从零开始搭建深度学习验证码识别模型
文章目录
- 从零开始搭建深度学习验证码识别模型
- CNN模型与图像识别
- 验证码数据集介绍
- 生成数据集
- 生成EasyCaptcha
- 生成Kcaptcha
- 搭建模型
- EasyNet模型
- KCapNet模型
- 模型训练与参数选择
- 优化方法与超参数
- 数据集划分
- 模型分析
- EasyNet算力计算
- KCap算力计算
- EasyNet
- KCapNet
从零开始搭建深度学习验证码识别模型
CNN模型与图像识别
CNN模型是图像问题的基本深度学习算法,使用CNN算法不用人工从图片中提取特征,更加end2end,符合表示学习的特征,避免繁琐、低效的特征工程。CNN算法目前在CV领域已经成为基本方法之一。
CNN模型的核心在于,利用卷积核在特征图上进行运算,从中提取到充足的特征。在CNN的研究发现,在浅层网络,CNN模型可以提取到部分简单的特征,如轮廓等,而深层CNN则将基础特征进行整合,提取到更加复杂的特征,从而能够对图片中的内容进行特征提取。
CNN的核心在于卷积运算规则,其大致为:
C N N ( m a p ) = ∑ i = 0 f h ∑ j = 0 f w f i l t e r h , w ⋅ s l i c e ( m a p ) h , w CNN(map)=\sum\limits_{i=0}^{f_h} \sum\limits_{j=0}^{f_w} filter_{h,w} \cdot slice(map)_{h,w} CNN(map)=i=0∑fhj=0∑fwfilterh,w⋅slice(map)h,w
其中, s l i c e ( ⋅ ) slice(\cdot) slice(⋅)为特征图切片运算,如当 f i l t e r filter filter为 3 3 3时,则 m a p map map将会根据步长,从中进行切片,并与卷积核进行element-wise乘积运算后并求和。
在CV诸多任务中,卷积层往往被用来做特征提取,而到具体的任务时,需要拼接更多的网络,如拼接全连接网络进行分类任务。
验证码识别,本质上也为一个图像识别任务。在对象识别模型中,通常需要从图像中尽可能识别多的对象,并以框的形式对其位置进行标记。验证码识别也可采用该方式实现,该方法为multi-stage方法,即:通常使用对象识别模型,识别图片中的文字,并用框标记出文字所在位置,再利用CNN和FCN的结构对所识别的文字进行分类。并且,若为文档OCR识别,输出层还可能借助LSTM等RNN结构网络。
考虑到验证码通常位数有限,即4位、5位较为常见,因此该模型采用end2end multi-task方法也可满足需求,且模型复杂度并不高。multi-task任务可简单的理解为,有多个输出层负责不同任务的输出,其弊端在于扩展性低,如只能识别固定数量的对象。
验证码数据集介绍
所有训练数据均以验证码图片内容为名称命名,如2ANF.jpg,因此可以保证训练数据没有重复项,根据文件名即可获取样本label。
数据集下载:Dataset-Google Drive for Easy Captcha
数据规格:48,320张验证码图片,全由
Easy Captcha框架生成,大小为 120 × 80 120 \times 80 120×80。
验证码示例:

EasyCaptch项目主页
EasyCaptcha验证码特点在于可以构造Gif动态验证码,而其他验证码则显得相对简单,主要在于该验证码间隔较开,易于区分,因此识别较为简单。根据对上例中的验证码分析可知,验证码由不定位置的1-2个圆圈与曲线构成噪音,对文本加以干扰,文字颜色可变。从布局来看,文字的布局位置相对固定,且间隔也相对固定,这无疑也简化了识别过程。
数据集下载:Dataset-Google Drive for Kaptcha
数据规格:52,794张验证码图片,全由
Kaptcha生成,大小为 200 × 50 200 \times 50 200×50。
验证码示例:

Kaptcha项目主页
