Redis集群命令解析与应用
Redis集群
- 1. Redis集群介绍
- 2. Redis 集群的数据分片
- 3. Redis 集群的主从复制模型
- 4. Redis 一致性保证
- 5. 搭建并使用Redis集群
- 配置文件
- 配置集群
- docker启动
- 集群客户端
- 创建集群
- 使用
- 6. 集群命令 -- cluster
- info
- nodes
- replocas
- slaves
- slots
- count-failure-reports
- countkeysinslot
- getkeysinslot
- keyslot
- failover
- delslots
- addslots
- saveconfig
- reset
- set-config-epoch
- meet
- setSlot
- migrating
- importing
- stable
- node
- replicate
- forget
- 7. 集群命令--redis-cli
- create
- info
- check
- fix
- reshard
- rebalance
- del-node
- add-node
- import
1. Redis集群介绍
Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。
Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误.
Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令. Redis 集群的优势:
- 自动分割数据到不同的节点上。
- 整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
2. Redis 集群的数据分片
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
- 节点 A 包含 0 到 5500号哈希槽.
- 节点 B 包含5501 到 11000 号哈希槽.
- 节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
3. Redis 集群的主从复制模型
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品.
在我们例子中具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用.
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了
不过当B和B1 都失败后,集群是不可用的.
4. Redis 一致性保证
Redis 并不能保证数据的强一致性. 这意味这在实际中集群在特定的条件下可能会丢失写操作.
第一个原因是因为集群是用了异步复制. 写操作过程:
- 客户端向主节点B写入一条命令.
- 主节点B向客户端回复命令状态.
- 主节点将写操作复制给他得从节点 B1, B2 和 B3.
主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。 注意:Redis 集群可能会在将来提供同步写的方法。 Redis 集群另外一种可能会丢失命令的情况是集群出现了网络分区, 并且一个客户端与至少包括一个主节点在内的少数实例被孤立。
举个例子 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点, 其中 A 、B 、C 为主节点, A1 、B1 、C1 为A,B,C的从节点, 还有一个客户端 Z1 假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点 A 、C 、A1 、B1 和 C1 ,小部分的一方则包含节点 B 和客户端 Z1 .
Z1仍然能够向主节点B中写入, 如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了.
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项.
5. 搭建并使用Redis集群
搭建集群的第一件事情我们需要一些运行在 集群模式的Redis实例. 这意味这集群并不是由一些普通的Redis实例组成的,集群模式需要通过配置启用,开启集群模式后的Redis实例便可以使用集群特有的命令和特性了.
配置文件
下面是一个最少选项的集群的配置文件:
port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
文件中的 cluster-enabled 选项用于开实例的集群模式, 而 cluster-conf-file 选项则设定了保存节点配置文件的路径, 默认值为 nodes.conf.节点配置文件无须人为修改, 它由 Redis 集群在启动时创建, 并在有需要时自动进行更新。
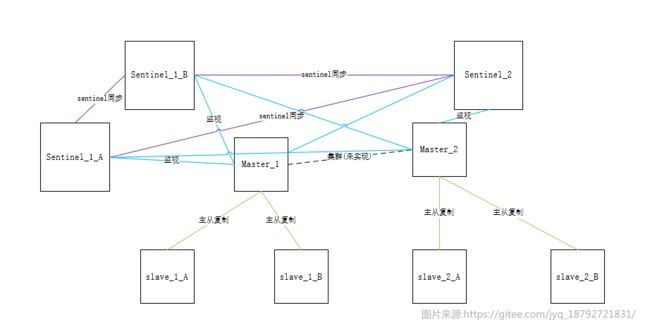
在之前的redis的哨兵模式中,没有实现集群,今天,在哨兵模式的基础上继续。
首先,从redis的github上下载代码,主要是获取redis.conf
然后上传到服务器中:

然后拷贝两份配置文件(防止redis,conf被污染),并给与权限

配置集群
接下来,修改配置文件

开启集群模式

指定配置文件

集群节点超时时间

这里有一个比较坑的地方,cluster-config-file这里不配置,因为我们使用docker启动,在启动的时候会指定配置文件的,否则会抛出异常:Unrecoverable error: corrupted cluster config file.
docker启动
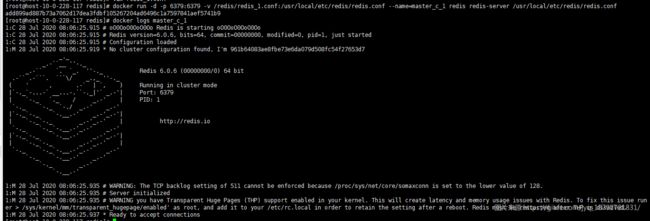
接着,使用docker启动
docker run -d -p 6379:6379 -v /redis/redis_1.conf:/usr/local/etc/redis/redis.conf --name=master_c_1 redis redis-server /usr/local/etc/redis/redis.conf
![]()
接下来创建从节点
![]()
集群客户端
在redis 5.x之后,就不推荐使用redis-trib.rb了,而是使用redis-cli --cluster的命令。

但是redis高版本,可以使用create-cluster脚本
查看其REDAME:

将脚本放到服务器中(这个脚本是个linux的脚本)

