CS224N(Natural Language Processing with Deep Learning)总结:模型、任务、作业、作业中涉及到的特殊代码

模型:word2vec(skip-gram、CBOW)、GloVe、DNN/BP/Tips for training、RNN/GRU/LSTM、Attention、CNN、TreeRNN
应用:Neural Machine Translation、Dependency Parsing、Coreference Resolution
作业:skip-gram、window-based sentiment classification;dependency parsing;named entity recognition、RNN、GRU;question answer!
收获很大!!!
=======================课程中涉及到的模型、方法
训练word embedding的方法:
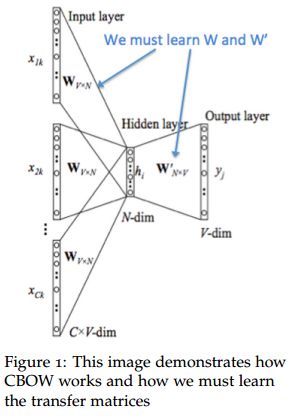
word2vec:skip-gram(根据中间的词预测周围的词)、CBOW(根据周围词的(平均)预测中间的词)
This captures co-occurrence of words one at a time
==》一般直接用W作为最终的embedding

GloVe:考虑word-word co-occurrence以及单个word本身频率
This captures co-occurrence counts directly
==》一般用U+V作为最终的embedding

DNN, BP and Tips for training:
lecture notes写的很好:gradient check、regularization、dropout、activation function、data preprocessing、parameter initialization、optimizer
RNN, GRU, LSTM
Gradient vanishing:正交初始化+relu;或者使用GRU, LSTM
梯度爆炸:gradient clipping,[-5, +5] is a good choice
Fancy RNN:GRU, LSTM, bi-directional RNN, multi-layer RNN

Attention
Vanilla attention:global attention/local attention、soft attention/hard attention è dot-product attention;Multiplicative attention;Additive attention。
控制attention的位置:encourage covering ALL important parts;prevent attending to the same part repeatedly.(主要通过修改attention weight实现)
Self-attention:同一个RNN,当前的位置attend之前所有的位置
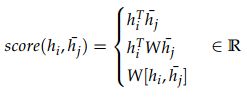


CNN
Main CNN idea: What if we compute multiple vectors for every possible phrase in parallel? (regardless of whether phrase is grammatical)
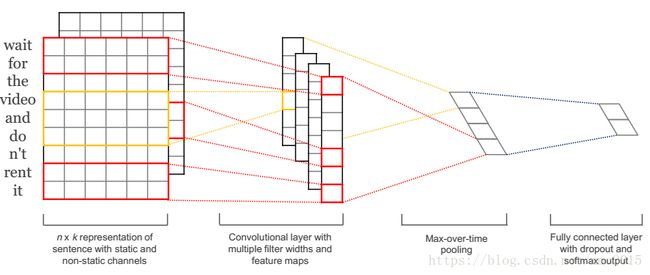
注意上图:输入是【两份】完全一样的pre-trained word vectors (word2vec or Glove);【 Both】 channels are used to generate the convolutional values of next layer before max-pooling;但是只对一个channel进行BP,另一个channel保持static! ==》 一个进行backprop,目的是为了根据当前的任务对pre-trained的embedding进行微调,可能是有好处的;一个保持static,需要所有words在pre-training的embedding space上保持semantic(防止training set中的words的embedding发生转移而test set中的new words却停留在原空间)。


另外,max-pooling可以处理变长输入的问题(RNN也有这个能力),the output from the CNN layers will be a vector having length equal to the number of filters:

Tree RNN(Recursive Neural Networks)


Recursive Neural Networks for Structure Prediction的三种模型即训练方法:
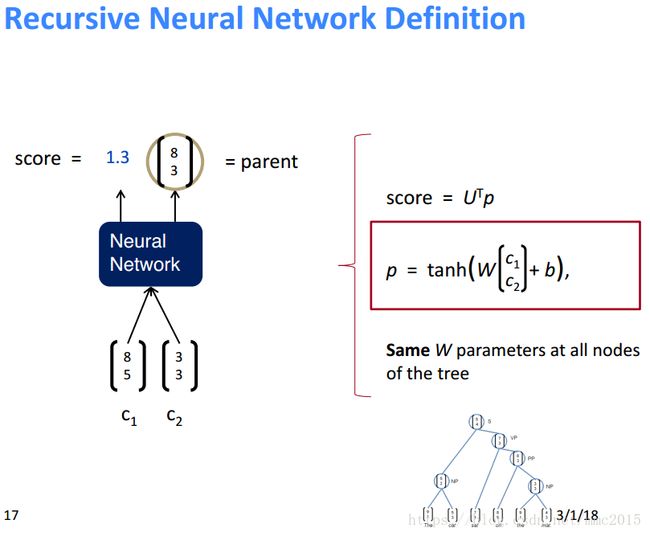

