李宏毅《深度学习》笔记:Tips for Training DNN 神经网络的训练方法
文章目录
- Recipe of Deep Learning
- New activation function
- Adaptive Learning Rate
- Early Stopping
- Regularization
- L2 regularization
- L1 regularization
- L1 vs L2
- Dropout
Recipe of Deep Learning
训练深度神经网络模型时,我们检测这个模型好不好,每次都需要验证这两步:
- 在training set上的performance是否够好?
- 在testing set上的performance是否够好?

New activation function
如果training结果不好,很有可能是因为network架构设计得不好。举例来说,可能用的activation function是对training不利的,那么就可以尝试着换new activation function,也许可以带来比较好的结果。
Vanishing Gradient Problem:
当network很深,靠近input的参数的gradient(即对最后loss function的微分)是比较小的,而在靠近output的参数对loss的微分值比较大,因此设定同样learning rate的时候,靠近输入层的地方,参数的update是很慢的,而靠近输出层的地方,参数的update是比较快。所以靠近input的参数几乎还处于random,output就已经找到了一个local minima,然后就converge(收敛)了。这个时候参数的loss下降的速度变得很慢,可能会觉得gradient已经接近于0了,于是整个程序停掉了,但model的参数并没有被训练充分,那在training data上得到的结果肯定是很差的。
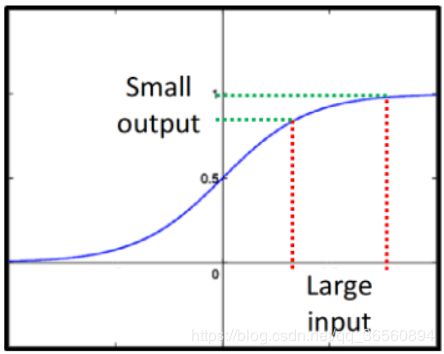
比如Sigmoid function(饱和函数,将较大值和较小值限制在0/1<梯度为0>,如下图)在Deep Network中也会导致梯度消失的问题,神经元的输出每经过sigmoid就会被缩小一次,所以network越深,浅层的输出就被衰减越多次,最后对output的影响就非常小,相应的也导致浅层神经元weight对loss的影响会比较小,于是浅层的gradient远小于靠近输出层的gradient。
如何解决这个问题呢?一开始有个方法是train RBM,idea就是先train第一层layer,训练好之后再train第二层… … 以此类推,这样能缓解Deep Network中的梯度消失问题(这样说明了为什么要使用pre-trained model)。还有一个方法就是:改变activation function。
ReLU:

对于使用ReLU的network,当拿掉某些output为0的linear,那么此时的network就会变成linear network,这样的好处是不会出现类似sigmoid function一样,随着深度增加,浅层神经元对output产生的影响逐层递减,从而缓解梯度消失问题。

Q1:在Deep Network中使用activation function本身就希望其能引入一个non-linear,那ReLU使整个model变成了linear model不是违背了这个初衷吗?
A1:上图只是拿掉了output为0的一部分,对于ReLU本身,它还是一个non-linear function,当input不一样时,其output有可能为0,也有可能直接输出input。
ReLU-variant:

Maxout:
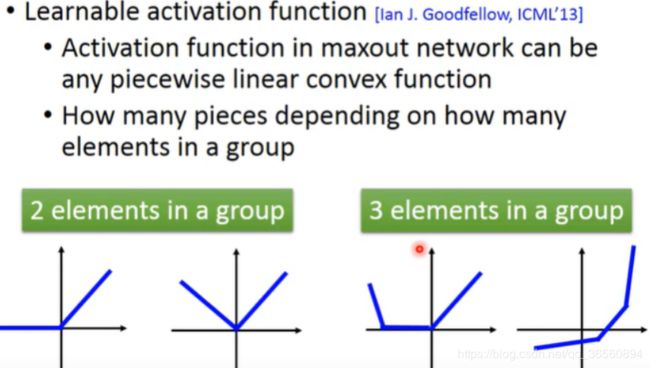
Maxout的idea:让network自动去学习它的activation function,activation function的形式由training data决定。