相对而言,Kaptcha验证码相对而言文本排布默认更加紧凑,但是文字间距再kaptcha中是一个可以调节的超参数。Kaptcha较难识别的主要原因在于其文本存在可能的扭曲形变,并且形变状态不定,因此模型需要能够克服该形变,方可较为准确的识别,因此Kaptcha识别较captcha困难,并且准确度指标会有所下降。
注:在直接使用模型时需要严格注意验证码规格,这主要在于图片过小会导致CNN过程异常。若对图片进行分辨率调整,长宽比不一,将导致严重形变,导致识别精度下降。
生成数据集
基于上述两个验证码框架,可以使用其提供的开源库进行验证码生成。
生成EasyCaptcha
如下代码所示,主要是从配置中获取验证码的配置,并使用给定的框架进行验证码生成,并最终输出到文件中。
public boolean generate() {
String outputFolder = config.get(ConfigConstants.OUT_DIR);
int width = Integer.parseInt(config.get(ConfigConstants.WIDTH, "120"));
int height = Integer.parseInt(config.get(ConfigConstants.HEIGHT, "80"));
int len = Integer.parseInt(config.get(ConfigConstants.LENGTH));
SpecCaptcha captcha = new SpecCaptcha(width, height, len);
captcha.setCharType(Captcha.TYPE_DEFAULT);
try {
captcha.setFont(Captcha.FONT_3);
} catch (IOException | FontFormatException e1) {
e1.printStackTrace();
return false;
}
String codes = captcha.text();
if (LOG.isInfoEnabled()) {
LOG.info("Generating " + codes + "...");
}
return ImageOutputUtil.writeToFile(captcha, outputFolder, codes);
}
为提升图片生成的效率,我们使用多线程的方式,同时生成:
public class CaptchaTaskRunner implements Runnable {
private static final Logger LOG = Logger.getLogger(CaptchaTaskRunner.class);
private CaptchaGenerator generator;
@Override
public void run() {
boolean success = generator.generate();
if (success) {
if (LOG.isInfoEnabled()) {
LOG.info("Complete!");
}
} else {
if (LOG.isInfoEnabled()) {
LOG.info("Failed!");
}
}
}
/**
* @return CaptchaGenerator return the generator
*/
public CaptchaGenerator getGenerator() {
return generator;
}
/**
* @param generator the generator to set
*/
public void setGenerator(CaptchaGenerator generator) {
this.generator = generator;
}
}
代码中CaptchaGenerator即为generate()方法的接口类,在线程池中提交若干任务,最终都由CaptchaTaskRunner实例进行生成。
生成Kcaptcha
相较于EasyCaptcha,Kcaptcha的配置项更多,因此其识别更加困难,为增强最终模型的可信度与拟合能力,可随机地产生若干配置,来生成验证码:
public KaptchaGeneratorWorker(me.zouzhipeng.config.Config config) {
Properties prop = new Properties();
prop.put(Constants.KAPTCHA_BORDER, true);
prop.put(Constants.KAPTCHA_BORDER_COLOR,
String.join(",", rand.nextInt(256) + "", rand.nextInt(256) + "", rand.nextInt(256) + ""));
prop.put(Constants.KAPTCHA_IMAGE_WIDTH, config.get(ConfigConstants.WIDTH, "200"));
prop.put(Constants.KAPTCHA_IMAGE_HEIGHT, config.get(ConfigConstants.HEIGHT, "50"));
String textColor = config.get(ConfigConstants.TEXT_COLOR);
if (null == textColor) {
textColor = String.join(",", rand.nextInt(256) + "", rand.nextInt(256) + "", rand.nextInt(256) + "");
}
prop.put(Constants.KAPTCHA_TEXTPRODUCER_FONT_COLOR,
textColor);
prop.put(Constants.KAPTCHA_TEXTPRODUCER_CHAR_LENGTH, config.get(ConfigConstants.LENGTH, "4"));
prop.put(Constants.KAPTCHA_TEXTPRODUCER_FONT_NAMES, "彩云,宋体,楷体,微软雅黑,Arial,SimHei,SimKai,SimSum");
if (Boolean.parseBoolean(config.get(ConfigConstants.NOISE_SAME_TEXT_COLOR, "true"))) {
prop.put(Constants.KAPTCHA_NOISE_COLOR, textColor);
} else {
prop.put(Constants.KAPTCHA_NOISE_COLOR,
String.join(",", rand.nextInt(256) + "", rand.nextInt(256) + "", rand.nextInt(256) + ""));
}
prop.put(Constants.KAPTCHA_TEXTPRODUCER_CHAR_STRING, "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz012345679");
this.output = config.get(ConfigConstants.OUT_DIR);
Config kaptchaConfig = new Config(prop);
producer = kaptchaConfig.getProducerImpl();
}
如上述构造函数,针对Kaptcha进行了所需配置项的配置。
而生成部分,同EasyCaptcha相似,如下:
public boolean generate(String folder) {
String text = producer.createText();
BufferedImage imageBuffered = producer.createImage(text);
if (LOG.isInfoEnabled()) {
LOG.info("Generating " + text + "...");
}
return ImageOutputUtil.writeToFile(imageBuffered, folder, text, "jpg");