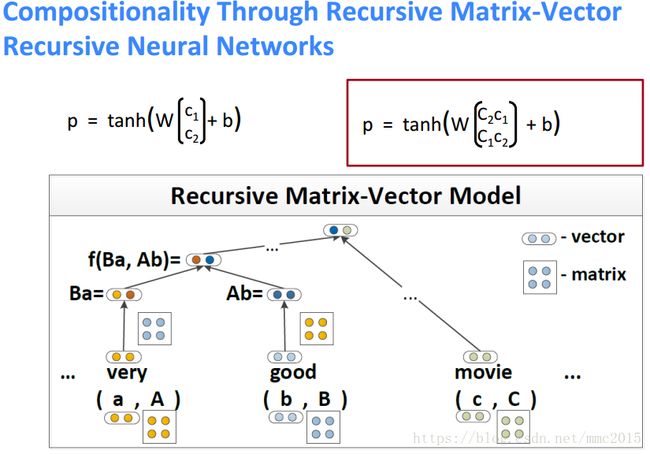

Model Comparison

Combine and extend creatively: TreeLSTMs、RNN+CNN、Neural Architecture Search、memory components
=======================课程中涉及到的任务
Neural Machine Translation
Vanilla Encoder-Decoder
Attention Encoder-Decoder(is now the new vanilla NMT method)
处理vocabulary size很大的问题(softmax计算代价大):
Noise Contractive Estimation and Hierarchical Softmax(在word2vec中同样适用;但在NMT的缺点是,只能在training知道true word的情况时使用,testing时不知道true word不能用)
Training/testing on a reduced vocabulary size (multiple training with different vocabulary)
处理rare/unknown word问题
Pointer network:在源语言句子上做attention,目的是copy源句子中的某个单词(人名、地名等)
Sub-word level NMT(或者结合word和sub-word)
处理多种源语言到多种目标语言的翻译

预测和训练不一致问题:训练时知道next true word,预测时只知道predicted next word!
防止重复生成同一个词,比如the poor poor poor people:将上一步生成的词y_t作为t+1时刻的输入
Google’s Transformer,只用attention加速并行NMT: “if attention gives us access to any state… maybe we don’t need the RNN? ”
Beam search
Dependency Parsing(依存句法分析):
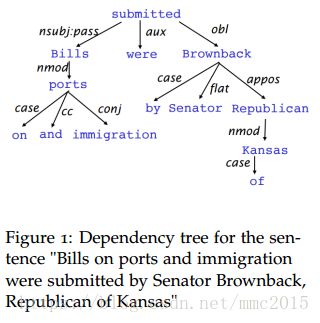
Greedy Deterministic Transition-Based Parsing:
stack [for the words that have been processed]
buffer [for the words to be processed]
transition={shift, left-arc, right-arc}, which is predicted by a neural model as following:

Coreference Resolution(指代消解)
需要两步:

三种指代消解方法:Mention Pair、Mention Ranking、Clustering-based
Mention Pair:

Mention Ranking:

Clustering-based:

=======================课程中涉及到的作业
Assignment 1: 从讲神经网络不得不提的Softmax开始,实现一个简单的神经网络,然后要求实现NLP中最基本最重要的两种WordVector模型(skip-gram),最后进行情感分析。
Assignment 2: 从这里开始就进入了全面使用TensorFlow的时代!需要code的作业不多,主要是理解与实现基于神经网络的依存句法模型(dependency parsing),最后有一些关于RNN的理论问题。
Assignment 3: NLP中又一个重要的问题:命名实体识别(NER),作业分别要求实现基于窗口的NER、基于简单RNN的NER以及基于GRU的NER。
Assignment 4: 这个Assignment更像一个final project,是在Stanford Question Answering Dataset (SQuAD)数据集上做阅读理解。围绕这个问题的研究今年也在不断深入,因此,有很多有意思的模型可以尝试跑一跑。

=======================作业中涉及到的特殊代码
======assignment1
1) dropout:
==> self.dropout_placeholder = tf.placeholder(dtype=tf.float32, name="dropout_prob") # for scalar, no need to set shape!
==> create_feed_dict{}, for train and test has different mode!
During training, use drop_proba, and scale non_drop values with γ=1/(1-drop_proba), and this has been done
[automatically] by tf.nn.dropout() ==> With probability keep_prob, outputs the input element scaled up by 1 / keep_prob, otherwise outputs 0. The scaling is so that the expected sum is unchanged.;
During testing, set drop_prob=0.0, and no need to scale the values!
==> tf.nn.dropout use the keep_prob parameter, not the drop_prob! h_drop = tf.nn.dropout(h, keep_prob=1-self.dropout_placeholder, name="h_drop")
2) embeddings:
==> pretrained_embeddings need set "trainable=False"
pretrained_embeddings = tf.Variable(initial_value=self.pretrained_embeddings, trainable=False, name="pretrained_embeddings")
==> use the tf.nn.embedding_lookup() to look_up embeddings
embeddings = tf.nn.embedding_lookup(params=pretrained_embeddings, ids=self.input_placeholder, name="embedding_lookup")
3) the use of xavier_weight_init
xavier_initializer = xavier_weight_init()
U = tf.get_variable(name="U", shape=[self.config.hidden_size, self.config.n_classes], initializer=xavier_initializer)
======assignment2
# In sparse_softmax_cross_entropy_with_logits, the labels are NOT one-hot vectors, but the list of indexs of the correct categories.
==> loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=self.labels_placeholder, logits=pred), name="loss")
======assignment3
# In RNN, we need to reuse the variable!
if time_step>0:
tf.get_variable_scope().reuse_variables()
# Using the masks as following:
masked_labels = tf.boolean_mask(tensor=self.labels_placeholder, mask=self.mask_placeholder)
masked_preds = tf.boolean_mask(tensor=preds, mask=self.mask_placeholder)
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=masked_labels, logits=masked_preds), name="loss")
# Using tf.nn.dynamic_rnn() to init a RNN model
outputs, state = tf.nn.dynamic_rnn(cell=cell, inputs=x, dtype=tf.float32, time_major=False)
# The implementation of gradient clipping:
gradient_variable_tuples_list = optimizer.compute_gradients(loss=loss)
grads, variables = zip(*gradient_variable_tuples_list)
if self.config.clip_gradients is True:
clipped_grads, global_norm = tf.clip_by_global_norm(t_list=grads, clip_norm=self.config.max_grad_norm)
gradient_variable_tuples_list = zip(clipped_grads, variables)
train_op = optimizer.apply_gradients(gradient_variable_tuples_list)