零拷贝的前世今生
文章目录
- 1. 操作系統中的零拷贝
- 1.1 操作系统零拷贝的分类
- 1.2 避免内核空间和用户空间拷贝的实现
- 2. Java NIO中零拷贝
- 2.1 map
- 2.2 transferTo
- 2.3 DirectByteBuffer
- 3. Netty中零拷贝
- 3.1 CompositeByteBuf
- 3.2 wrap
- 3.3 slice
1. 操作系統中的零拷贝
摘自Wiki
Zero-copy" describes computer operations in which the CPU does not perform the task of copying data from one memory area to another. This is frequently used to save CPU cycles and memory bandwidth when transmitting a file over a network.
零复制(英语:Zero-copy;也译零拷贝)技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。
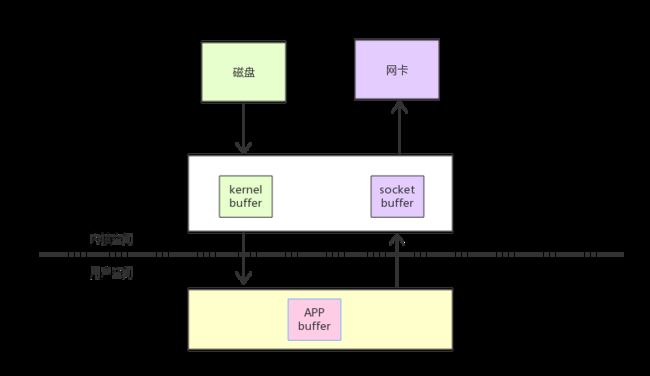
以网络文件传输过程举个例子:
- DMA read读取磁盘文件内容到内核缓冲区
- copy内核缓冲区数据到应用进程缓冲区
- 从应用进程缓冲区copy数据到socket缓冲区
- DMA copy给网卡发送
补充一个知识点:当然磁盘到内核空间属于DMA拷贝(DMA即直接内存存取,原理是外部设备不通过CPU而直接与系统内存交换数据)。而内核空间到用户空间则需要CPU的参与进行拷贝。
如下图:
1.1 操作系统零拷贝的分类
针对这种现状,Linux提供了三种零拷贝的手段优化此过程。
- 直接 I/O
对于这种数据传输方式来说,应用程序可以直接访问硬件存储,数据可以在应用程序地址空间的缓冲区和磁盘之间直接进行传输。
如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘加载,这种直接加载会非常缓存。通常直接IO与异步IO结合使用,会得到比较好的性能。推荐一篇不错的文章:
Linux 中直接 I/O 机制的介绍
-
避免数据在操作系统内核地址空间的缓冲区和用户应用程序地址空间的缓冲区之间进行拷贝。
应用程序在数据进行传输的过程中不需要对数据进行访问,那么,将数据从 Linux 的页缓存拷贝到用户进程的缓冲区中就可以完全避免,传输的数据在页缓存中就可以得到处理。在某些特殊的情况下,这种零拷贝技术可以获得较好的性能。
Linux 中提供类似的系统调用主要有 mmap(),sendfile() 以及 splice()。这种类型的零拷贝应用比较广泛。 -
对应用程序地址空间和内核空间的数据传输进行优化的零拷贝技术
对数据在linux页缓存和用户进程缓冲区之间的传输进行优化。该零拷贝技术侧重于灵活的处理数据在用户进程中的缓冲区和操作系统的页缓冲区之间的拷贝操作。
具有代表性的实现为写时复制:
写时复制是计算机编程中常见的一种优化策略,基本思想是这样的:如果多个应用程序需要同时访问一块数据,那么可以为这些应用程序分配指向这块数据的指针,在每个应用程序看来,他们都拥有这块数据的一份拷贝,当其中一个应用程序需要对自己的这份数据进行修改时,就需要将数据真正的拷贝到应用程序的地址空间去。如果应用程序永远不会对这块数据进行修改,那么就永远不需要将数据拷贝到应用程序的地址空间去。在stl中string的实现类似这种策略。
1.2 避免内核空间和用户空间拷贝的实现
前面讲到的三种零拷贝手段只有第二中是能通过Java平台才操作的,因此我们对这种方式的零拷贝做个阐述。
mmap
在 Linux 中,减少拷贝次数的一种方法是调用 mmap() 来代替调用 read,比如:
tmp_buf = mmap(file, len);
write(socket, tmp_buf, len);
