常见“树”概念解析(1)
树是许多成熟的项目所使用的基本数据结构,也是面试常考、程序员必备的重中之重。
1 底层基础概念
1.1 平衡树
所谓平衡树的平衡,就是树上某节点的所有子树的高度差的绝对值不超过1,该规律应用在树中所有节点上。如果该树是二叉树,则该树是常见的是平衡二叉树。
1.2 平衡二叉树
满足平衡树概念的二叉树,常见实现有:
- 红黑树
- AVL树(平衡二叉树)
- 替罪羊树
- Treap(树堆)
- 伸展树
最小二叉平衡树的节点的公式如下 F(n)=F(n-1)+F(n-2)+1 这个类似于一个递归的数列,可以参考Fibonacci数列,1是根节点,F(n-1)是左子树的节点数量,F(n-2)是右子树的节点数量。
1.2.1 二叉树的平衡方法
-
二叉左旋
一棵二叉平衡树的子树,根是Root,左子树是x,右子树的根为RootR,右子树的两个孩子树分别为RLeftChild和RRightChild。则左旋后,该子树的根为RootR,右子树为RRightChild,左子树的根为Root,Root的两个孩子树分别为x(左)和RLeftChild(右)。
-
二叉右旋
一棵二叉平衡树的子树,根是Root,右子树是x,左子树的根为RootL,左子树的两个孩子树分别为LLeftChild和LRightChild。则右旋后,该子树的根为RootL,左子树为LLeftChild,右子树的根为Root,Root的两个孩子树分别为LRightChild(左)和x(右)。
1.3 查找树(搜索树)
《算法导论》的定义:
查找树是一种数据结构,既可以用作字典,也可以用作优先队列。
查找树支持多种动态集合操作:SEARCH、MINIMUM、MAXIMUM、PREDECESSOR(前)、SUCCESSOR(后)、INSERT以及DELETE。
查找树是有序的,具体表现为:树上某节点的左边所有子树的值<该节点的值<该节点的右边所有子树的值。该规律应用在树中所有节点上。如果该树是二叉树,则该树是常见的是二叉查找(搜索)树。
1.4 二叉查找(搜索、排序)树(BINARY SEARCH/SORT TREE)
在二叉查找树上执行上述基本操作的时间与树的高度成正比。下图所示是二叉查找树:
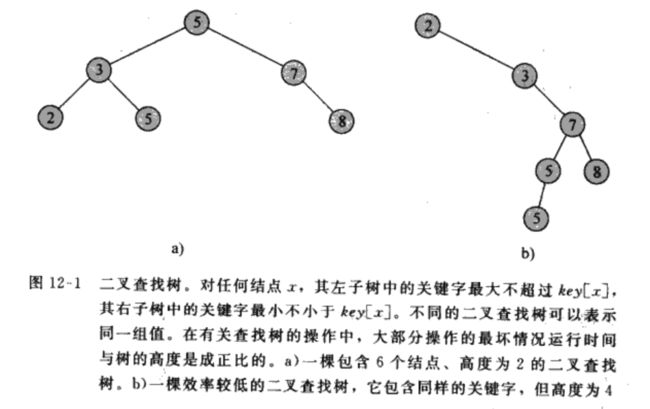
用链表表示的话,每个节点都是一个对象,节点中的data称之为Key关键字。
2 常见数据结构
2.1 红黑树
2.1.1 《算法导论(第2版)》的定义:
红黑树(Red Black Tree) 是一种自平衡二叉查找树。在每个节点上增加一个存储位表示节点的颜色,可以是红或者黑。通过对任何一条从根到叶子的路径上各个节点着色方式的限制,红黑树确保没有任何一条路径会比其他路径长出两倍。
上图二叉查找树中,一个节点对象有四个域:key,left,right,p(parent),而红黑树有五个域:color, key,left,right,p。key域不为空的这里称之为内节点,而key域为空的并且没有一个子节点或父节点的Nil节点视为外节点(如果有不懂请看下图)。