}
同样地,采用多线程对图片进行生成,以得到大量验证码训练图片。
搭建模型
针对两个不同的数据集,本项目设计了两个不同的模型,但是总体上都是基于CNN和FCN结构的分类任务。在诸多OCR任务中,通常会使用multi-stage方法设计模型,即:通常使用对象识别模型,识别图片中的文字,并用框标记出文字所在位置,再利用CNN和FCN的结构对所识别的文字进行分类。并且,若为文档OCR识别,输出层还可能借助LSTM等RNN结构网络。
考虑到验证码通常位数有限,即4位、5位较为常见,因此该模型采用end2end multi-task方法也可满足需求,且模型复杂度并不高。
针对EasyCaptcha验证码,其产生的验证码较容易区分,字符分隔较开,且变形选项较少,因此使用很简单的模型即可达到较高的精度,在本项目的模型中,验证集准确度可达到 98 − 99 98-99% 98−99左右。
而对于Kaptcha验证码,其存在较多可选的配置项,并且会在验证码中间添加噪音扰动,因此识别较为困难,使用EasyCaptcha的模型,精度仅能达到70%左右,准确度较低,Kaptcha模型适当地加大了CNN网络的深度,并增加了一层全连接隐藏层,在验证集上达到93-94%的准确度。
在训练过程中,采用长度为4的验证码,其中验证码中可选字符为:a-zA-Z0-9,共62个可能字符。
下面为两个模型:EasyNet, KCapNet的详细介绍。
EasyNet模型
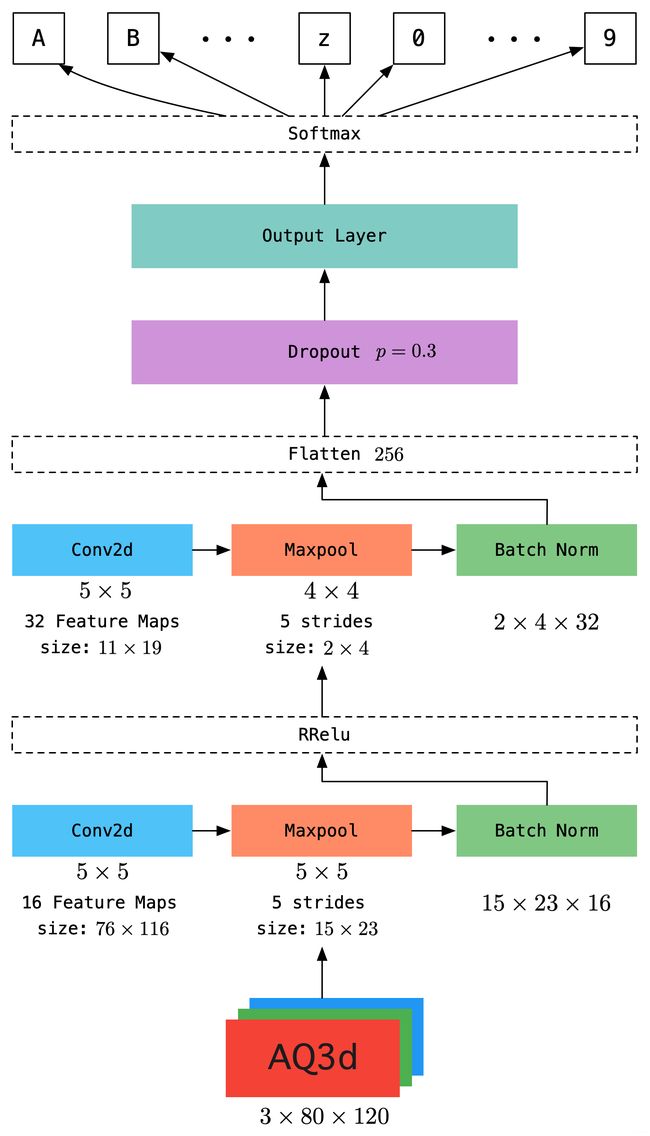
EasyNet模型由2层卷积层和4个输出层构成,该模型结构细节如下:
- 第一层卷积,卷积核大小为 5 × 5 5 \times 5 5×5,步长为1,通道为16,参数量为 3 × 5 × 5 × 16 3 \times 5 \times 5 \times 16 3×5×5×16,得到大小 76 × 116 76\times 116 76×116的特征图共16个;
- 第二层为最大池化层,无参数,池化核大小为 5 × 5 5\times 5 5×5,步长为5,得到特征图大小为 15 × 23 15 \times 23 15×23;
- 第三层为批归一化层,避免过拟合并加速模型收敛。根据效果,同时还可尝试使用shortcut方法。归一化后,采用RReLu激活函数;
- 第四层为卷积层,卷积核大小为 5 × 5 5 \times 5 5×5,步长为1,通道数为32,得到特征图大小为 11 × 19 11 \times 19 11×19,参数量为 16 × 5 × 5 × 32 16 \times 5 \times 5 \times 32 16×5×5×32;
- 第五层为最大池化层,无参数,池化核大小为 5 × 5 5 \times 5 5×5,步长为5,得到特征图大小为 2 × 4 2 \times 4 2×4,无参数;
- 第六层仍为批归一化层,并采用RReLu函数激活;
- 第七层为Dropout层,经过第二个卷积后,将得到特征图展开,得到特征向量维度为256维,对256的特征向量进行Dropout处理,避免过拟合,采用的失效概率为 p = 0.3 p=0.3 p=0.3;
- 第八层为输出层,用于得到验证码序列,由于模型为multi-task,因此输出层有4个(根据验证码中字符长度确定),使用softmax激活,参数量为 4 × 256 × 62 4\times 256 \times 62 4×256×62。
KCapNet模型
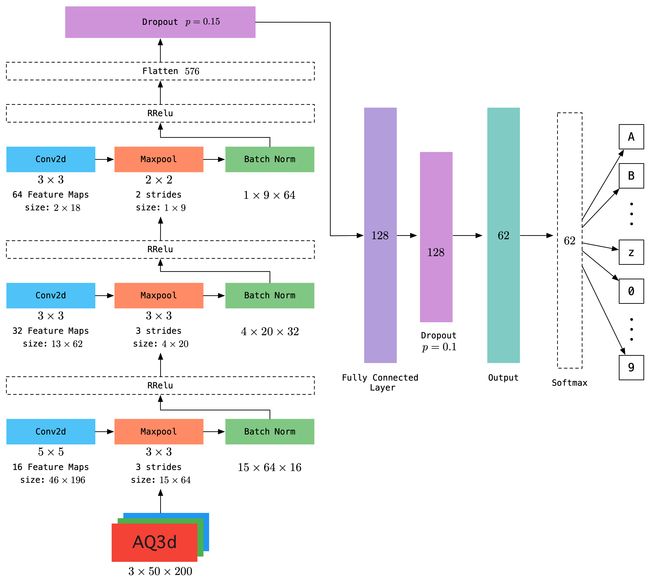
KCapNet共由3个卷积层,1个全连接层,4个输出层组成,以下为模型具体细节:
- 第一层为卷积层,卷积核大小为 5 × 5 5 \times 5 5×5,步长为1,通道数为16,输入图片大小为 50 × 200 50 \times 200 50×200,因此可得到16个大小为 46 × 196 46 \times 196 46×196的特征图,参数量为 3 × 5 × 5 × 16 3\times 5 \times 5 \times 16 3×5×5×16;
