GPT-2代码解读[2]:Attention
GPT-2代码解读[2]:Attention
Overview
![GPT-2代码解读[2]:Attention_第1张图片](http://img.e-com-net.com/image/info8/32e9d48339644ae08f696b583c1329ef.jpg)
Attention模块的结构如上图所示,只有Linear部分是可训练的,第一次Linear将嵌入向量转换为Q,K,V1
,第二次Linear将Attention的结果重新转换为嵌入向量,作为下一层的输入。
从信息的角度来说,嵌入向量首先被转换2为三种信息,即Query,Key和Value。信息的本性由用法(去向)决定,而非由来源决定,例如,Query之所以是Query,是因为它在下式中与Key做点积3,只有当Query真正是Query的时候,点积的结果才有效,模型的效果才会好,而模型在训练过程中就是根据结果学习Linear层,让Query是Query。
在得到本次输入的Q,K和V之后,将K,V和之前的K,V拼接起来,使用下式做Attention,下式的含义是:
![GPT-2代码解读[2]:Attention_第2张图片](http://img.e-com-net.com/image/info8/c62c37446a964faabf68593c4a26e175.jpg)
Q K T QK^T QKT根据Query衡量上文的所有Key,归一化4为权重,然后将权重附加给已经上文所有Value,完成对上文的利用。
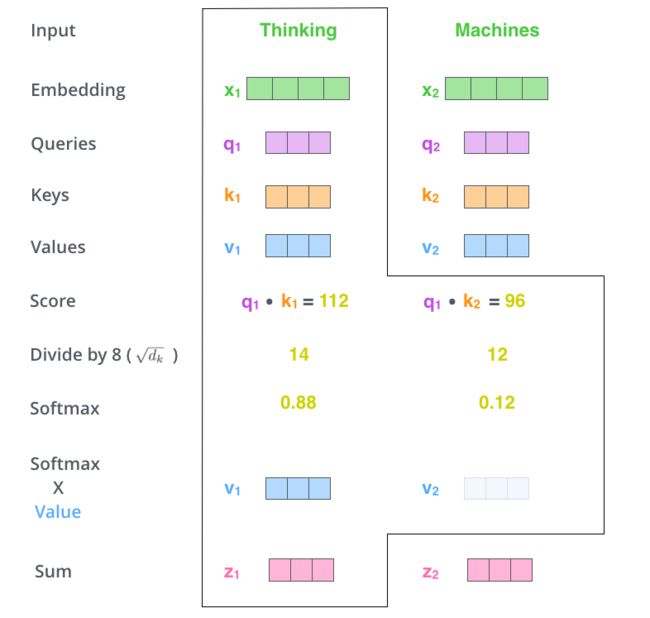
你可以通过上图和这篇博客得到一个完整的认识!
Code
我会分析GPT-2中的attn模块。
def attn(x, scope, n_state, *, past, hparams):
x是嵌入向量,n_state是嵌入维度,past是已经生成的K值和V值。此
此时x=[batch,seq,embedding]
该模块输入嵌入向量,输出该向量在本层5的特征。
c = conv1d(x, 'c_attn', n_state*3)
将x通过一次一维卷积,从embedding中提取n_state*3个特征,gpt-2中n_state=embedding。
此时c=[batch,seq,embedding*3]
def conv1d(x, scope, nf, *, w_init_stdev=0.02):
Y = W X + B Y=WX+B Y=WX+B
该函数将x原有的nx个feature线性变换为nf个feature,可以看作一维卷积,也可以看作一个Linear层。
*start, nx = shape_list(x)
nx是x目前feature数,start是其余shape。shape_list函数是将x的shape以列表返回。
w = tf.get_variable('w', [1, nx, nf], initializer=tf.random_normal_initializer(stddev=w_init_stdev))
w是第一层linear的参数,定义为[1,原feature数,新feature数] 6的变量7,并以正态分布初始化。
b = tf.get_variable('b', [nf], initializer=tf.constant_initializer(0))
b是第一层linear的偏移值,定义为[新feature]数的变量,并以常值0初始化。
c = tf.reshape(tf.matmul(tf.reshape(x, [-1, nx]), tf.reshape(w, [-1, nf]))+b, start+[nf])
c是线性变换的结果,这句话等价于C=WX+B,之所以显得冗长,是多次reshape造成的,根据经验,在batch matrix multiple之前先reshape为二维再乘,乘完reshape回来,会提升15~20倍的性能。
所以,最外层tf.reshape的目的是将结果转化为正确的三维shape,start+[nf]是列表的拼接,结合前面start的定义,其实就是将最后一维nx换为nf。
内层先reshape为二维,做矩阵乘,加上偏置。
回到attn。
q, k, v = map(split_heads, tf.split(c, 3, axis=2))
使用tf.split将特征分给q,k,v。
此时Q=K=V=[batch,seq,embedding]
这一步和图1不太一样,我们是先对X直接变换到 n s t a t e X 3 nstateX3 nstateX3 个feature,再将这些feature均匀分给Q,K,V。
