机器学习系列 03:线性回归模型
本内容将介绍机器学习中的 线性回归模型,及 Python 代码实现。
线性模型形式简单、易于建模,但却蕴涵这机器学习中一些重要的基本思想。许多功能更为强大的非线性模型(nonlinear model)可在线性模型的基础上通过引入层级结构或高维映射而得。
线性回归意味着可以将输入项分别乘以一些常量,再将结果加起来得到输出。回归需要数值型数据,标称型数据将被转化成二值型数据。
一、线性回归模型
给定一个数据集 D = { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , ⋯ , ( x ( m ) , y ( m ) ) } D=\{(\mathbf{x}^{(1)},y^{(1)}),(\mathbf{x}^{(2)},y^{(2)}),\cdots,(\mathbf{x}^{(m)},y^{(m)})\} D={(x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m))},其中 x ( i ) = ( x 1 ( i ) ; x 2 ( i ) ; ⋯ ; x n ( i ) ) \mathbf{x}^{(i)}=(x_{1}^{(i)};x_{2}^{(i)};\cdots;x_{n}^{(i)}) x(i)=(x1(i);x2(i);⋯;xn(i))(表示 x \mathbf{x} x 拥有 n n n 个属性), y i ∈ R y_i\in\mathbb{R} yi∈R。线性回归(linear regression)试图学得一个通过特征值的线性组合以尽可能准确地预测输出标记。学得的模型如下:
(1) f ( x ) = w 1 x 1 + w 2 x 2 + ⋯ + w n x n + b f(x)=w_1x_1+w_2x_2+\cdots+w_nx_n+b \tag{1} f(x)=w1x1+w2x2+⋯+wnxn+b(1)
或者
(2) f ( x ) = ∑ i = 0 n w i x i f(x)=\sum_{i=0}^{n}w_ix_i \tag{2} f(x)=i=0∑nwixi(2)
其中 x 0 = 1 x_0=1 x0=1, w 0 = b w_0=b w0=b。用向量形式写成
(3) f ( x ) = w T x f(\mathbf{x})=\mathbf{w}^T\mathbf x \tag{3} f(x)=wTx(3)
其中 w = ( w 0 ; w 1 ; ⋯ ; w n ) \mathbf{w}=(w_0;w_1;\cdots;w_n) w=(w0;w1;⋯;wn), x = ( x 0 ; x 1 ; ⋯ ; x n ) \mathbf{x}=(x_0;x_1;\cdots;x_n) x=(x0;x1;⋯;xn), x 0 = 1 x_0=1 x0=1。
当 w \mathbf{w} w(即 w 0 , w 1 , ⋯ , w n w_0,w_1,\cdots,w_n w0,w1,⋯,wn) 学得之后,模型就得以确定。但是如何才能求得 w \mathbf{w} w 呢?
