YOLOv1 解读:使用 unified system/ one-stage 实现目标检测
Title: You Only Look Once: Unified, Real-Time Object Detection(2016)
Link: Paper Website
Tips:
- two-stage 和 one-stage 方法的区别:检测系统的目标是输出物体位置和类别,R-CNN 把位置和类别分成两个阶段,第二阶段使用了分类器;YOLO 用一个网络同时输出位置和类别,使用的是回归方法。
- YOLO v1 的优缺点(1. Introduction 2.4 Limitations of YOLO)
- YOLO v1 具体流程(2. Unified Detection)
Summary:
YOLO 的设计思想很好理解,全文也通俗易懂,读这篇论文我们首先要理解设计思想和方法,多阶段和单阶段检测的流程区别。
学习模型之间比较异同的方法以及模型结合的思想。
问题背景
- 之前 two-stage 方法如 R-CNN 把检测问题分成两部分,先生成候选区域(region proposal),再用分类器对区域分类,多阶段训练导致不易优化
创新点
- 把检测当作回归问题,用一个网络输出位置和类别,实现了一个 unified system,从检测的角度是 one-stage的
相关文章:
一文读懂 YOLOv1,v2,v3,v4 发展史
YOLOv2 解读:使 YOLO 检测更精准更快,尝试把分类检测数据集结合使用
YOLOv3 解读:小改动带来的性能大提升
YOLOv4 解读:CV 同学必读的目标检测技巧大合集
论文目录
- Abstract
- 1. Introduction
- 2. Unified Detection
- 2.1. Network Design
- 2.2. Training
- 2.3. Inference
- 2.4. Limitations of YOLO
- 3. Comparison to Other Detection Systems
- 4. Experiments
- 4.1. Comparison to Other Real-Time Systems
- 4.2. VOC 2007 Error Analysis
- 4.3. Combining Fast R-CNN and YOLO
- 4.4. VOC 2012 Results
- 4.5. Generalizability: Person Detection in Artwork
- 5. Real-Time Detection In The Wild
- 6. Conclusion
Abstract
之前的方法把检测当作分类问题,而这篇文章把检测当作回归问题。
这个单独的神经网络可以直接从完整图像中预测边界框和类的概率。
A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation
YOLO特点
- 速度快:基础的 YOLO 模型以每秒45帧的速度实时处理图像。
- 与 state-of-the-art 检测系统相比,YOLO 会产生更多的定位错误,但预测背景假阳性(FP)的可能性较小
- 学习的特征有普遍性:YOLO 学习非常普通的对象表示形式。 从自然图像推广到艺术品等其他领域时,它的性能优于其他检测方法(DPM 和 R-CNN)。
1. Introduction
研究现状
当时的检测系统都是把分类器用于检测,比如 DPM 和 R-CNN。