创建集群
![]()
因为目录结构已经不正确了,所以,我们研究下这个脚本里面都干了什么吧
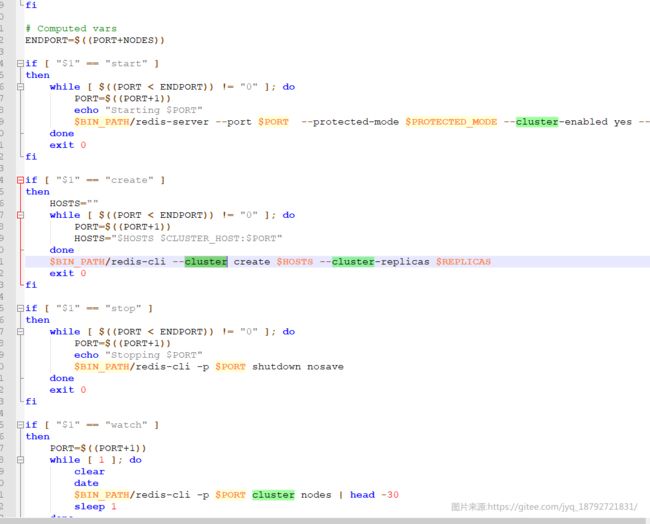
和我们之前在docker那里的命令一模一样。
创建集群使用docker容器里面的redis-cli。
docker run -it --rm redis redis-cli --cluster create 10.0.228.117:6379 10.0.228.117:6380 10.0.228.117:6381 10.0.228.117:6382 --cluster-replicas 1

提示6379,也就是master_c_1不是集群模式启动的?
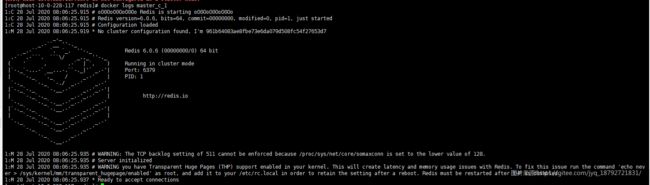
明明是集群模式启动的啊。
想想,应该是配置不对吧。
应该是ip绑定了,不应该绑定ip.

果真如此,不仅仅绑定了IP,还使用了保护模式。。。。。太粗心了。绑定0.0.0.0表示任何IP都可以访问
重启,重试。
![]()
![]()
至少需要6台机器,我擦
(因为redis集群使用流言协议进行交换数据,流言协议的裁定需要使用过半原则。所以最少是3台master(1个无法实现流言协议,2个无法实现过半原则),指定1个副本,就是至少6台机器)
在增加一个主节点和一个从节点吧。

重新创建集群
![]()
又没成功,从输出来看,应该是容器内无法解析IP,那么只能在启动的时候制动hostname了
我真是太能折腾了。。
docker ps|grep redis|awk '{print $1}'|xargs docker rm
docker run -d --rm --network=host -v /redis/redis_1.conf:/usr/local/etc/redis/redis.conf --hostname=master_c_1 --name=master_c_1 redis redis-server /usr/local/etc/redis/redis.conf --port 6379
docker run -d --rm --network=host -v /redis/redis_2.conf:/usr/local/etc/redis/redis.conf --hostname=master_c_2 --name=master_c_2 redis redis-server /usr/local/etc/redis/redis.conf --port 6380
docker run -d --rm --network=host -v /redis/redis_3.conf:/usr/local/etc/redis/redis.conf --hostname=master_c_3 --name=master_c_3 redis redis-server /usr/local/etc/redis/redis.conf --port 6381
docker run -d --rm --network=host -v /redis/slave_1.conf:/usr/local/etc/redis/redis.conf --hostname=slave_1 --name=slave_1 redis redis-server /usr/local/etc/redis/redis.conf --port 6382
docker run -d --rm --network=host -v /redis/slave_2.conf:/usr/local/etc/redis/redis.conf --hostname=slave_2 --name=slave_2 redis redis-server /usr/local/etc/redis/redis.conf --port 6383
docker run -d --rm --network=host -v /redis/slave_3.conf:/usr/local/etc/redis/redis.conf --hostname=slave_3 --name=slave_3 redis redis-server /usr/local/etc/redis/redis.conf --port 6384

然后创建集群

终于成功了(都快哭了)
这里必须使用docker的host网络模式,因为redis集群不支持docker的port mapping.

使用这个命令看看吧

使用
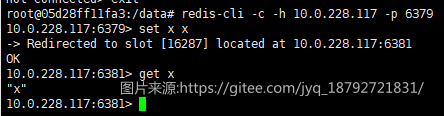
尝试插入不同的数据:
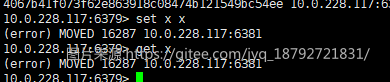
出现(error) MOVED xxxxxx
原因:redis-cli需要以集群模式启动
6. 集群命令 – cluster

info
查看集群信息
cluster info

cluster_state:ok状态表示集群可以正常接受查询请求。fail状态表示,至少有一个哈希槽没有被绑定(说明有哈希槽没有被绑定到任意一个节点),或者在错误的状态(节点可以提供服务但是带有FAIL 标记),或者该节点无法联系到多数master节点。.cluster_slots_assigned: 已分配到集群节点的哈希槽数量(不是没有被绑定的数量)。16384个哈希槽全部被分配到集群节点是集群正常运行的必要条件.cluster_slots_ok: 哈希槽状态不是FAIL和PFAIL的数量.cluster_slots_pfail: 哈希槽状态是PFAIL的数量。只要哈希槽状态没有被升级到FAIL状态,这些哈希槽仍然可以被正常处理。PFAIL状态表示我们当前不能和节点进行交互,但这种状态只是临时的错误状态。cluster_slots_fail: 哈希槽状态是FAIL的数量。如果值不是0,那么集群节点将无法提供查询服务,除非cluster-require-full-coverage被设置为no.cluster_known_nodes: 集群中节点数量,包括处于握手状态还没有成为集群正式成员的节点.cluster_size: 至少包含一个哈希槽且能够提供服务的master节点数量.cluster_current_epoch: 集群本地Current Epoch变量的值。这个值在节点故障转移过程时有用,它总是递增和唯一的。cluster_my_epoch: 当前正在使用的节点的Config Epoch值. 这个是关联在本节点的版本值.cluster_stats_messages_sent: 通过node-to-node二进制总线发送的消息数量.cluster_stats_messages_received: 通过node-to-node二进制总线接收的消息数量.
nodes
查看节点信息
cluster nodes

