Hive Metastore 代码简析
1. hive metastore 内部结构
1.1 包结构

从package结构来看,主要的5个package,让我们来看看这几个package的内容
(1) metastorepackage是metastore 模块的入口,也是整个metastore模块的核心所在,里面包含了HiveMetaStore类作为整个模块的核心,接收来自hive的请求,返回需要的信息。
(2) metastore.apipackage包含了调用和访问metastore模块的接口以及接口参数和返回值类型,metastore模块的用户可以通过api对metastore模块进行访问
(3)metastore.events 用于metastore模块内部的观察者模式。因为metastore模块是支持notification通知机制和一些其他的后续处理的。通过观察者模式,当metastore对元信息进行一些操作以后,会同时产生一些event,这些event会被它们的listener捕获,并作出一些相应的处理,如发出一些通知等。
(4)metastore.model 与数据持久化相关,metastore模块通过datanucleus库将model持久化到数据库,这里的model与数据库中的表是对应的。
(5)metastore.tools 是供后台的元信息数据管理员对元信息进行查看和修改的工具。
1.2. 类结构
在上述的5个package,比较核心比较重要的是metastore package,让我们来详细看看其中的类结构。

(1) 首先看看client,HiveMetaStoreClient继承自IMetaStoreClient接口,HiveMetaStoreClient可以通过本地和远程两种方式访问和调用HIveMetaStore的Server。
(2) 核心部分是HiveMetaStore的内部类HMSHandler,它继承自IHMSHandler接口,IHMSHandler又继承自ThrifHiveMetastore.Iface接口,提供通过Thrift方式进行远程的调用。在HiveMetaStore. HMSHandler内实现了接口的所有metastore模块对外的方法。
(3) ObjectStore继承自RowStore接口,是用于对数据进行持久化的部分,Object可以从数据库中获取数据并映射到model的对象中,或者将model中的对象存入数据库。
(4)HiveAlterHandler 继承自AlterHandler接口,从HMSHandler分离出来专门进行Alter一类操作。
(5)Warehouse 主要作用是对HDFS上的文件进行操作。因为在修改元信息的同时可能会涉及到HDFS上的一些文件操作,如mkdir,delteDir等操作。
(6)MetaStorePreEventListener,MetaStoreEventListener,MetaStoreEndFunctionListener通过观察者模式对产生的event进行相应的处理的观察者。这三个类都是抽象类,由其他一些具体的类来继承和实现。
2. hive 与metastore交互
再来看看hive 是如何与metastore交互的,下面从两个例子来看,一个例子是一个DDL的hql指令,另一个是ANALYZE的hql指令。
2.1 DDLql
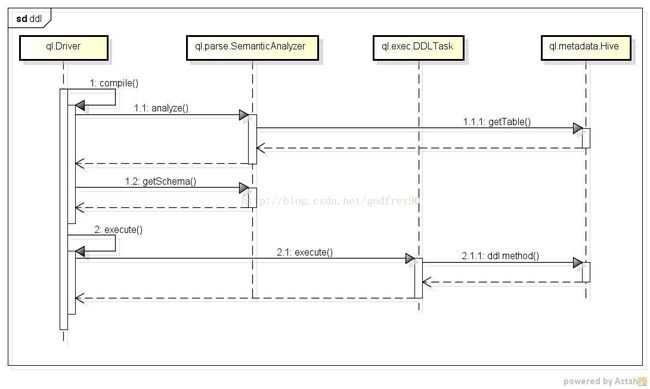
(1) 在ql.Driver中对command进行compile,需要调用ql.parse.Semantic.Analyzer的analyze方法对command进行分析优化,ql.parse.Semantic.Analyzer此时会调用ql.metadata.Hive的getTable方法获取表信息,ql.metadata.Hive是ql模块中用于与metastore模块交互的类,它会通过HiveMetaStoreClient去访问和调用metastore模块。
(2) compile的过程还会调用ql.parse.Semantic.Analyzer的getSchema方法获取Schema的信息,这个信息会在上一步保存在ql.parse.Semantic.Analyzer中。
(3) 接着在ql.Driver中会对command进行execute,execute的过程新建一个ql.exec.DDLTask来进行DDL指令的执行,在ql.exec.DDLTask中会调用ql.metadata.Hive中的一些DDL的方法去执行DDL处理。
这个例子是一个不包含map-reduce处理的例子,只对metastore中的元信息进行修改,下面这个例子则包含了map-reduce的处理和metastore中元信息的修改。
2.2 ANALYZEql
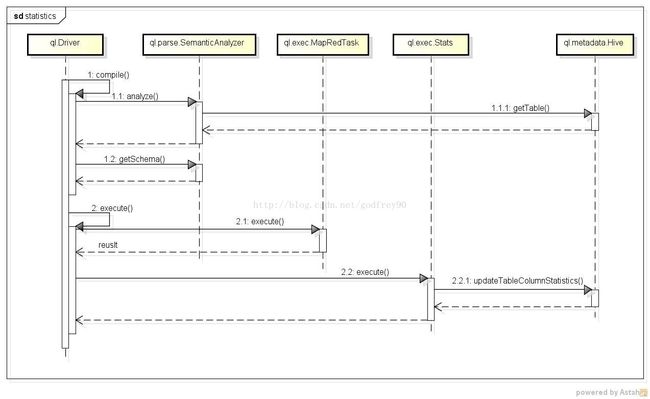
(1) 这里的compile过程和上一个例子类似,不再赘述。
(2) 接着在ql.Driver中会对command进行execute,execute的过程新建一个ql.exec.MapRedTask来进行map-reduce的处理,在ql.exec.MapRedTask的execute过程中会新建一个map-reduce的job,通过命令行调用的方式向hadoop提交这个job,并接收map-reduce的处理结果,储存在上下文环境中。
