数据增强之CutMix
CutMix数据增强学习
一、前言
之前有一篇博客学习了mixup数据增强,对于提升模型的性能非常显著。长江后浪推前浪,这一篇CutMix数据增强居然将其推在沙滩上。简单回顾下mixup数据增强:从训练样本中随机抽取两个样本进行简单的随机加权求和,同时样本的标签也对应加权求和,然后预测结果与加权求和之后的标签求损失,在反向求导更新参数。
CutMix的处理方式也比较简单,同样也是对一对图片做操作,简单讲就是随机生成一个裁剪框Box,裁剪掉A图的相应位置,然后用B图片相应位置的ROI放到A图中被裁剪的区域形成新的样本,计算损失时同样采用加权求和的方式进行求解,最后作者对比了mixup、cutout和baseline,数据上看似乎也是小小地吊打的节奏。
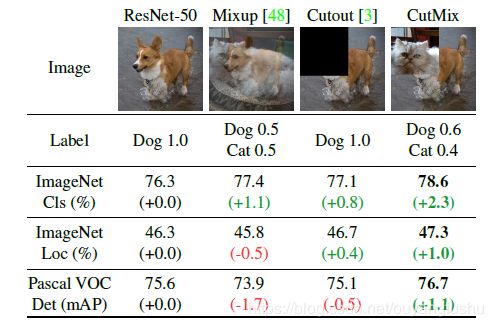
为什么会这样呢,论文的意思我姑且这样描述,mixup是直接求和两张图,如同附身,鬼影一样,模型很难学到准确的特征图响应分布。而cutmix相当于换某个零件,模型更容易区分异类。

二、算法细节
算法的核心过程在论文中这样描述:

M是一个与图像尺寸一致的由0和1标记的掩码矩阵,实际就是标记需要裁剪的区域和保留的区域,裁剪的区域值均为0,其余位置为1,图像A和B组合得到新样本,最后两个图的标签也对应求加权和(其实这个公式想要表达的是再求接损失时,二者的loss求加权和,这样说更准确)。那么问题来了这个裁剪区域的box是如何得到,加权的系数如何确定?

权值同mixup一样是采用bata分布随机得到,alpha的值为论文中取值为1,这样加权系数[0-1]就服从beta分布,实际上从论文的代码实现上看,beta分布真正的用途是为了生成裁剪区域。论文这样描述:

裁剪框box的左上角坐标采集服从宽高(W和H)的均匀分布,及随其采点,box的宽高计算则需要用到beta分布产生的加权系数纳闷哒(懒得打公式了),这样裁剪区box的面积与图像面积之比为1-纳闷哒。这样损失的加权和(公式(1))说采用的纳闷哒就与面积比相对应。这里我对代码进行了简答整理,以便更好地嵌入自己的框架:
def rand_bbox(size, lam):
W = size[2]
H = size[3]
cut_rat = np.sqrt(1. - lam)
cut_w = np.int(W * cut_rat)
cut_h = np.int(H * cut_rat)
# uniform
cx = np.random.randint(W)
cy = np.random.randint(H)
bbx1 = np.clip(cx - cut_w // 2, 0, W)
bby1 = np.clip(cy - cut_h // 2, 0, H)
bbx2 = np.clip(cx + cut_w // 2, 0, W)
bby2 = np.clip(cy + cut_h // 2, 0, H)
return bbx1, bby1, bbx2, bby2
def cutmix_data(x, y, alpha=1., use_cuda=True):
if alpha > 0.:
lam = np.random.beta(alpha, alpha)
else:
lam = 1.
batch_size = x.size()[0]
if use_cuda:
index = torch.randperm(batch_size).cuda()
else:
index = torch.randperm(batch_size)
size=x.size()
bbx1, bby1, bbx2, bby2=rand_bbox(size,lam)
x[:, :, bbx1:bbx2, bby1:bby2] = x[index, :, bbx1:bbx2, bby1:bby2]
# adjust lambda to exactly match pixel ratio
lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (x.size()[-1] *x.size()[-2]))
y_a, y_b = y, y[index]
return x, y_a, y_b, lam
严格的讲,生成的box可能超出图像边界而被裁减,所以再代码中最终的加权系数重新计算了一下:
lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (x.size()[-1] *x.size()[-2]))训练过程完整的使用代码如下:
if mixType=='mixup':
inputs, targets_a, targets_b, lam = mixup_data(inputs, targets, args.alpha, use_cuda)
elif mixType=='cutmix':
inputs, targets_a, targets_b, lam = cutmix_data(inputs, targets, args.alpha, use_cuda)
optimizer.zero_grad()
inputs, targets_a, targets_b = Variable(inputs), Variable(targets_a), Variable(targets_b)
outputs = net(inputs)
loss = criterion(outputs, target_a) * lam + criterion(outputs, target_b) * (1. -lam)我在最近工作中的私有数据集中进行了试验,同样的数据,其他参数一致,仅仅更换mixup为cutmix,模型性能确有提升。对于困难样本的效果有很好的提升。同时心中有一个疑问,如果在mini-batch中随机采样中,样本对组合新数据时,图像A和B在裁剪区域均为背景区域,且背景区域几乎相似,而非目标所在区域,这样训练强制模型拟合,是否合理,还是会引入噪声样?? 求大佬们解答一二。
参考论文:
CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features