每行组成:
每项的含义如下:
-
id: 节点ID,是一个40字节的随机字符串,这个值在节点启动的时候创建,并且永远不会改变(除非使用CLUSTER RESET HARD命令)。 -
ip:port: 客户端与节点通信使用的地址. -
flags: 逗号分割的标记位,可能的值有:myself,master,slave,fail?,fail,handshake,noaddr,noflags:各flags的含义 (上面所说数据项3):
myself: 当前连接的节点.master: 节点是master.slave: 节点是slave.fail?: 节点处于PFAIL状态。 当前节点无法联系,但逻辑上是可达的 (非FAIL状态).fail: 节点处于FAIL状态. 大部分节点都无法与其取得联系将会将改节点由PFAIL状态升级至FAIL状态。handshake: 还未取得信任的节点,当前正在与其进行握手.noaddr: 没有地址的节点(No address known for this node).noflags: 连个标记都没有(No flags at all).
-
master: 如果节点是slave,并且已知master节点,则这里列出master节点ID,否则的话这里列出”-“。 -
ping-sent: 最近一次发送ping的时间,这个时间是一个unix毫秒时间戳,0代表没有发送过. -
pong-recv: 最近一次收到pong的时间,使用uni`x时间戳表示. -
config-epoch: 节点的epoch值(or of the current master if the node is a slave)。每当节点发生失败切换时,都会创建一个新的,独特的,递增的epoch。如果多个节点竞争同一个哈希槽时,epoch值更高的节点会抢夺到。 -
link-state: node-to-node集群总线使用的链接的状态,我们使用这个链接与集群中其他节点进行通信.值可以是connected和disconnected. -
slot: 哈希槽值或者一个哈希槽范围. 从第9个参数开始,后面最多可能有16384个 数(limit never reached)。代表当前节点可以提供服务的所有哈希槽值。如果只是一个值,那就是只有一个槽会被使用。如果是一个范围,这个值表示为起始槽-结束槽,节点将处理包括起始槽和结束槽在内的所有哈希槽。
replocas
cluster replicas
该命令会列出指定主节点的辅助副本节点,输出格式同命令CLUSTER NODES.
若特定节点状态未知,或在接收命令节点的节点信息表中,该节点不是主节点,则命令失败.

slaves
cluster slaves
该命令会列出指定master节点所有slave节点,格式同CLUSTER NODES
当指定节点未知或者根据接收命令的节点的节点信息表指定节点不是主节点,命令执行错误。

slots
cluster slots
CLUSTER SLOTS命令返回哈希槽和Redis实例映射关系。这个命令对客户端实现集群功能非常有用,使用这个命令可以获得哈希槽与节点(由IP和端口组成)的映射关系,这样,当客户端收到(用户的)调用命令时,可以根据(这个命令)返回的信息将命令发送到正确的Redis实例.
(嵌套对象)结果数组每一个(节点)信息:
- 哈希槽起始编号
- 哈希槽结束编号
- 哈希槽对应master节点,节点使用IP/Port表示
- master节点的第一个副本
每个结果包含该哈希槽范围的所有存活的副本,没有存活的副本不会返回.
(每个节点信息的)第三个(行)对象一定是IP/Port形式的master节点。之后的所有IP/Port都是该哈希槽范围的Redis副本。
如果一个集群实例中的哈希槽不是连续的(例如1-400,900,1800-6000),那么哈希槽对应的master和replica副本在这些不同的哈希槽范围会出现多次。

count-failure-reports
cluster count-filure-reports
这个命令返回指定节点的故障报告个数,故障报告是Redis Cluster用来使节点的PFAIL状态(这意味着节点不可达)晋升到FAIL状态而的方式,这意味着集群中大多数的主节点在一个事件窗口内同意节点不可达。
因为redis使用流言模式,所以需要记录报告的异常次数。
- 一个节点会用
PFAIL标记一个不可达时间超过配置中的超时时间的节点,这个超时时间是 Redis Cluster 配置中的基本选项。 - 处于
PFAIL状态的节点会将状态信息提供在心跳包的流言(gossip)部分。 - 每当一个节点处理来自其他节点的流言(gossip)包时,该节点会建立故障报告(如果需要会刷新TTL),并且会记住发送消息包的节点所认为处于
PFAIL状态下的其他节点。 - 每个故障报告的生存时间是节点超时时间的两倍。
- 如果在一段给定的事件内,一个节点被另一个节点标记为
PFAIL状态,并且在相同的时间内收到了其他大多数主节点关于该节点的故障报告(如果该节点是主节点包括它自己),那么该节点的故障状态会从PFAIL晋升为FAIL,并且会广播一个消息,强制所有可达的节点将该节点标记为FAIL。