而图1是通过三个不同的变换分别得到Q,K,V。这种区别是因为gpt-2里使用的是self-attention,三种变换的输入都是x,所以合并为一个。
接下来应用split_head,将特征分给多个attention头8。
此时q,k,v=[batch,head,seq,feature]。
def split_heads(x):
该函数完成头的划分。
x=[batch,seq,embedding]
return tf.transpose(split_states(x, hparams.n_head), [0, 2, 1, 3])
首先应用split_states,将x转换为[batch,seq,head,feature]。
然后使用tf.transpose,将原有维度重排为[batch,head,seq,feature],也就是将第一维和第二维交换位置。
def split_states(x, n):
该程序将x的最后一维分解为二维,即分出多头维。
回到attn。
present = tf.stack([k, v], axis=1)
present是tf.stack完成的k和v的堆叠,这一项会作为返回值返回,并且与之前的状态拼接,作为self-attention的对象。
if past is not None:
pk, pv = tf.unstack(past, axis=1)
k = tf.concat([pk, k], axis=-2)
v = tf.concat([pv, v], axis=-2)
这一段就是从之前的状态分出k和v,将其拼接到当前的k和v上。
拼接之前k=v=[batch,head,当前长度,feature],在拼接之后k=v=[batch,head,已生成长度+当前长度9,feature]
a = multihead_attn(q, k, v)
a是attn层的输出,也就是之后的h,是Q和K对的V加权和。
def multihead_attn(q, k, v):
![GPT-2代码解读[2]:Attention_第3张图片](http://img.e-com-net.com/image/info8/26c412fd3a5e4ed5ba8ba501f8742a2a.jpg)
w = tf.matmul(q, k, transpose_b=True)
W = Q K T W=QK^T W=QKT,matmul中transpose_b参数意味着乘之前将K转置。
注意Q=[batch,head,输入长度,feature],K=[batch,head,总长度,feature],matmul对最后二维进行,其实也就是Q的feature和K的feature做点积,W=[batch,head,输入长度,总长度],表示V的得分。
w = w * tf.rsqrt(tf.cast(v.shape[-1].value, w.dtype))
W = W d k W=\frac {W}{\sqrt d_k} W=dkW
这里v.shape[-1].value就是公式里的 d k d_k dk,因为k和v的最后一维相同,都是feature。
tf.cast将 d k d_k dk转型为float,tf.rsqrt取dk平方根的倒数。
w = mask_attn_weights(w)
Gpt-2等一系列Transformer生成模型使用masked attention,主要是为了避免模型在生成第i个词时使用i之后的词语, 因为在实际预测时后面的词是不可知的。
def mask_attn_weights(w):
该函数返回mask之后的权重矩阵W,准确地说,是将权重矩阵第i行的不可attend列置为0。
_, _, nd, ns = shape_list(w)
nd为输入长度,ns为总长度。
b = attention_mask(nd, ns, dtype=w.dtype)
b为非0即1的mask矩阵,后面会将b与w相乘。
def attention_mask(nd, ns, *, dtype):
![GPT-2代码解读[2]:Attention_第4张图片](http://img.e-com-net.com/image/info8/fa2aac09bf3d4af7b4f8d6be287a486f.jpg)
训练输入长度为3的mask矩阵,此时nd=ns=3。
i = tf.range(nd)[:,None]
j = tf.range(ns)
m = i >= j - ns + nd
i是[nd,1]的矩阵,i的含义是输入每个词相对输入起始词的距离。