为了便于理解,我们先考虑最简单的情况:即输入 x x x 只有一个属性。那么线性回归试图学得的模型如下:
(4) f ( x ) = w x + b f(x)=wx+b \tag{4} f(x)=wx+b(4)
对离散属性,若属性值间存在“序”关系,可以通过连续化将其转化为连续值;若属性值间不存在序关系,则通常转为为 k k k 维向量。
如何确定 w w w 和 b b b 呢?一个常用的方法:找出使损失函数最小的 w w w 和 b b b。下面我们就来介绍一下线性回归模型的损失函数。
二、损失函数
线性回归模型最常用的损失函数是平方损失函数,即
(5) E ( w , b ) = ∑ i = 1 m 1 2 m ( f ( x ( i ) ) − y ( i ) ) 2 = ∑ i = 1 m 1 2 m ( w x ( i ) + b − y ( i ) ) 2 E(w,b) = \sum_{i=1}^{m}\frac{1}{2m} (f(x^{(i)})-y^{(i)})^{2} = \sum_{i=1}^{m}\frac{1}{2m} (wx^{(i)}+b-y^{(i)})^2 \tag{5} E(w,b)=i=1∑m2m1(f(x(i))−y(i))2=i=1∑m2m1(wx(i)+b−y(i))2(5)
其中 m m m 为数据集中样本数量。这里乘以 1 2 \frac{1}{2} 21 是为了后面计算更加方便,实际上是否乘以 1 2 \frac{1}{2} 21 ,对最终的最优解都不会产生影响。
为了求得的线性回归模型更好地拟合数据集,我们需要试图让平方损失函数最小化,即
(6) m i n w , b ∑ i = 1 m 1 2 m ( f ( x ( i ) ) − y ( i ) ) 2 = m i n w , b ∑ i = 1 m 1 2 m ( w x ( i ) + b − y ( i ) ) 2 min_{w,b} \sum_{i=1}^{m}\frac{1}{2m} (f(x^{(i)})-y^{(i)})^2 = min_{w,b} \sum_{i=1}^{m}\frac{1}{2m} (wx^{(i)}+b-y^{(i)})^2 \tag{6} minw,bi=1∑m2m1(f(x(i))−y(i))2=minw,bi=1∑m2m1(wx(i)+b−y(i))2(6)
三、最小二乘法
基于均方误差最小化来进行模型求解的方法称为“最小二乘法”(least square method)。在线性回归中,最小二乘法是试图找到一条直线,使所有样本到直线上的欧式距离之和最小。
求解 w w w 和 b b b 使 E ( w , b ) E(w,b) E(w,b) 最小化的过程,称为线性回归模型的最小二乘“参数估计”(parameter estimation)。我们可将 E ( w , b ) E(w,b) E(w,b) 分别对 w w w 和 b b b 求导,得到
(7) ∂ E ( w , b ) ∂ w = 1 m ( ∑ i = 1 m ( w x ( i ) + b − y ( i ) ) x ( i ) ) = 1 m ( w ∑ i = 1 m ( x ( i ) ) 2 − ∑ i = 1 m ( y ( i ) − b ) x ( i ) ) \frac{\partial E(w,b)}{\partial w} = \frac{1}{m} \Big(\sum_{i=1}^{m}(wx^{(i)}+b-y^{(i)})x^{(i)}\Big)= \frac{1}{m} \Big(w\sum_{i=1}^{m}(x^{(i)})^2-\sum_{i=1}^m(y^{(i)}-b)x^{(i)}\Big) \tag{7} ∂w∂E(w,b)=m1(i=1∑m(wx(i)+b−y(i))x(i))=m1(wi=1∑m(x(i))2−i=1∑m(y(i)−b)x(i))(7)
(8) ∂ E ( w , b ) ∂ b = 1 m ( ∑ i = 1 m ( w x ( i ) + b − y ( i ) ) ) = 1 m ( m b − ∑ i = 1 m ( y ( i ) − w x ( i ) ) ) \frac{\partial E(w,b)}{\partial b}= \frac{1}{m} \Big(\sum_{i=1}^{m}(wx^{(i)}+b-y^{(i)})\Big) = \frac{1}{m} \Big(mb-\sum_{i=1}^{m}(y^{(i)}-wx^{(i)})\Big) \tag{8} ∂b∂E(w,b)=m1(i=1∑m(wx(i)+b−y(i)))=m1(mb−i=1∑m(y(i)−wx(i)))(8)