一颗二叉查找树如果满足如下的红黑性质,则是红黑树:
- 每个节点或是红的或是黑的。
- 根节点是黑的。
- 叶节点(Nil节点)是黑的。
- 如果一个节点是红的,它两个孩子节点都是黑的。
- 对每个节点,从该节点到其子孙节点的所有路径包含相同数目的黑色节点。
下图是一个红黑树的例子:
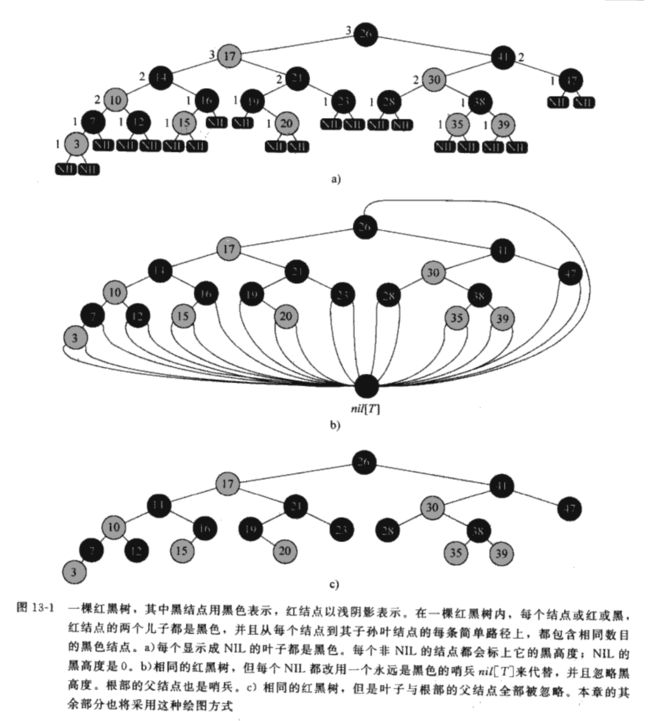
上图中有个哨兵的概念,该解释在《算法导论》10.2链表章节:
哨兵(sentinel)是个哑(dummy)对象,可以简化边界条件,例如,有链表L和一个对象nil[L],后者表示Nil,但也包含和其他元素一样的各个域。现在就可以将链表算法代码中出现的每次对Nil的引用,用对哨兵元素nil[L]的引用来代替。这样,就可以一个一般的双向链表,变成一个
带哨兵的环形双向链表。这时,链表的head不再需要了,因为可以通过next[nil[L]]来访问表头。如下图:

好,回到红黑树来。同样,为了处理红黑树T中的边界条件,采用哨兵来代表Nil,就可以将节点x的Nil孩子视为一个其父节点为x的普通节点。虽然我们可以在树内的每个Nil都做一个哨兵节点但是显然浪费空间,所以采用一个哨兵nil[T]来代表所有的Nil节点。
从某个节点x出发(不包括该节点)到达一个叶节点的任意路径上,黑色节点的个数称之为该节点的黑高度,用bh(x)表示,红黑树的黑高度定义为根节点的黑高度。
2.1.2 为什么红黑树是种好的查找树
《算法导论》中对红黑树的高度引理如下:
一颗有n个内节点的红黑树的高度至多为2lg(n+1)。
其证明如下:
先来通过归纳法证明以某一节点x为根的子树至少包含2^bh(x)-1个内节点。
-
如果x的高度是0,x必为一叶节点(nil[T]),这时bh(x)=0,满足2^bh(x)-1=0个内节点。
-
考虑一个其高度值为正值的内节点x,它有两个child,每个child根据其自身颜色是红还是黑,对应有黑高度bh(x)或bh(x)-1。因为x的child的高度小于x自身的高度,利用归纳,可得出每个child至少包含2(bh(x)-1)-1个内节点。这样,以x为根的子树至少包含(2(bh(x)-1)-1)+(2(bh(x)-1)-1)+1即左子树节点和右子树节点加根节点的和,也就是2(bh(x))-1个内节点。
这样证明了前面的推断。
设h为树的高度,根据性质4(如果一个节点是红的,它两个孩子都是黑的),可得出从根到叶节点(不包括根)的任何一条简单路径上至少有一半的节点是黑色。从而根的黑高度至少是h/2,所以,
n >= 2^(h/2) - 1
1移到另一侧,两边取对数,得
lg(n+1) >= h/2, 或者h <= 2lg(n+1)
所以,红黑树的动态集合操作可以在O(lgn)时间复杂度实现,因为从根到底的时间复杂度是O(h)。
红黑树的具体实现可以参考博文。
2.2 B树(B-树)
B树是为磁盘或其他直接存取辅助设备而设计的一种平衡查找树。与红黑树类似,但在降低磁盘I/O操作次数方面要好一些。许多数据库使用B树或B树的变形来存储信息。