- 第二层为最大池化层,无参数,池化核大小为 3 × 3 3 \times 3 3×3,步长为3,得到特征图大小为 15 × 64 15 \times 64 15×64;
- 第三层为批归一化层,在归一化结束后,使用RReLu激活函数激活;
- 第四层为第二个卷积层,卷积核大小为 3 × 3 3 \times 3 3×3,通道数为32,可得到大小为 13 × 62 13 \times 62 13×62的特征图32个,参数量为 16 × 3 × 3 × 32 16 \times 3 \times 3 \times 32 16×3×3×32;
- 第五层为最大池化层,无参数,池化核大小为$ 3 \times 3$,步长为3,无参数,可将特征图压缩为 4 × 20 4 \times 20 4×20;
- 第六层为批归一化层,并使用RReLU函数激活;
- 第七层为第三个卷积层,卷积核大小为 3 × 3 3 \times 3 3×3,步长为1,通道数为64,可得到大小为 2 × 18 2 \times 18 2×18的特征图64个,参数量为 32 × 3 × 3 × 64 32 \times 3 \times 3 \times 64 32×3×3×64;
- 第八层为最大池化层,池化视野为 2 × 2 2 \times 2 2×2,步长为2,无参数,特征图被进一步压缩为 1 × 9 1 \times 9 1×9;
- 第九层为归一化层,归一化后使用RReLu函数激活;
- 第十层为Dropout层,输入为第九层输出展开后的特征向量,维度为576维,该层采用$ p = 0.15$ 的概率失效一定神经元;
- 第十一层为全连接层,输入为第十层的输出,维度为576维,全连接层输出维度为128维,参数量为 576 × 128 576 \times 128 576×128,并使用RReLU函数激活;
- 第十二层为全连接的Dropout层,神经元失效概率为 p = 0.1 p=0.1 p=0.1;
- 第十三层为输出层,根据multi-task数量,为4个输出层,维度为62维,使用softmax函数激活,参数量为 4 × 128 × 62 4 \times 128 \times 62 4×128×62;
模型部分参数未描述,由于是少量参数,相比之下可以忽略,如RReLu中的参数。
模型训练与参数选择
优化方法与超参数
在该模型中,采用了Adam作为优化算法,并设定学习率为0.001,可达到较好效果。在模型训练过程中,尝试使用较大学习率,如0.01, 0.1, 0.05等,均不如低学习率收敛效果好。上述两个模型,均在Google Colab Pro上使用P100训练,该算力可胜任batch至少为1024的配置,在EasyNet模型中使用了512的batch,而KCapNet使用1024的batch。
该batch设置未达到算力极限,如有条件可测试,但是不推荐模型采用较大batch,而应尽可能选择合理的batch。
模型训练过程中,优化算法未使用学习率衰减算法。
在模型训练过程中,对于EasyNet,采用 p = 0.3 p=0.3 p=0.3的Dropout能达到较好效果,若采用 0.4 ∼ 0.5 0.4 \sim 0.5 0.4∼0.5效果略差,但精度仍然可观,可见对于EasyNet其数据简单因而模型即便简单也仍能达到较好效果。
而对于KCapNet,Dropout从最初的 0.5 0.5 0.5拟合效果较差,大概稳定在$85% 上 下 , 而 逐 步 降 低 D r o p o u t 拟 合 能 力 逐 渐 提 升 , 最 终 在 上下,而逐步降低Dropout拟合能力逐渐提升,最终在 上下,而逐步降低Dropout拟合能力逐渐提升,最终在p_1=p_2=0.2 时 效 果 较 好 , 最 终 采 用 时效果较好,最终采用 时效果较好,最终采用p_1=0.15,p_2=0.1$得到最终模型,其训练集精度为 95 % 95\% 95%左右,验证集精度为 93 ∼ 94 % 93\sim 94 \% 93∼94%。
数据集划分