然后令上面式(7)和式(8)求得的两个偏导数为零,可求得 w w w 和 b b b 最优解的闭式解
(9) w = ∑ i = 1 m y ( i ) ( x ( i ) − x ˉ ) ∑ i = 1 m ( x ( i ) ) 2 − 1 m ( ∑ i = 1 m x ( i ) ) 2 w = \frac{\sum_{i=1}^{m}y^{(i)}(x^{(i)}-\bar x)}{\sum_{i=1}^{m}(x^{(i)})^2-\frac{1}{m}\Big(\sum_{i=1}^{m}x^{(i)}\Big)^2} \tag{9} w=∑i=1m(x(i))2−m1(∑i=1mx(i))2∑i=1my(i)(x(i)−xˉ)(9)
(10) b = 1 m ∑ i = 1 m ( y ( i ) − w x ( i ) ) b=\frac{1}{m}\sum_{i=1}^{m}(y^{(i)}-wx^{(i)}) \tag{10} b=m1i=1∑m(y(i)−wx(i))(10)
上面我们只讨论了只有一种属性的情况,即单变量线性回归(也称一元线性回归)。更一般的情况,输入 x x x 有 n n n 个属性。此时试图学得
(11) f ( x ) = w T x f(\mathbf{x})=\mathbf{w}^T\mathbf{x} \tag{11} f(x)=wTx(11)
这称为多变量线性回归(也称多元线性回归)。
同样,可利用最小二乘法来对 w \mathbf{w} w 进行估计。把数据集 D D D 表示为一个 m × ( n + 1 ) m\times (n+1) m×(n+1) 大小的矩阵 X \mathbf{X} X,即
(12) X = [ x 1 ( 1 ) x 2 ( 1 ) ⋯ x n ( 1 ) 1 x 1 ( 2 ) x 2 ( 2 ) ⋯ x n ( 2 ) 1 ⋮ ⋮ ⋱ ⋮ ⋮ x 1 ( m ) x 2 ( m ) ⋯ x n ( m ) 1 ] = [ ( x ( 1 ) ) T 1 ( x ( 2 ) ) T 1 ⋮ ⋮ ( x ( m ) ) T 1 ] \mathbf{X} = \begin{bmatrix} x_1^{(1)} & x_2^{(1)} & \cdots & x_n^{(1)} & 1\\ x_1^{(2)} & x_2^{(2)} & \cdots & x_n^{(2)} & 1\\ \vdots & \vdots & \ddots & \vdots & \vdots \\ x_1^{(m)} & x_2^{(m)} & \cdots & x_n^{(m)} & 1 \\ \end{bmatrix} = \begin{bmatrix} (x^{(1)})^{T} & 1\\ (x^{(2)})^{T} & 1\\ \vdots & \vdots \\ (x^{(m)})^{T} & 1 \\ \end{bmatrix} \tag{12} X=⎣⎢⎢⎢⎢⎡x1(1)x1(2)⋮x1(m)x2(1)x2(2)⋮x2(m)⋯⋯⋱⋯xn(1)xn(2)⋮xn(m)11⋮1⎦⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎡(x(1))T(x(2))T⋮(x(m))T11⋮1⎦⎥⎥⎥⎤(12)
再把所有标记也写成向量形式 y = ( y 1 ; y 2 ; ⋯ , y m ) \mathbf{y}=(y_1;y_2;\cdots,y_m) y=(y1;y2;⋯,ym),则有
(13) E ( w ) = 1 2 m ( y − X w ) T ( y − X w ) E(\mathbf{w}) = \frac{1}{2m} (\mathbf{y}-\mathbf{X}\mathbf{w})^{T}(\mathbf{y}-\mathbf{X}\mathbf{w}) \tag{13} E(w)=2m1(y−Xw)T(y−Xw)(13)
将 E ( w ) E(\mathbf{w}) E(w) 对 w \mathbf{w} w 求导得到
(14) ∂ E ( w ) ∂ w = 1 m X T ( X w − y ) \frac{\partial E(\mathbf{w})}{\partial \mathbf{w}} = \frac{1}{m} \mathbf{X}^{T}(\mathbf{X}\mathbf{w}-\mathbf{y}) \tag{14} ∂w∂E(w)=m1XT(Xw−y)(14)
令上式为零,可求得 w \mathbf{w} w 的解