Maxout可以实现任何piecewise linear convex activation function(分段线性凸激活函数),其中这个activation function被分为多少段,取决于你把多少个element作为一个group。
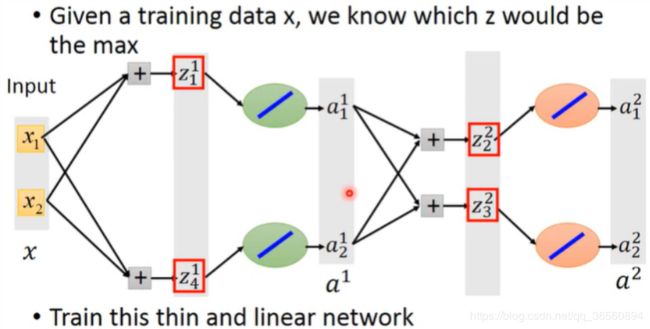
接下来要面临的就是**“Maxout”应该如何训练**?

在具体的实践上,我们完全可以先根据data把max函数转化为某个具体的函数,再对这个转化后的thiner linear network进行微分
Adaptive Learning Rate
这一部分我有一篇专门的博客讲了DNN的各种Optimization方法:https://blog.csdn.net/qq_36560894/article/details/107491363
Early Stopping
在Validation loss最小的时候停止模型的训练,实际上也可以继续训练,保留效果最好的那个model即可。

Regularization
regularization就是在原来的loss function上额外增加几个term
L2 regularization

将推导出的式子与原式比较,参数在每次update之前,都会乘上一个(1-ηλ),而η和λ通常会被设得很小,因此(1-ηλ)通常是一个接近于1的值,所以随着update次数增加,参数w会越来越接近于0,这就叫做Weight Decay(权重衰减)
L1 regularization

如果参数w是正的,sgn是+1,就会变成减一个正值从而使得参数变小;如果w是负的,sgn是-1,就会让参数变大;总之就是让参数w绝对值减小至接近于0。
L1 vs L2
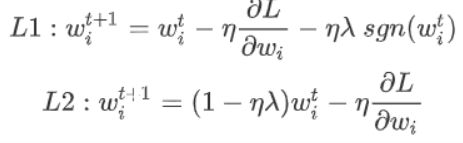
虽然L1、L2regularization都是想让参数的绝对值变小,但它们做的事情其实略有不同:
- L1使参数绝对值变小的方式是每次update减掉一个固定的值
- L2使参数绝对值变小的方式是每次update乘上一个小于1的固定值
因此,当参数w的绝对值比较大的时候,L2会让w下降得更快,而L1每次update只让w减去一个固定的值,最后参数里还是有有很多比较大的值;当参数w的绝对值比较小的时候,L2的下降速度就会变得很慢,train出来的参数平均都是比较小的,而L1每次要减去一个固定值,最后参数是比较稀疏(参数中有很多是接近0的值,也会有很大的值)。所以L1可能会更好一些。
Dropout
之前我也有写过一篇关于Dropout的帖子,里面有探讨了Pytorch里Dropout的实现:https://blog.csdn.net/qq_36560894/article/details/104685895
在训练时,每次更新参数前,每个神经元有p%的几率会被丢掉(跟它相连的weight也都要被丢掉),实际上就是每次更新参数前都通过抽样只保留network中的一部分神经元来做训练

假设在训练的时候,dropout rate是p%,从training data中训练好的所有weight都要乘上(1-p%)才能被当做testing的weight使用:

ensemble v.s. dropout
Dropout可以看成作很多个不同model的ensemble:

举个简单的例子:假设下面这个model中每个神经元的dropout rate为0.5,那么dropout就相当于4个model的ensemble。

当然在深度学习任务中,模型都不是线性的。但模型越接近linear model,dropout的performance就会越好,而使用ReLU或者Maxout的模型相对来说是比较接近于linear model的,所以通常会把含有ReLU或Maxout的模型与Dropout配合使用。