countkeysinslot
cluster countkeysinslot slot
count keys in sloot
查询指定slot中key的数量

这个命令和keyslot配合使用。
如果指定的hash slot不在客户端连接的节点上,返回0.
getkeysinslot
获取指定hash slot中全部的key.
cluster getkeysinslot slot count
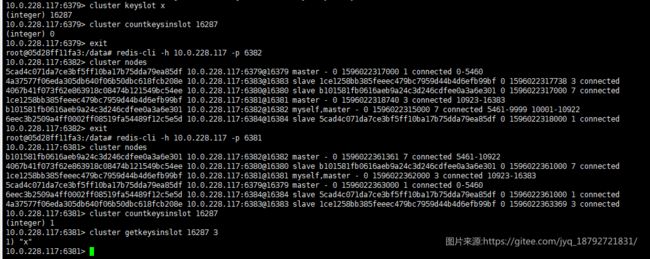
keyslot
cluster keyslot key
查询指定key的hash slot
可以和countkeysinslot配合使用。
failover
cluster failover [Force|Takeover]
该命令只能在群集slave节点执行,让slave节点进行一次人工故障切换。
人工故障切换是预期的操作,而非发生了真正的故障,目的是以一种安全的方式(数据无丢失)将当前master节点和其中一个slave节点(执行cluster-failover的节点)交换角色。
流程如下:
- 当前slave节点告知其master节点停止处理来自客户端的请求
- master 节点将当前replication offset 回复给该slave节点
- 该slave节点在未应用至replication offset之前不做任何操作,以保证master传来的数据均被处理。
- 该slave 节点进行故障转移,从群集中大多数的master节点获取epoch,然后广播自己的最新配置
- 原master节点收到配置更新:解除客户端的访问阻塞,回复重定向信息,以便客户端可以和新master通信。
当该slave节点(将切换为新master节点)处理完来自master的所有复制,客户端的访问将会自动由原master节点切换至新master节点.
-
FORCE 选项:slave节点不和master协商(master也许已不可达),从上如4步开始进行故障切换。当master已不可用,而我们想要做人工故障转移时,该选项很有用。
但是,即使使用FORCE选项,我们依然需要群集中大多数master节点有效,以便对这次切换进行验证,同时为将成为新master的salve节点生成新的配置epoch。
-
TAKEOVER 选项: 忽略群集一致验证的的人工故障切换
有时会有这种情况,群集中master节点不够,我们想在未和群集中其余master节点验证的情况下进行故障切换。 实际用途举例:群集中主节点和从节点在不同的数据中心,当所有主节点down掉或被网络分区隔离,需要用该参数将slave节点 批量切换为master节点。
选项 TAKEOVER 实现了FORCE的所有功能,同时为了能够进行故障切换放弃群集验证。当slave节点收到命令CLUSTER FAILOVER TAKEOVER会做如下操作:
- 独自生成新的
configEpoch,若本地配置epoch非最大的,则取当前有效epoch值中的最大值并自增作为新的配置epoch - 将原master节点管理的所有哈希槽分配给自己,同时尽快分发最新的配置给所有当前可达节点,以及后续恢复的故障节点,期望最终配置分发至所有节点
注意:TAKEOVER 违反Redis群集最新-故障转移-有效 原则,因为slave节点产生的配置epoch 会让正常产生的的配置epoch无效
- 使用TAKEOVER 产生的配置epoch 无法保证时最大值,因为我们是在少数节点见生成epoch,并且没有使用信息交互来保证新生成的epoch值最大。
- 如果新生成的配置epoch 恰巧和其他实例生成的发生冲突(epoch相同),最终我们生成的配置epoch或者其他实例生成的epoch,会通过使用配置epoch冲突解决算法 舍弃掉其中一个。
因为这个原因,选择TAKEOVER需小心使用.

delslots
cluster delslots
在Redis Cluster中,每个节点都会知道哪些主节点正在负责哪些特定的哈希槽
DELSLOTS命令使一个特定的Redis Cluster节点去忘记一个主节点正在负责的哈希槽,这些哈希槽通过参数指定。
说白了就是使指定的hash slot从集群中解绑
在已经接收到DELSLOTS命令的节点环境中,并且因此已经去除了指定哈希槽的关联,我们认为这些哈希槽是未绑定的 。请注意,当一个节点还没有被配置去负责他们(可以通过ADDSLOTS完成槽的分配)并且如果该节点没有收到关于谁拥有这些哈希槽的消息时(节点通过心跳包或者更新包获取消息),这些未绑定的哈希槽是自然而然本来就存在的。
如果一个节点认为一些哈希槽是未绑定的,但是从其他节点接收到一个心跳包,得知这些哈希槽已经被其他节点负责,那么会立即确立其关联关系。而且,如果接收到一个心跳包或更新包的配置纪元比当前节点的大,那么会重新建立关联。
- 命令只在参数指定的哈希槽已经和某些节点关联时有效。
- 如果同一个哈希槽被指定多次,该命令会失败。
- 命令执行的副作用是,因为不在负责哈希槽,节点可能会进入下线状态。