在模型训练过程中,默认采用 6 : 1 : 1 6:1:1 6:1:1的分配比切分训练集、验证集、测试集,切分过程大致为:
- 按3:1第一次切分,其中 75 % 75\% 75%为训练集;
- 对上述剩余的 25 % 25\% 25%进行 1 : 1 1:1 1:1切分,得到训练集及测试集。
根据需要,开发者自行训练模型时,可根据需要手动指定数据集切分比例。
模型分析
为了能够尽量评估运算所需算力,可以对模型的内存消耗进行评估,此处忽略激活函数中的参数,偏置等少量参数,模型的算力要求应等于参数量+输入输出+梯度与动量,根据神经网络反向传播理论,在更新参数时需要计算下一层输出关于上一层参数的梯度,因此参数量==梯度,而在优化方法中需要保存动量,以记录之前参数更新的历史记录,因此参数量==动量,而对于Adam优化器,则更有动量==2参数量,因此整个模型的算力要求为:
M E M = W ∗ 4 + I + O MEM = W*4+I+O MEM=W∗4+I+O
通常网络中使用的数据类型为Float32类型,其占4 Byte,于是便可通过存储量来计算内存消耗。
EasyNet算力计算
根据下表统计,该模型算力大致要求为:1.9 MB /sample。
| 层 | 参数量 | 特征图 | 所需内存 |
|---|---|---|---|
| Input | 0 | 3 × 80 × 120 = 19200 3 \times 80 \times 120=19200 3×80×120=19200 | 75 KB |
| Conv1 | 3 × 5 × 5 × 16 = 1200 3 \times 5 \times 5 \times 16 = 1200 3×5×5×16=1200 | 76 × 116 × 16 = 141056 76\times 116 \times 16=141056 76×116×16=141056 | 569.8 KB |
| Maxpool1 | 0 | 16 × 15 × 23 = 5520 16 \times 15 \times 23=5520 16×15×23=5520 | 21.6 KB |
| BN1 | 2 × 16 = 32 2 \times 16=32 2×16=32 | 16 × 15 × 23 = 5520 16 \times 15 \times 23=5520 16×15×23=5520 | 22.0 KB |
| Conv2 | 16 × 5 × 5 × 32 = 12800 16 \times 5 \times 5 \times 32=12800 16×5×5×32=12800 | 11 × 19 × 32 = 6688 11 \times 19 \times 32 = 6688 11×19×32=6688 | 226.1 KB |
| Maxpool2 | 0 | 2 × 4 × 32 = 256 2 \times 4 \times 32 = 256 2×4×32=256 | 1 KB |
| BN2 | 2 × 32 = 64 2\times 32=64 2×32=64 | 2 × 4 × 32 = 256 2 \times 4 \times 32 = 256 2×4×32=256 | 2 KB |
| Output | 4 × 256 × 62 = 63488 4\times 256 \times 62=63488 4×256×62=63488 | 4 × 62 = 248 4 \times 62=248 4×62=248 | 993.0 KB |
KCap算力计算
根据下表统计,其算力要求大致为:2.9 MB /sample。
| 层 | 参数量 | 特征图 | 所需内存 |
|---|---|---|---|
| Input | 0 | 3 × 50 × 200 = 30000 3 \times 50 \times 200=30000 3×50×200=30000 | 117.2 KB |
| Conv1 | 3 × 5 × 5 × 16 = 1200 3 \times 5 \times 5 \times 16=1200 3×5×5×16=1200 | 46 × 196 × 16 = 144256 46 \times 196 \times 16=144256 46×196×16=144256 | 582.3 KB |