B树是多叉树,这就是说,B树的“分支因子”可能很大,这一因子常常由所使用的磁盘特性决定的。
下图给出一个简单B树:
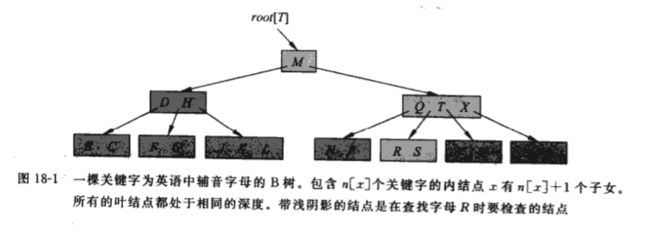
(解释一下图中节点由广度遍历顺序分别是 M、D H、Q T X、B C、F G、J K L、N P、R S、V W、Y Z)。
如果B树的内节点x包含n[x]个关键字,则x就有n[x]+1个子女。节点x中的关键字是用来将x所处理的关键字域划分成n[x]+1个子域的分割点,每个子域都由x中的一个子女来处理。
2.2.1 《算法导论(第3版)》的定义(B树的定义第3版比第2版清晰不易误解):
一棵B树T是具有如下性质的有根的树(根为root[T]):
- 每个节点x有以下域:
- x.n,当前存储在节点x中的关键字个数
- x.n个关键字本身x.key1,x.key2,……,x.keyx.n,非降序存放,使得x.key1<=x.key2<=...<=x.keyx.n。
- x.leaf,一个布尔值,如果x是叶节点,则为true,如果x是内部节点,则为false。
- 每个内部节点x还包含x.n+1个指向其children的指针x.c1,x.c2,……,x.c(x.n+1)。叶节点没有child。
- 关键字x.keyi对存储在各子树上的关键字范围加以分割,如上面提到。如果ki为任何一个存储在以x.ci为根的子树中的关键字,那么
k1<=x.key1<=k2<=x.key2<=...<=x.keyx.n<=k(x.n+1)
- 每个叶节点具有相同的深度,即树的高度
- 每个节点所包含的关键字个数有上界和下界。用一个被称为B树的最小度数(minimum degree)的固定整数t>=2来表示这些界:
- 除了根节点以外的每个节点必须至少有t-1个关键字,所以内部结点至少会有t个child,如果树非空,根节点至少有一个关键字。
- 每个节点至多包含2t-1个关键字,因此,一个内部结点最多有2t个child,当节点恰好有2t-1个关键字,称之为满(full)节点。
t=2时,B树每个内部结点有2、3、4个child,称之为2-3-4树。
而另外一种B*树,要求每个内节点至少2/3满,而不是像B树一样要求至少半满。
2.2.2 B树的高度
对于一个包含n个关键字(n>=1),最小度数t>=2的B树T,其高度h满足如下规律:
h<=logt(n+1)/2
从这一点也看出当对数的底t越大,h越小,所以这也是B树的查找速度优于红黑树的原因。
2.2.3 B树与磁盘
为了平摊等待移动磁臂的时间,磁盘会一次读取多个数据项。信息被分割成一些在柱面上连续出现的相等大小的位的页面,每次磁盘读写的都是一个或多个磁盘页。信息在大多数的系统中,B树算法的运行时间主要由它所执行的DISK-READ和DISK-WRITE操作的次数决定。在B树中,一个节点的大小通常相当于一个完整的磁盘页。因此,一个B树节点可以拥有的子女数就由磁盘页的大小决定。
下一篇文章,我们会讲B+树和LSM树的概念,未完待续。。。