(15) w = ( X T X ) − 1 X T y \mathbf{w} = (\mathbf{X}^{T}\mathbf{X})^{-1}\mathbf{X}^{T}\mathbf{y} \tag{15} w=(XTX)−1XTy(15)
注意,上述公式中包含 ( X T X ) − 1 (\mathbf{X}^{T}\mathbf{X})^{-1} (XTX)−1,也就是需要对矩阵求逆,因此这个方程只在逆矩阵存在的时候适用。然而,在现实任务中 X T X \mathbf{X}^{T}\mathbf{X} XTX 往往不是满秩矩阵,即不可逆。在这种情况下,我们可以使用梯度下降法求得 w \mathbf{w} w。
四、梯度下降法
4.1 算法介绍
梯度下降法(Gradient descent)是一个一阶最优化算法,通常也称为最速下降法。要使用梯度下降法找一个一个函数的局部极小值,必须向函数上当前点对应梯度的反方向的规定步长距离点进行迭代搜索。
首先,我们为 w \mathbf{w} w 初始化一个随机值,然后每次向 E ( w ) E(\mathbf{w}) E(w) 的梯度的相反方向来修改 w \mathbf{w} w。经过数次迭代后最终达到函数最小值点。那么,梯度下降法的公式
(16) w ^ = w − η ∇ E ( w ) \mathbf{\hat w} = \mathbf{w}-\eta \nabla E(\mathbf{w}) \tag{16} w^=w−η∇E(w)(16)
其中 η \eta η 是学习速率, ∇ \nabla ∇ 是梯度算子,这里的 ∇ E ( w ) \nabla E(\mathbf{w}) ∇E(w) 的值实际上就是上面的式(14),可得到 w \mathbf{w} w 的更新公式
(17) w ^ = w − η 1 m X T ( X w − y ) = w + η 1 m X T ( y − X w ) \mathbf{\hat w} = \mathbf{w}-\eta \frac{1}{m} \mathbf{X}^{T}(\mathbf{X}\mathbf{w}-\mathbf{y}) = \mathbf{w} + \eta \frac{1}{m} \mathbf{X}^{T}(\mathbf{y} - \mathbf{X}\mathbf{w}) \tag{17} w^=w−ηm1XT(Xw−y)=w+ηm1XT(y−Xw)(17)
在上面的公式中,输入和输出分别是以矩阵和向量的方式表式的,看起来可能有些不好理解。下面我们换一种方式来表示
(18) E ( w ) = ∑ i = 1 m 1 2 m ( f ( x ( i ) ) − y ( i ) ) 2 = ∑ i = 1 m 1 2 m ( w T x ( i ) − y ( i ) ) 2 E(\mathbf{w}) = \sum_{i=1}^{m} \frac{1}{2m} (f(x^{(i)})-y^{(i)})^2 = \sum_{i=1}^{m}\frac{1}{2m} (\mathbf{w}^T\mathbf{x}^{(i)} - y^{(i)})^2 \tag{18} E(w)=i=1∑m2m1(f(x(i))−y(i))2=i=1∑m2m1(wTx(i)−y(i))2(18)
对 E ( w ) E(\mathbf{w}) E(w) 求导得到
(19) ∇ E ( w ) = 1 m ∑ i = 1 m ( f ( x ( i ) ) − y ( i ) ) x ( i ) \nabla E(\mathbf{w}) = \frac{1}{m} \sum_{i=1}^{m}(f(x^{(i)}) - y^{(i)})\mathbf{x}^{(i)} \tag{19} ∇E(w)=m1i=1∑m(f(x(i))−y(i))x(i)(19)
可得到 w \mathbf{w} w 的更新公式
(20) w ^ = w − η 1 m ∑ i = 1 m ( f ( x ( i ) ) − y ( i ) ) x ( i ) = w + η 1 m ∑ i = 1 m ( y ( i ) − f ( x ( i ) ) ) x ( i ) \mathbf{\hat w} = \mathbf{w} - \eta \frac{1}{m} \sum_{i=1}^{m}(f(x^{(i)}) - y^{(i)})\mathbf{x}^{(i)} = \mathbf{w} + \eta \frac{1}{m} \sum_{i=1}^{m}(y^{(i)} - f(x^{(i)})) \mathbf{x}^{(i)} \tag{20} w^=w−ηm1i=1∑m(f(x(i))−y(i))x(i)=w+ηm1i=1∑m(y(i)−f(x(i)))x(i)(20)
