--conf-thres', type=float, default=0.65, help='object confidence threshold')
# 非极大值抑制(NMS)的交并比(IOU)阈值
parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS')
# 输出视频格式,默认mp4
parser.add_argument('--fourcc', type=str, default='mp4v', help='output video codec (verify ffmpeg support)')
# 值为空时,训练时默认使用计算机自带的显卡或CPU
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', default=True, help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
opt = parser.parse_args()
opt.img_size = check_img_size(opt.img_size)
print(opt)
修改好参数后,直接执行detect.py文件,下面是输出视频的截图,可能是小猫的特征不是很明显,尤其是侧脸的识别效果并不是很好,训练数据集如果量大一点应该会有更好的效果。