10000这个hash slot已经从集群中解绑了.
请注意,如果解绑的hash slot在一定时间内没有被重新分配,那么会因集群间心跳包传输,当前节点重新获得移除的hash slot.
此命令和addslots配合使用,实现人工分配hash slot.
addslots
cluster addslots
指定命令接收节点,分配指定的slot集合
这个命令是用于修改某个节点上的集群配置。具体的说它把一组hash slots分配给接收命令的节点。 如果命令执行成功,节点将指定的hash slots映射到自身,节点将获得指定的hash slots,同时开始向集群广播新的配置。
需要注意:
- 该命令只有当所有指定的slots在接收命令的节点上还没有分配得的情况下生效。节点将 拒绝接纳已经分配到其他节点的slots(包括它自己的)。
- 同一个slot被指定多次的情况下命令会失败。
- 执行这个命令有一个副作用,如果slot作为其中一个参数设置为
importing,一旦节点向自己分配该slot(以前未绑定)这个状态将会被清除。
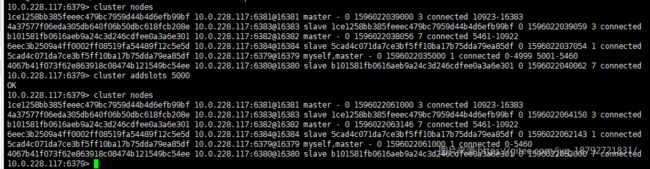
saveconfig
cluster saveconfig
强制保存配置nodes.conf至磁盘。
该命令主要用于nodes.conf节点状态文件丢失或被删除的情况下重新生成文件。当使用CLUSTER命令 对群集做日常维护时,该命令可以用于保证新生成的配置信息会被持久化到磁盘。当然,这类命令应该设置定时调用 将配置信息持久化到磁盘,保证系统重启之后状态信息还是正确的。

reset
cluster reset [HARD|SOFT]
根据reset的类型配置hard或者soft ,Reset 一个Redis群集节点可以选择十分极端或极端的方式。 注意该命令在主节点hold住一个或多个keys的时候无效,在这种情况下,如果要彻底reset一个master, 需要将它的所有key先移除,如先使用FLUSHALL,在使用CLUSTER RESET节点上的效果如下:
- 群集中的节点都被忽略
- 所有已分派/打开的槽会被reset,以便slots-to-nodes对应关系被完全清除
- 如果节点是slave,它会被切换为(空)master。它的数据集已被清空,因此最后也会变成一个空master。
- Hard reset only:生成新的节点ID
- 变量
currentEpoch和configEpoch被设置为0 - 新配置被持久化到节点磁盘上的群集配置信息文件中
当需要为一个新的或不同的群集提供一个新的群集节点是可使用该命令,同时它也在Redis群集测试框架中被广泛使用,它用于 在每个新的测试单元启动是初始化群集状态。
如果reset类型没有指定,使用默认值soft
hard:
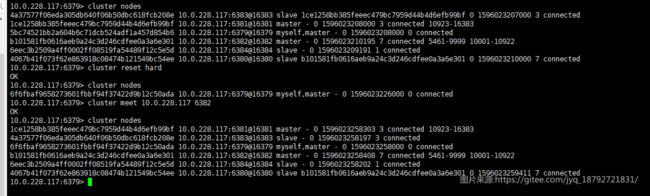
soft

没看出这两个有什么区别。
reset会清楚master中的数据:

因为reset改变了id,所以,在其他redis节点中,原有的两个被标识为未知的了。(流言开始)
如果过一段时间,流言得到确认,就会移除未知节点。
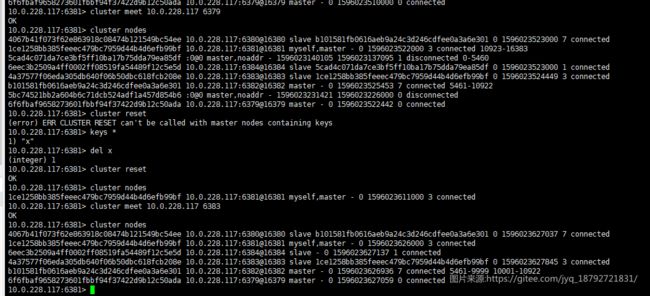
set-config-epoch
cluster set-config-epoch
该命令为一个全新的节点设置指定的config epoch,仅在如下情况下有效:
- 节点的节点信息表为空
- 节点的当前config epoch为0
这些先决条件是需要的,因为通常情况下,人工修改一个节点的配置epoch是不安全的,我们想保证一点:在 获取哈希槽的所有权时,拥有更高配置epoch值的节点获胜。
但是该规则也有一个例外,在群集创建的时候,Redis群集配置epoch冲突解决算法会解决 群集启动时新的节点配置成相同配置epoch的问题,但是这个处理过程很慢,为了保证不管发生任何情况,都不会有两个节点拥有相同的配置epoch。
因此,当一个新群集创建的时候,使用命令CONFIG SET-CONFIG-EPOCH为每个一个节点分派渐进的配置epoch,然后再加入群集。
meet
cluster meet
CLUSTER MEET命令被用来连接不同的开启集群支持的 Redis 节点,以进入工作集群。
基本的思想是每个节点默认都是相互不信任的,并且被认为是未知的节点,以便万一因为系统管理错误或地址被修改,而不太可能将多个不同的集群节点混成一个集群。
请注意,Redis Cluster 需要形成一个完整的网络(每个节点都连接着其他每个节点),但是为了创建一个集群,不需要发送形成网络所需的所有CLUSTER MEET命令。发送CLUSTER MEET消息以便每个节点能够到达其他每个节点只需通过一条已知的节点链就足够了。由于在心跳包中会交换 gossip 信息,将会创建节点间缺失的链接。
所以,如果我们通过CLUSTER MEET链接节点 A 和节点 B ,并且节点 B 和 C 有链接,那么节点 A 和节点 C 会发现他们握手和创建链接的方法。
实现细节:MEET 和 PING 包**
当一个给定的节点接收到一个CLUSTER MEET消息时,命令中指定的节点仍然不知道我们发送了命令,所以为了使节点强制将接收命令的节点将它作为信任的节点接受它,它会发送MEET包而不是PING包。两个消息包有相同的格式,但是MEET强制使接收消息包的节点确认发送消息包的节点为可信任的。