应用程序调用了 mmap() 之后,数据会先通过 DMA 拷贝到操作系统内核的缓冲区中去。接着,应用程序跟操作系统共享这个缓冲区,这样,操作系统内核和应用程序存储空间就不需要再进行任何的数据拷贝操作。应用程序调用了 write() 之后,操作系统内核将数据从原来的内核缓冲区中拷贝到与 socket 相关的内核缓冲区中。接下来,数据从内核 socket 缓冲区拷贝到协议引擎中去,这是第三次数据拷贝操作。
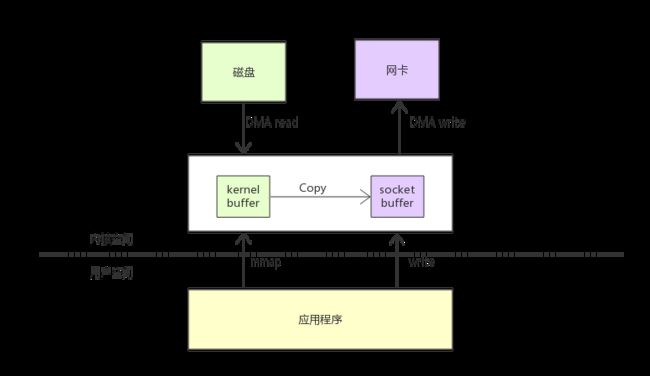
但是mmap有个缺点就是, 如果其他进程在向这个文件write, 那么会被认为是一个错误的存储访问。
sendfile
linux 在版本 2.1 中引入了 sendfile() 这个系统调用。sendfile() 不仅减少了数据拷贝操作,它也减少了上下文切换。首先:sendfile() 系统调用利用 DMA 引擎将文件中的数据拷贝到操作系统内核缓冲区中,然后数据被拷贝到与 socket 相关的内核缓冲区中去。接下来,DMA 引擎将数据从内核 socket 缓冲区中拷贝到协议引擎中去。
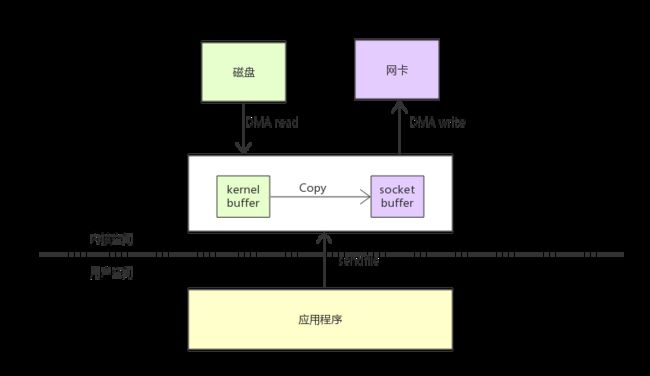
sendfile就好比mmap和write的结合。sendfile() 系统调用不需要将数据映射到应用程序地址空间中去,所以 sendfile() 只是适用于应用程序地址空间不需要对所访问数据进行处理的情况。
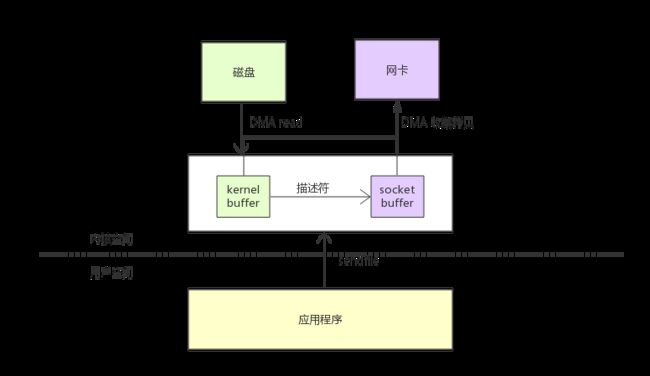
带有 DMA 收集拷贝功能的 sendfile()
为了避免操作系统内核造成的数据副本,待传输的数据可以分散在存储的不同位置上,而不需要在连续存储中存放。
这样一来,从文件中读出的数据就根本不需要被拷贝到 socket 缓冲区中去,而只是需要将缓冲区描述符传到网络协议栈中去,之后其在缓冲区中建立起数据包的相关结构,
然后通过 DMA 收集拷贝功能将所有的数据结合成一个网络数据包。网卡的 DMA 引擎会在一次操作中从多个位置读取包头和数据。
Linux 2.4 版本中的 socket 缓冲区就可以满足这种条件,这也就是用于 Linux 中的众所周知的零拷贝技术,
这种方法不但减少了因为多次上下文切换所带来开销,同时也减少了处理器造成的数据副本的个数。对于用户应用程序来说,代码没有任何改变。
首先,sendfile() 系统调用利用 DMA 引擎将文件内容拷贝到内核缓冲区去;然后,将带有文件位置和长度信息的缓冲区描述符添加到 socket 缓冲区中去,
此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,DMA 引擎会将数据直接从内核缓冲区拷贝到协议引擎中去,这样就避免了最后一次数据拷贝。
2. Java NIO中零拷贝
Java对零拷贝的应用主要在FileChannel.map()、transferTo()、和DirectByteBuffer中。下面逐一分析。
2.1 map
FileChannel.map()方法其实就是采用了操作系统中的内存映射方式(mmap),将内核缓冲区的内存和用户缓冲区的内存做了一个地址映射。
这种方式适合读取大文件,同时也能对文件内容进行更改,但是如果其后要通过SocketChannel发送,还是需要CPU进行数据的拷贝。
File file = new File("test.txt");
RandomAccessFile raf = new RandomAccessFile(file, "rw");
FileChannel fileChannel = raf.getChannel();
MappedByteBuffer buffer = fileChannel.map(FileChannel.MapMode.READ_ONLY, 0, fileChannel.size());
rocessData();
// 数据处理完成以后,打卡一个SocketChannel
SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("", 1024));
// 这时依旧需要CPU将内核缓冲区的内容拷贝到网络缓冲区
socketChannel.write(buffer);
2.2 transferTo
transferTo()方法将数据从FileChannel对象传送到可写的字节通道(如Socket Channel等)。