| Maxpool2 | 0 | 15 × 64 × 16 = 15360 15 \times 64 \times 16=15360 15×64×16=15360 | 60 KB |
| BN1 | 2 × 16 = 32 2 \times 16=32 2×16=32 | 15 × 64 × 16 = 15360 15 \times 64 \times 16=15360 15×64×16=15360 | 60.5 KB |
| Conv2 | 16 × 3 × 3 × 32 = 4608 16 \times 3 \times 3 \times 32=4608 16×3×3×32=4608 | 13 × 62 × 32 = 25792 13\times 62 \times 32=25792 13×62×32=25792 | 172.75 KB |
| Maxpool2 | 0 | 4 × 20 × 32 = 2560 4\times 20 \times 32=2560 4×20×32=2560 | 10 KB |
| BN2 | 2 × 32 = 64 2 \times 32=64 2×32=64 | 4 × 20 × 32 = 2560 4\times 20 \times 32=2560 4×20×32=2560 | 11 KB |
| Conv3 | 32 × 3 × 3 × 64 = 18432 32 \times 3 \times 3 \times 64=18432 32×3×3×64=18432 | 2 × 18 × 64 = 2304 2\times 18 \times 64=2304 2×18×64=2304 | 297 KB |
| Maxpool3 | 0 | 1 × 9 × 64 = 576 1 \times 9 \times 64=576 1×9×64=576 | 2.3 KB |
| BN3 | 2 × 64 = 128 2\times 64=128 2×64=128 | 1 × 9 × 64 = 576 1 \times 9 \times 64=576 1×9×64=576 | 4.3 KB |
| Fatten | 0 | 576 576 576 | 2.25 KB |
| FCN | 576 × 128 = 73728 576\times 128=73728 576×128=73728 | $128 $ | 1152 KB |
| BN4 | 2 × 128 = 256 2 \times 128=256 2×128=256 | 128 128 128 | 4.5 KB |
| Output | 128 × 62 × 4 = 31744 128 \times 62 \times 4=31744 128×62×4=31744 | 4 × 62 = 248 4 \times 62 = 248 4×62=248 | 497.0 kB |
EasyNet
下图为EasyNet训练过程的模型损失曲线,从图中可以看出,模型在前10个epoch迅速收敛,在20 epoch之后,模型达到相对稳定状态。从图中可以看出,验证集损失相较于训练集损失,下降比较健康,并且手链曲线相对光滑,在后期也未出现验证集损失波动情况,说明其未发生严重过拟合,模型可以被认为训练过程可信。

从精度曲线中可以看出,在训练初期,验证集上的精度基本能优于训练集上的精度,这得益于正则化手段,使得模型的子模型也能具有较好的表现,在25个epoch直至更后期,验证集精度和训练集精度开始趋于重合,甚至验证集精度略低于训练集精度,并且精度不再明显上升。从精度曲线的光滑程度来看,同样证明模型在训练过程中未发生严重过拟合,因此模型可信度及有效性较高。
KCapNet
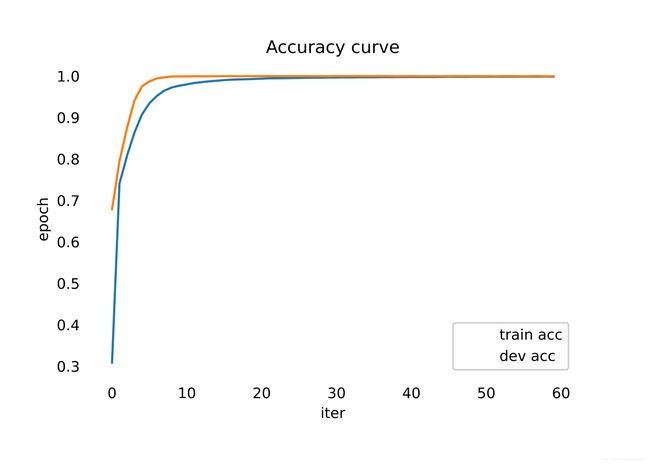