tf.range(nd)产生0,1,2…nd的等差数列,shape=[nd]。
[:,None]的作用是在None的维添加一行,shape=[nd,1]。
nd=3时的下标矩阵:
![GPT-2代码解读[2]:Attention_第5张图片](http://img.e-com-net.com/image/info8/a000f2369f5e4eeea4ec2fe04787c3d6.jpg)
j是0,1,2…ns的等差数列,shape=[ns]
j − n s + n d = j − ( n s − n d ) j-ns+nd=j-(ns-nd) j−ns+nd=j−(ns−nd)
(ns-nd)的意义是去除输入的上文长度10,j-(ns-nd)的意义是上文每一个词相对输入起始词的距离。
![GPT-2代码解读[2]:Attention_第6张图片](http://img.e-com-net.com/image/info8/74304ed5ebbd418cb171ca62c2fd7942.jpg)
i>=j产生一个[nd,ns]的矩阵,i>=j为真代表当前输入词在上下文词的右边,因此可以attend,否则不可以。
return tf.cast(m, dtype)
将Bool类型转换为数值类型返回。
b = tf.reshape(b, [1, 1, nd, ns])
w = w*b - tf.cast(1e10, w.dtype)*(1-b)
将返回的mask矩阵reshape为四维11,然后与权重矩阵做element-wise的乘法。
后面减去1e10*(1-b),当b为1时无效果,当b为0时,等于减去1e10,一个很大的值,导致值变为-10e,也就导致softmax之后权重变为0.
mask部分至此完结,回到multihead_attn函数。
w = softmax(w)
a = tf.matmul(w, v)
将权重矩阵做一次softmax,将权重归一为[0,1]之间且和为1。
a = W V a=WV a=WV
此时W=[batch,head,输入长度,总长度],V=[batch,head,总长度,feature]
得到A=[batch,head,输入长度,feature],这就是Attention机制所提取的特征。
回到Attn函数。
a = merge_heads(a)
合并多头,这是分解多头精确的逆过程。
def merge_heads(x):
return merge_states(tf.transpose(x, [0, 2, 1, 3]))
首先将A转化为[batch,输入长度,head,feature],依然是通过tf.transpose交换中间两维实现的。
def merge_states(x):
*start, a, b = shape_list(x)
return tf.reshape(x, start + [a*b])
将最后两维reshape为一维,也就是将head个feature顺序堆叠。
此时A=[batch,输入长度,head*feature=embedding],萝卜回来了12。
a = conv1d(a, 'c_proj', n_state)
最后的线性变换。
Gpt-2 Attention到此结束,感谢阅读!
将在之后讨论 ↩︎
准确来说,是被提取为Q,K,V。之所以用提取而非转换,是因为提取在转换的含义之上,增加一层更本质的含义:从一类特征A,经过某种变换,变到另一类特征B,而不是从特征A直接变成特征B。。 ↩︎
点积越大的,角坐标越接近,当然也有其他衡量Q和K匹配程度的方法。 ↩︎
softmax将内积归一到0~1之间,除以 d k \sqrt{d_k} dk是为了不让内积差距过于悬殊,使得softmax非0即1。 ↩︎
在GPT-2里attn堆叠12层 ↩︎
在实际使用时会被先reshape为[nx,nf],我暂时不理解为什么要定义为[1,nx,nf] ↩︎
tensorflow中可训练的参数定义为variable。 ↩︎
另一种理解方式是,特征维度就是embedding/head,也就是说并非多个attention head分享embedding维度,每个head处理一部分,而是特征本身就是embedding/head,每个head独立地处理。illustrated transformer和原始paper考虑的是第二种方式。根据这种理解,我们将embedding/head定义为feature。 ↩︎
记做总长度 ↩︎
训练时为0 ↩︎
我不理解为什么必须reshape为4维,在自己的实验中,原始二维也work。如果你知道,请告诉我! ↩︎
童话梗。 ↩︎