在内部实现中,由native方法transferTo0()来实现,它依赖底层操作系统的支持。在UNIX和Linux系统中,调用这个方法将会引起sendfile()系统调用。
SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("", 1234));
// 直接使用了transferTo()进行通道间的数据传输
fileChannel.transferTo(0, fileChannel.size(), socketChannel);
2.3 DirectByteBuffer
DirectByteBuffer即直接内存,和它对应的是HeapByteBuffer,前者为直接内存,因此不受Minor GC控制,只能在发生Full GC时才能被回收。
DirectByteBuffer 是 MappedByteBuffer的实现类,换句话说在我们在JVM中持有的DirectByteBuffer对象可以指向的是数据通过mmap映射到共享内存中。
关于直接内存相比堆内存会减少一次拷贝,在Netty中的Buffer都是直接内存。
3. Netty中零拷贝
Netty的零拷贝体现在三个方面:
- Netty的接收和发送ByteBuffer采用DIRECT BUFFERS,使用堆外直接内存进行Socket读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的堆内存(HEAP BUFFERS)进行Socket读写,JVM会将堆内存Buffer拷贝一份到直接内存中,然后才写入Socket中。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。
- Netty的文件传输采用了transferTo方法,它可以直接将文件缓冲区的数据发送到目标Channel,避免了传统通过循环write方式导致的内存拷贝问题,在Netty中的体现是FileRegion类。
- Netty提供了组合Buffer对象,可以聚合多个ByteBuffer对象,用户可以像操作一个Buffer那样方便的对组合Buffer进行操作,避免了传统通过内存拷贝的方式将几个小Buffer合并成一个大的Buffer。
前两种方式和Java NIO 几乎一样,第三种是Netty独有的,组合Buffer有可以分为以下几类:
-
Netty 提供了 CompositeByteBuf 类, 它可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf, 避免了各个 ByteBuf 之间的拷贝.
-
通过 wrap 操作, 我们可以将 byte[] 数组、ByteBuf、ByteBuffer等包装成一个 Netty ByteBuf 对象, 进而避免了拷贝操作.
-
ByteBuf 支持 slice 操作, 因此可以将 ByteBuf 分解为多个共享同一个存储区域的 ByteBuf, 避免了内存的拷贝.
3.1 CompositeByteBuf
传统的ByteBuffer,如果需要将两个ByteBuffer中的数据组合到一起,我们需要首先创建一个size=size1+size2大小的新的数组,然后将两个数组中的数据拷贝到新的数组中。但是使用Netty提供的组合ByteBuf,就可以避免这样的操作,因为CompositeByteBuf并没有真正将多个Buffer组合起来,而是保存了它们的引用,从而避免了数据的拷贝,
ByteBuf buf1 = Unpooled.buffer(5);
ByteBuf buf2 = Unpooled.buffer(10);
CompositeByteBuf buf = Unpooled.compositeBuffer();
buf.addComponents(true,buf1, buf2);
addComponents(boolean increaseWriterIndex, ByteBuf… buffers) 来添加两个 ByteBuf, 其中第一个参数是 true, 表示当添加新的 ByteBuf 时, 自动递增 CompositeByteBuf 的 writeIndex.