下图分别为KCapNet模型的损失曲线及精度曲线,从曲线中可以看出,在epoch为120时,曲线发生了剧烈波动,这是因为在训练过程中,调整了batch的缘故。通常,较大batch可以一定程度地加速模型收敛,使得梯度方向更加准确,更有利于模型收敛,但是batch过大会导致对于部分较低比例的hard sample影响被淡化,从而使得模型不具备hard sample的识别能力,制约了模型的拟合能力。因此在使用较大batch训练模型基本收敛后,调小batch以强化模型对于小部分样本的识别能力。根据损失曲线可以看出,模型收敛过程相对健康,在前25个epoch时,模型迅速收敛,并达到较好效果,随后训练集损失继续稳定下降,而训练集损失开始出现一定范围内的波动,但是未呈现明显的上升趋势,说明模型达到一定稳定程度的拟合能力。随着训练集损失的持续下降,验证集损失始终在1上下波动,无明显的损失整体下降趋势,因此在60 epoch之后,可以选择性早停,即Early stopping。
在120 epoch之后,即batch调笑之后,模型损失突然小幅度上升,随后继续下降,但验证集上损失较之前波动情况更加严重,这也一定程度地说明较大的batch相较于较小的batch,能够使模型损失更加光滑。
在该模型中,较小的batch取为256。

与损失曲线相反,在前25个epochs中,模型精度提升较快,并且能迅速达到0.9上下,随后训练集精度开始小幅度持续上升,而验证集精度开始出现波动,在70 epochs之后,验证集上的精度最好能达到 0.93 ∼ 0.94 0.93\sim 0.94 0.93∼0.94上下。在调小batch之后,验证集的精度波动更大,但最好精度与大batch之前相差较小,说明在较大batch下,模型收敛相对较好。
综合损失曲线与精度曲线,可知,在70 epoch之后,选择 70 ∼ 120 70 \sim 120 70∼120 epoch中损失最低的模型,可基本视为最佳模型。而在小batch之后,推荐选择 130 ∼ 170 130 \sim 170 130∼170 epoch间的最低损失模型可达到较好效果。
在本项目提供的预训练模型中,选择了第169个epoch的模型,其训练集精度可达0.94。

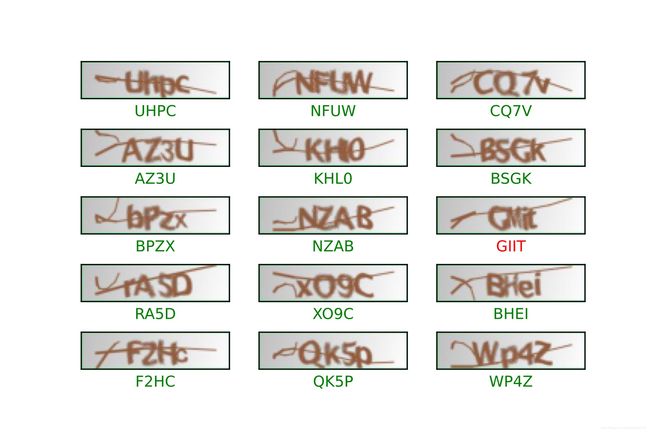
下图为从测试集随机选择的5组验证码样本,其中大部分均识别正确(标绿),小部分识别错误(标红)。从标红的案例中可以看出,该验证码认为识别正确难度仍然较高,因此识别错误也可以接受。同时,根据更广泛的测试集评估研究,模型对于0与O的识别准确度较低,甚至于O大部分被识别为0,这大程度上地受验证码由于字体形变而引发,根据人工对这些特殊案例的对比,部分能够被人眼正确地分辨,而少部分缺失存在人为无法准确分辨的案例。可以认为,认为地区分0与O,可能有 60 ∼ 70 % 60\sim 70\% 60∼70%成功率,这也同样对模型的准确度产生了干扰。
由于模型达到了基本可接受的识别准确度,因此再未将识别错误的样本单独挑出并训练,从理论上推测, 将分类错误的样本挑出重新分类,可以一定程度地提升模型效果,进行该操作的方法可有两种:
- 将识别错误的训练数据单独挑出,并重新构成训练集,并重新训练,该方式可能使得模型对这些样本过于拟合,因此训练的迭代次数需要控制;
- 将识别错误的样本标记,再下一轮训练时,在损失函数上,为上次识别失败的样本增大权重,使得分类错误的样本对模型的提升影响更大,降低正确识别样本对模型的影响,但是训练时仍提供正确样本,能够避免第一种方法的过拟合。(类似于Boosting)
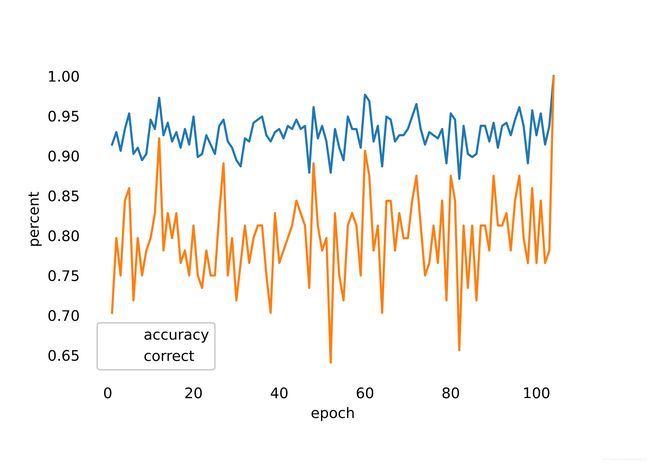
如下图,计算了模型在预测中的准确率,可见其波动较大,但是对于易于识别的数据,其准确率较高。
ACC指标与Correct指标不同,ACC计算了每个task的准确性,而correct计算了四个字符全部预测正确的比例。
上述模型的提升方法,有条件地可以进一步实验,以进一步提升模型性能。同时,对于验证码识别,还可以考虑使用注意力机制,针对不同的输出层关注不同的Feature Map,从直观上理解,应该能一定程度地提升模型的拟合能力,开发者们可以进一步尝试。
模型源代码及预训练模型已经开源至Github,欢迎访问。