(3) 在map-reduce的job运行完以后,ql.Driver会再次新建一个ql.exec.Stats来处理分析统计信息,ql.exec.Stats的execute过程会调用ql.metadata.Hive的updateTableColumnStatistics或者updataPartitionColumnStatistics方法(这里会根据command的不同来选择)去更新metastore中的统计信息。
3. 对于metastore中数据库容量和扩展性的预估
从大容量和扩展性来讲占存储空间的主要的Model或Table如下:
Database,Table, Partition 和 Role
我们从添加database,table,partition,role的方法入手计算需要消耗多少的存储空间。
注:R(x) 表示x表一行的大小;N(x)表示系统中有多少的x的实例,即x表的行数; k表示一个较小的数
(1) 创建N(database)个database,向database和database_params表中添加数据,大概是
(R(database)+k*R(database_params))*N(database)
(2) 创建N(table)个table,每个table需要向table表和table_params表中添加数据为
R(table)+k*R(table_params)
同时需要添加TableColumnPrivilege,TableColumnStatistics, TablePrivilege, 每个table对应的大小为
N(column)*R(TableColumnPrivelege)+R(TableColumnStatistics)+R(TablePrivelege)
还需要添加StorageDescriptor,因为StorageDescriptor包含Column信息,每个table对应的大小为
N(column)*R(FieldSchema)+R(SerDeInfo)
总体来说添加N(table)个table,需要添加的数据大小为:
[R(table)+k*R(table_params)+
N(column)*R(TableColumnPrivelege)+R(TableColumnStatistics)+R(TablePrivelege)+
N(column)*R(FieldSchema)+R(SerDeInfo)]
*N(table)
(3) 创建N(partion)个partion,每个partion需要向patition表和partition_params表以及table表中添加数据为
R(partition)+k*R(partition_params)+R(FileSchema)
同时需要添加PartitionColumnPrivilege, PartitionColumnStatistics,PartitionPrivilege, 每个partition对应的大小为
N(column)*R(PartitionColumnPrivelege)+R(PartitionColumnStatistics)+R(PartitionPrivelege)
总体来说添加N(partition)个partition,需要添加的数据大小为:
[R(partition)+k*R(partition_params)+N(partition)*R(FileSchema)+
N(column)*R(PartitionColumnPrivelege)+R(PartitionColumnStatistics)+R(PartitionPrivelege)]
*N(partition)
(4) 创建N(role)个role,需要添加的大小为:
N(role)*R(role)
总计数据库存储文件大小为
(R(database)+k*R(database_params))*N(database)+
[R(table)+k*R(table_params)+
N(column)*R(TableColumnPrivelege)+R(TableColumnStatistics)+R(TablePrivelege)+
N(column)*R(FieldSchema)+R(SerDeInfo)]
*N(table)+
[R(partition)+k*R(partition_params)+R(FileSchema)+
N(column)*R(PartitionColumnPrivelege)+R(PartitionColumnStatistics)+R(PartitionPrivelege)]
*N(partition)+
N(role)*R(role)
将R(x) 精简为R,则总计大小为:
k*R*N(database)+2*R*N(column)*N(table)+R*N(column)*N(partition)+R*N(role)
=[k*N(database)+N(role)+2*N(column)*N(table)+N(column)*N(partition)]*R