比如 DPM 之类的系统使用滑动窗口方法,分类器在整个图像上均匀分布的位置运行。而 R-CNN 系统分为两个阶段(two-stage),第一步用 region proposal 方法在图像上生成潜在的边界框(这些地方可能包含物体),第二步分类器在这些边界框的位置进行分类。
这种流水线式的网络运行慢也难以优化,因为不同的组件必须单独训练。
新思路
把检测问题当作一个单独的回归问题(one-stage + regression):输入一幅图片,经过一个网络,直接输出边界框的坐标和类别概率。使用这样的网络,你只需要看一次图片(you only look once: YOLO)就能知道物体的位置和类别。
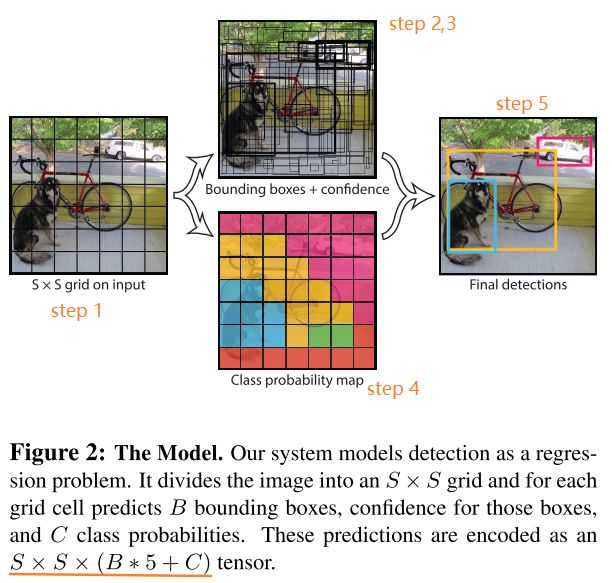
图 1 展示的就是 YOLO 检测系统:输入一个图片,一个卷积网络同时预测多个物体的位置和类别。
A single convolutional network simultaneously predicts multiple bounding boxes and class probabilities for those boxes

YOLO 优点
- 快。因为回归问题没有复杂的流程(pipeline)。
- 可以基于整幅图像预测(看全貌而不是只看部分)。与基于滑动窗口和区域提议的技术不同,YOLO在训练和测试期间会看到整个图像,因此它隐式地编码有关类及其外观的上下文信息。因为能看到图像全貌,与 Fast R-CNN 相比,YOLO 预测背景出错的次数少了一半。
- 学习到物体的通用表示(generalizable representations),泛化能力好。因此,当训练集和测试集类型不同时,YOLO 的表现比 DPM 和 R-CNN 好得多,应用于新领域也很少出现崩溃的情况。
YOLO 缺点
与 state-of-the-art 检测系统相比:
- 准确率低;
- 很多时候只有小物体的预测精确些。
2. Unified Detection
设计思想
用一个神经网络把检测任务中分离的元素统一(unify)起来,也就是同时预测位置和类别。
从整幅图像提取特征,也就是网络可以考虑到图片全貌以及每个物体。
这种设计利于端到端(end-to-end)的训练以及提升速度。
具体方法
- 将输入图像划分为 S×S(文中 S=7)网格(grid),如果目标的中心落入网格单元,则该网格单元负责检测该目标。
- 每个网格单元预测 B(文中 B=2) 个边界框和这些框的置信度得分。这个分数反映这个框包含物体的概率 Pr(Object) 以及预测框的位置准确性 IOU,所以置信分数也由这两部分定义:
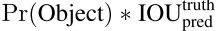
- 每个 bounding box 都要包含 5 个预测值,x, y, w, h, confidence。(x,y)框中心是相对于网格单元的坐标,w 和 h 是框相当于整幅图的宽和高,confidence 代表该框于 ground truth 之间的 IOU(框里没有物体分数直接为 0 )。
- 设计思想说了,位置和类别同时预测,所以每个单元格除了输出 bounding box 也输出物体的条件概率(该物体属于某一类的概率,当然这些概率以包含对象的网格单元为条件)。每个网格单元输出一个概率集合,不考虑预测几个 bounding box。
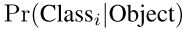
- 测试阶段,在测试时,我们将条件分类概率与各个框的置信度预测相乘,作为每个框特定于每个类的置信分数(这个分数编码了类别和位置两部分信息)。
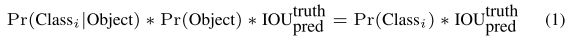