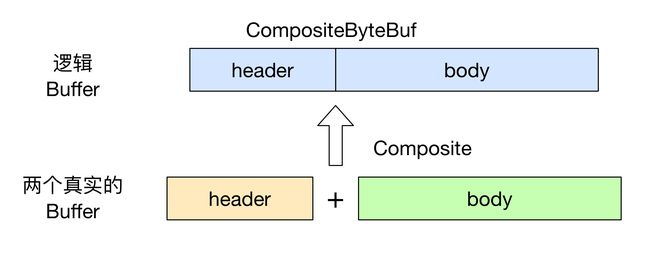
看起来 CompositeByteBuf 是由两个 ByteBuf 组合而成的, 不过在 CompositeByteBuf 内部, 这两个 ByteBuf 都是单独存在的, CompositeByteBuf 只是逻辑上是一个整体.
3.2 wrap
Unpooled.wrappedBuffer 方法来将 bytes、ByteBuffer等 包装成为一个 UnpooledHeapByteBuf 对象, 而在包装的过程中, 是不会有拷贝操作的。
以byte[]数组为例。生成的 ByteBuf 对象是和 byte[]数组共用了同一个存储空间, 对 bytes 的修改也会反映到 ByteBuf 对象中.
byte[] bytes = ...
ByteBuf byteBuf = Unpooled.wrappedBuffer(bytes);
重载的方法有:
public static ByteBuf wrappedBuffer(byte[] array)
public static ByteBuf wrappedBuffer(byte[] array, int offset, int length)
public static ByteBuf wrappedBuffer(ByteBuffer buffer)
public static ByteBuf wrappedBuffer(ByteBuf buffer)
public static ByteBuf wrappedBuffer(byte[]... arrays)
public static ByteBuf wrappedBuffer(ByteBuf... buffers)
public static ByteBuf wrappedBuffer(ByteBuffer... buffers)
public static ByteBuf wrappedBuffer(int maxNumComponents, byte[]... arrays)
public static ByteBuf wrappedBuffer(int maxNumComponents, ByteBuf... buffers)
public static ByteBuf wrappedBuffer(int maxNumComponents, ByteBuffer... buffers)
3.3 slice
slice 操作和 wrap 操作刚好相反, Unpooled.wrappedBuffer 可以将多个 ByteBuf 合并为一个, 而 slice 操作可以将一个 ByteBuf 切片 为多个共享一个存储区域的 ByteBuf 对象.
public ByteBuf slice();
public ByteBuf slice(int index, int length);
不带参数的 slice 方法等同于 buf.slice(buf.readerIndex(), buf.readableBytes()) 调用, 即返回 buf 中可读部分的切片. 而 slice(int index, int length) 方法相对就比较灵活了, 我们可以设置不同的参数来获取到 buf 的不同区域的切片.
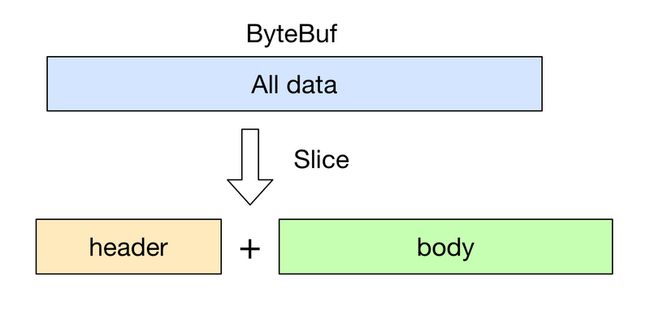
ByteBuf byteBuf = ...
ByteBuf header = byteBuf.slice(0, 5);
ByteBuf body = byteBuf.slice(5, 10);
用 slice 方法产生 header 和 body 的过程是没有拷贝操作的, header 和 body 对象在内部其实是共享了 byteBuf 存储空间的不同部分而已. 即:
写在最后,本文从操作系统的零拷贝开始说起,介绍了操作系统级别的零拷贝,然后讲到NIO中的零拷贝,需要系统的支持,而在Netty中的零拷贝一部分是需要前两者的支持,一部分是自身对ByteBuf的优化。