我们新增一个redis实例,然后用meet加入集群:

然后加入

setSlot
-
MIGRATING子命令:将一个哈希槽设置为migrating 状态(导出) -
IMPORTING子命令:将一个哈希槽设置为importing 状态(倒入) -
STABLE子命令:从哈希槽中清除导入和迁移状态 -
NODE子命令:将一个哈希槽绑定到另一个不同的节点
migrating
cluster setslot
该子命令将一个槽设置为migrating状态.为了可以将一个哈希槽设置成这种状态,收到命令的节点必须是该哈希槽的所有者,否则报错

importing
cluster setslot
该子命令是MIGRATING的反向操作,将keys从指定源节点导入目标节点。该命令仅能在目标节点不是指定槽的所有者时生效。

stable
cluster setslot
该子命令仅用于清理槽中迁移中/导入中的状态。它主要用于修复群集在使用·redis-trip fix· 卡在一个错误状态的问题。

node
cluster setslot
子命令NODE使用方法最复杂,它后接指定节点的哈希槽,该命令仅在特定情况下有效,并且不同的槽状态会有不同的效果.
如果slot是migrating,那么该操作是将命令接收者的slot分配出去

如果slot是importing,那么该操作是将其他slot分配给命令接受者

replicate
cluster replcate
该命令重新配置一个节点成为指定master的salve节点。 如果收到命令的节点是一个empty master,那么该节点的角色将由master切换为slave。
一旦一个节点变成另一个master节点的slave,无需通知群集内其他节点这一变化:节点间交换 信息的心跳包会自动将新的配置信息分发至所有节点。
我们在新增一个节点:

此时6386是master,我们要让6386成为6385的slave
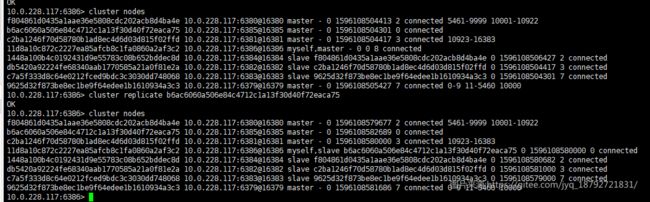
得益于redis集群的通信,其他节点也得到了相同的信息

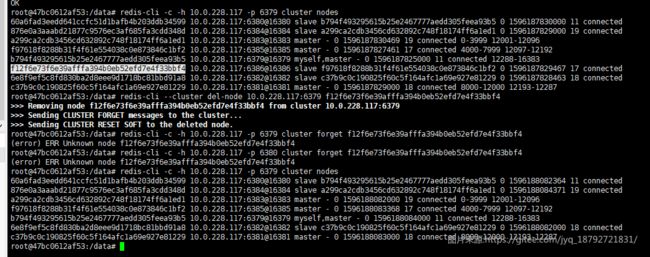
forget
cluster forget
该命令可以从收到命令的Redis群集节点的节点信息列表中移除指定ID的节点。 换句话说,从收到命令的Redis群集节点的nodes table中删除指定节点。
该命令不是将待删除节点的信息简单从内部配置中简单删除,它同时实现了禁止列表功能:不允许已删除 的节点再次被添加进来,否则已删除节点会因为处理其他节点心跳包中的gossip section时被再次添加。
命令CLUSTER FORGET为每个节点实现了包含超时时间的禁止列表
因此我们命令实际的执行情况如下:
- 从收到命令节点的节点信息列表中删除待删除节点的节点信息。
- 已删除的节点的节点ID被加入禁止列表,保留1分钟
- 收到命令的节点,在处理从其他节点发送过来的gossip sections 会跳过所有在禁止列表中的节点。
这样,我们就有60秒的时间窗口来通知群集中的所有节点,我们想要删除某个节点。
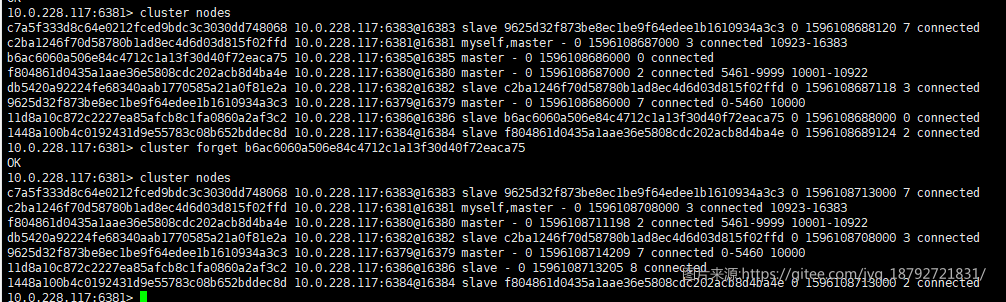
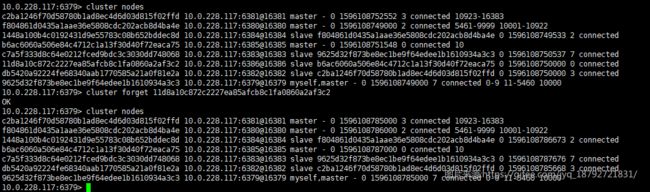