2.1. Network Design
这一部分主要讲输入到输出中间的 CNN。这个网络受 GoogLeNet 启发,采取了类似的结构。
2.2. Training
这一部分讲训练过程和实验设置(具体的需要看论文)。
首先 ImageNet 1000类 竞赛数据集上对卷积层进行预训练,然后再把网络用于检测任务。
网络的最后一层同时输出类别概率和边界框坐标,这里做了一些正则化处理。bounding box 的宽高除以图像的宽高,横纵坐标也参数化为相对于网格单元的偏移量,所以 w,h,x,y都限制在(0,1)。
所有层使用的激活函数为 Leaky ReLU。
计算损失采用的是平方和损失(sum-squared error)。
在训练时,只希望一个边界框预测变量对一个对象负责,这通过保证最高的 IOU 实现。
为了避免过拟合,使用了 dropout + data augmentation。
2.3. Inference
就像在训练中一样,预测测试图像的检测仅需要进行一次网络评估。 在 PASCAL VOC 上,网络可以预测每个图像 98 (7×7×2)个边界框以及每个框的类别概率。
一般一个物体属于一个网格单元,网络能为每个物体预测一个框,但对于一些大物体或靠近单元格边界的物体,需要采取非极大抑制(Non-maximal suppression)辅助。
2.4. Limitations of YOLO
- 空间限制:一个单元格只能预测两个框和一个类别,这种空间约束必然会限制预测的数量;
- 难扩展:模型根据数据预测边界框,很难将其推广到具有新的或不同寻常的宽高比或配置的对象。
- 网络损失不具体:无论边界框的大小都用损失函数近似为检测性能,但对于大边界框来说,小损失影响不大,对于小边界框,小错误对 IOU 影响较大。
3. Comparison to Other Detection Systems
检测系统一般的流程都是先提取图形特征(Haar, SIFT, HOG, convolutional features),再用classifiers 和 localizers 分类和定位,下面比较 YOLO 与已有方法的异同(有点儿像 Related Work)。
Deformable parts models(DPM)
DPM 采取滑动窗口方法用于检测,用一个不相交的流程实现提取静态特征,区域分类,预测边界框。
YOLO 把特征提取,分类,定位任务以及非极大抑制(non-maximal suppression)和上下文推理(contextual reasoning)结合起来同时实现,特征不是静态的而是在线动态优化生成的,比 DPM 更快准确度更高。
R-CNN
R-CNN 及其变体采用 region proposals 而不是滑动窗口法找物体,是一种多阶段方法。Selective Search 找可能的边界框,CNN 提取特征,SVM 为 box 预测分数。调网络的时候需要分开调,运行慢。
YOLO 与 R-CNN 相似的地方是在网格单元找可能的边界框,用 CNN 提取特征。不同的是,加在网格单元的空间限制有助于防止同一个目标的重复检测,预测的边界框也少(98 个),还有把多个部分结合成一个阶段。
Other Fast Detectors
Fast 和 Faster R-CNN 通过共享计算和 CNN 生成区域(代替 R-CNN 的 Selective Search)来加速 R-CNN,也有一些加速 DPM 的方法(例如级联,用 GPU),但他们的速度相对较慢。
与这些优化单个组件的方法不同,YOLO 把流程中各部分合在一起优化。
Deep MultiBox