关于梯度下降法详细的介绍,可以参阅这里。
4.2 代码实现
下面使用随机梯度下降法拟合一个线性回归模型。代码如下(Python 3.x):
import numpy as np
import matplotlib.pyplot as plt
class LinearRegression:
"""
初始化线性回归模型,并初始化权值(weights)和偏置(bias)。
feature_num:feature 数量
"""
def __init__(self, feature_num):
self.feature_num = feature_num
self.weights = np.zeros(feature_num)
self.bias = 0
pass
def __str__(self):
return 'weights: %s, bias = %f\n' % (self.weights, self.bias)
def _process_data(self, datas):
x_arr = np.array([x[0] for x in datas])
y_arr = np.array([x[1] for x in datas])
return x_arr, y_arr
"""
更新权值
"""
def _update_weights(self, feature, output, label, learning_rate):
delta = label - output
self.weights += learning_rate * delta * feature
self.bias += learning_rate * delta
def _one_iteration(self, features, labels, learning_rate):
samples = zip(features, labels)
for (feature, label) in samples:
output = self.predict(feature)
# 使用随机梯度下降法更新权值,即每次只使用一个样本
self._update_weights(feature, output, label, learning_rate)
"""
进行模型训练
train_datas:训练数据,输入格式[[输入], 输出]
iteration:训练迭代次数
learning_rate:学习速率
"""
def train(self, train_datas, iteration, learning_rate=0.01):
# 对训练数据进行处理
features, labels = self._process_data(train_datas)
# 进行 iteration 次迭代训练
for i in range(iteration):
self._one_iteration(features, labels, learning_rate)
"""
进行预测
"""
def predict(self, feature):
return sum(feature* self.weights) + self.bias
def get_training_datas():
datas = [[[1], 5], [[2], 6], [[5], 14], [[4.5], 12], [[9], 21.5], [[11], 25]]
return datas
if __name__ == "__main__":
# 获取训练数据
datas = get_training_datas()
# 训练获取线性回归模型
linear_regression = LinearRegression(1)
linear_regression.train(datas, 100, 0.01)
print(linear_regression)
# 绘图
xArr = np.array([x[0] for x in datas])
yArr = np.array([x[1] for x in datas])
yArr_output = np.array([linear_regression.predict(x) for x in xArr])
plt.plot(xArr, yArr, 'bx', xArr, yArr_output, 'r')
plt.show()
运行以上代码,将绘制出如下图形:
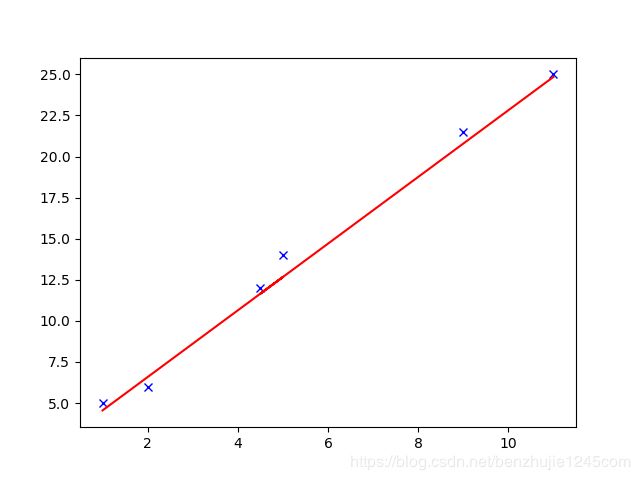
参考:
[1] 周志华《机器学习》
[2] 《机器学习实战》
[3] https://www.zybuluo.com/hanbingtao/note/448086