7. 集群命令–redis-cli

create
redis-cli --cluster create
创建集群
见第5小节。。
info
redis-cli --cluster info <集群内任一ip:port>
获取集群信息

check
redis-cli --cluster check <集群内任一ip:port>
检查集群
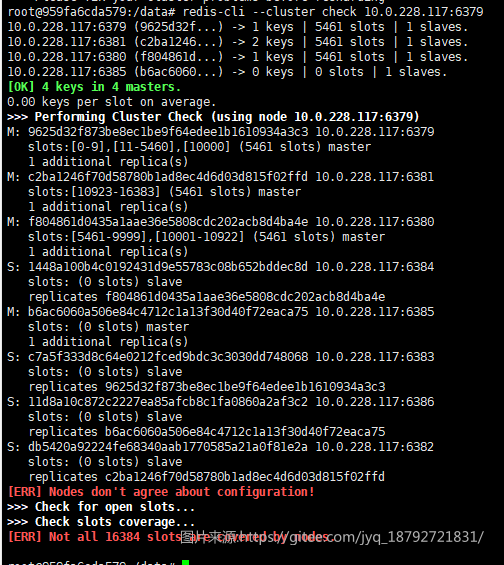
报错提示我们的集群内每一个节点的配置文件不同。
还记得我们启动的命令吗:
docker run -d --rm --network=host -v /redis/redis_cluster.conf:/usr/local/etc/redis/redis.conf --hostname=master_c_4 --name=master_c_4 redis redis-server /usr/local/etc/redis/redis.conf --port 6385
我们传入了一个配置文件,但是我们在配置文件中指定的配置文件是nodes.conf

我们将这个配置定为同样的配置:

创建每个节点的nodes.conf的目录
![]()
然后重新创建全部的集群节点:
docker ps|grep redis|awk '{print $1}'|xargs docker stop
docker run -d --rm --network=host -v /redis/master_c_1/:/redis/cluster/ -v /redis/redis_cluster.conf:/usr/local/etc/redis/redis.conf --hostname=master_c_1 --name=master_c_1 redis redis-server /usr/local/etc/redis/redis.conf --port 6379
docker run -d --rm --network=host -v /redis/master_c_2/:/redis/cluster/ -v /redis/redis_cluster.conf:/usr/local/etc/redis/redis.conf --hostname=master_c_2 --name=master_c_2 redis redis-server /usr/local/etc/redis/redis.conf --port 6380
docker run -d --rm --network=host -v /redis/master_c_3/:/redis/cluster/ -v /redis/redis_cluster.conf:/usr/local/etc/redis/redis.conf --hostname=master_c_3 --name=master_c_3 redis redis-server /usr/local/etc/redis/redis.conf --port 6381
docker run -d --rm --network=host -v /redis/slave_1/:/redis/cluster/ -v /redis/redis_cluster.conf:/usr/local/etc/redis/redis.conf --hostname=slave_1 --name=slave_1 redis redis-server /usr/local/etc/redis/redis.conf --port 6382
docker run -d --rm --network=host -v /redis/slave_2/:/redis/cluster/ -v /redis/redis_cluster.conf:/usr/local/etc/redis/redis.conf --hostname=slave_2 --name=slave_2 redis redis-server /usr/local/etc/redis/redis.conf --port 6383
docker run -d --rm --network=host -v /redis/slave_3/:/redis/cluster/ -v /redis/redis_cluster.conf:/usr/local/etc/redis/redis.conf --hostname=slave_3 --name=slave_3 redis redis-server /usr/local/etc/redis/redis.conf --port 6384
docker run -d --rm --network=host -v /redis/master_c_4/:/redis/cluster/ -v /redis/redis_cluster.conf:/usr/local/etc/redis/redis.conf --hostname=master_c_4 --name=master_c_4 redis redis-server /usr/local/etc/redis/redis.conf --port 6385
docker run -d --rm --network=host -v /redis/slave_4/:/redis/cluster/ -v /redis/redis_cluster.conf:/usr/local/etc/redis/redis.conf --hostname=slave_4 --name=slave_4 redis redis-server /usr/local/etc/redis/redis.conf --port 6386

创建集群:
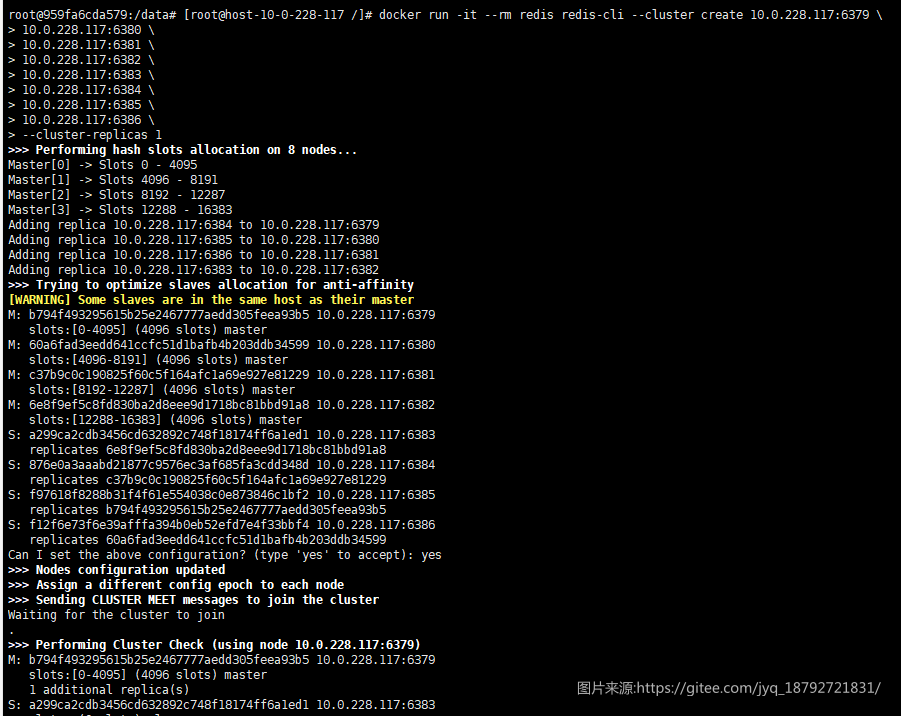
检测:

fix
redis-cli --cluster fix <集群内任一ip:port>
检测出错了,可以使用这个命令处理
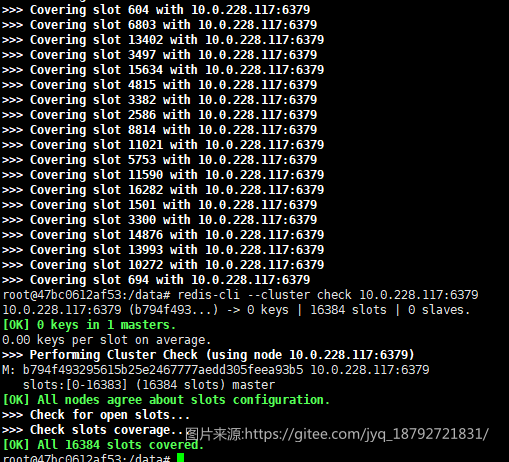
修复的结果就是将全部的slot分配给第一个机器

reshard
redis-cli --cluster reshared <集群内任一ip:port>
可选参数:
--cluster-from
--cluster-to
--cluster-slots
--cluster-yes
--cluster-timeout
--cluster-pipeline
--cluster-replace
[root@master1 ~]# redis-cli --cluster reshard 192.168.100.41:6379
How many slots do you want to move (from 1 to 16384)? 4096 '//要迁移多少个槽'
What is the receiving node ID? 99521b7fd126b694bcb9a22ffa5a490f31f66543 '//迁移到哪个节点,数据节点id'
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
'//要求输入源节点的id,这里因为原本有三个节点,输入done表示结束'
Source node #1: 7f112f82bcf28a5d0627ea81b48cb76f4ea8605d
Source node #2: df195a34a91d756157a0fda7c71e99d5bd8fad09
Source node #3: a233a23541f431107fed79908318394d8bb30b51
Source node #4: done
'//最后会有一个迁移方案,输入yes表示同意,迁移开始。输入no表示不同意,重新设置迁移方案。'
'//确认是否迁移成功'
[root@master1 ~]# redis-cli -h 192.168.100.41 -p 6379
192.168.100.41:6379> cluster nodes
...省略内容

迁移slot
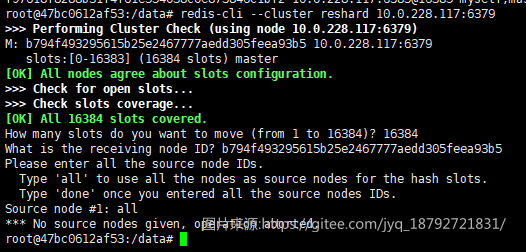
发现只有一个机器,不够用,现在每一个机器都是隔离的:

我们将其连接起来

我们设置主从节点
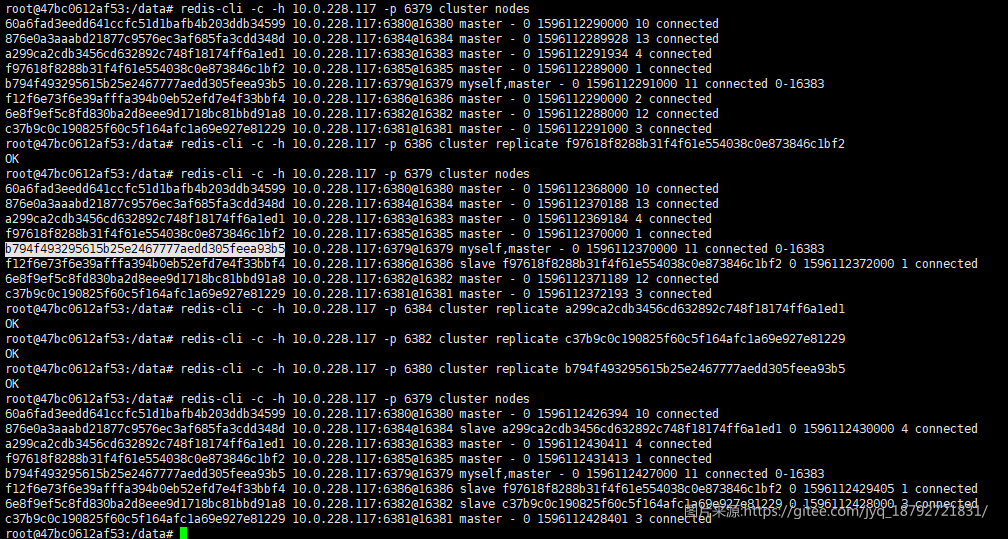
迁移slot

rebalance
redis-cli --cluster rebalance <集群内任一ip:port>
自动平衡hash slot

del-node
redis-cli --cluster del-node <集群内ip:port>
删除节点
add-node
redis-cli --cluster add-node <集群外的ip:port> <集群内任一ip:port>

不知道为什么--cluster-master-id没生效

import
redis-cli --cluster import <集群外ip:port>
将redis实例倒入集群(倒入数据)

[ERR] The source node should not be a cluster node.
因为6386也是一个集群节点,cluster-enabled=true

新建一个redis实例,使用默认配置。
然后倒入