Deep MultiBox 使用 CNN 预测 RoI( R-CNN 使用 Selective Search)。
Multi-Box无法执行常规的对象检测,并且仍然只是较大检测流水线中的一部分,需要进一步的图像块分类。 YOLO 和 MultiBox 都使用卷积网络来预测图像中的边界框,但是 YOLO 是一个完整的检测系统。
OverFeat
OverFeat 使用滑动窗口法检测,是一个不连贯的检测系统(需要先分类再定位),优化也只能针对定位任务优化,和 DPM 一样,它只能根据图像的局部信息预测。
OverFeat 无法根据全局上下文推理,因此需要进行大量后期处理才能产生连贯的检测结果。
MultiGrasp
YOLO 的网格方法用于边界框预测基于MultiGrasp 系统,但 grasp detection 是个更简单的任务。它只需要为一幅图像的一个物体预测一个合适的区域,不用考虑尺寸,边界类别等。
4. Experiments
实验分析以及看模型的泛化能力。
4.1. Comparison to Other Real-Time Systems

比较快速检测器的性能和速度。 Fast YOLO是有记录的用于PASCAL VOC检测的最快的检测器,仍然是任何其他实时检测器的两倍。 YOLO比快速版本的精度高10 mAP,但速度仍远远高于实时水平。
4.2. VOC 2007 Error Analysis
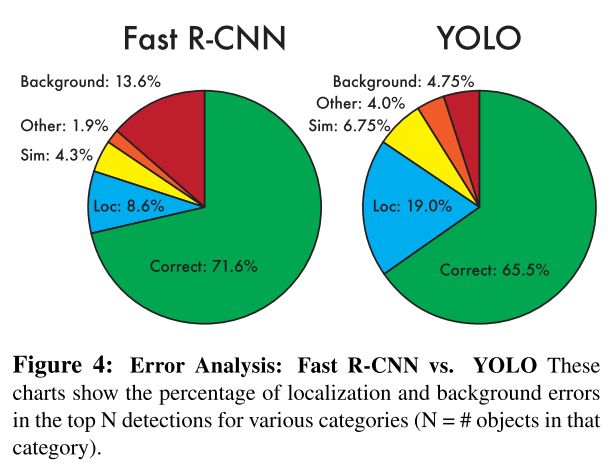
分析 YOLO 和 Fast R-CNN 错误预测的分析。 从图 4 可以看出,YOLO 出错的地方主要是定位(localization),而 Fast R-CNN 出错的地方主要是背景检测。
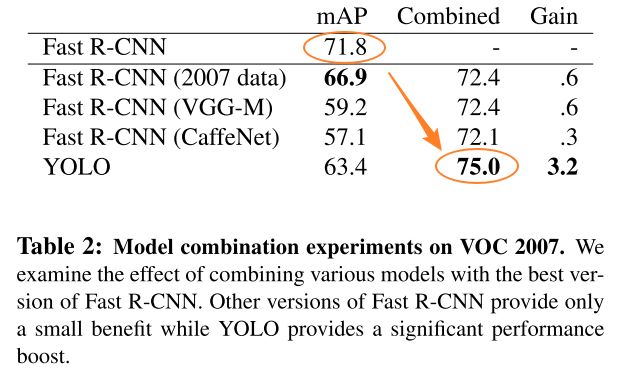
4.3. Combining Fast R-CNN and YOLO
与Fast R-CNN相比,YOLO 产生的背景错误少得多。 通过使用 YOLO 消除 Fast R-CNN 的背景检测,可以显着提高性能。 对于 R-CNN 预测的每个边界框,我们都会检查 YOLO 是否预测了类似的框。 如果是这样,我们将根据 YOLO 预测的概率和两个框之间的重叠来对该预测进行增强。
从表 3 可以看出,把两者结合可以提高 mAP,但这种结合不利于 YOLO 的速度。
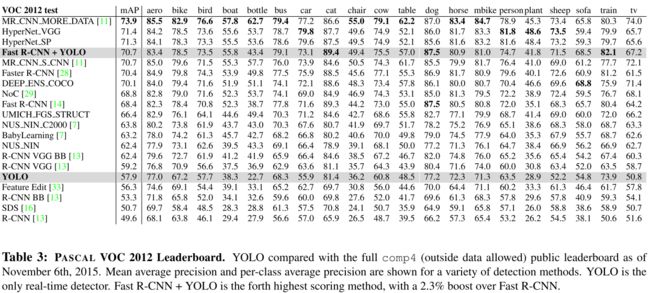
4.4. VOC 2012 Results
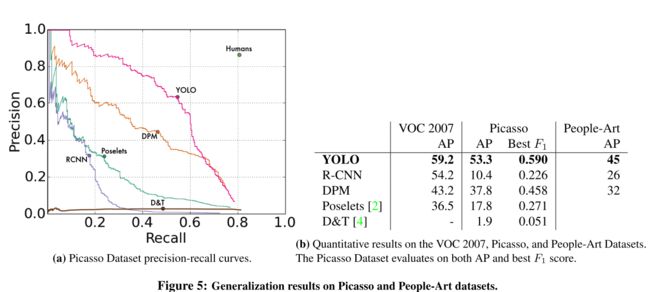
4.5. Generalizability: Person Detection in Artwork
图 5 展示 YOLO 和其他检测方法之间的泛化能力。
5. Real-Time Detection In The Wild
我们将YOLO连接到网络摄像头,并验证其是否保持实时性能。最终的系统是交互式的并且引人入胜。 虽然 YOLO 分别处理图像,但将其附加到网络摄像头后,它可以用作跟踪系统,在物体移动和外观变化时对其进行检测。
可以到网站看相关 demo。
6. Conclusion
本文提出了检测领域的一个新的联合模型 YOLO,它的结构简单,能直接处理整幅图像。
与基于分类器的方法不同,YOLO在直接与检测性能相对应的损失函数上进行训练,而整个模型则在联合下进行训练。
Fast YOLO 是文献中最快的通用目标检测器,YOLO推动了实时目标检测的最新发展。 YOLO 还很好地推广到了新领域,使其非常适合依赖快速,强大的对象检测的应用程序