4步获取B站视频
1.进入要下载的视频页面按F12进行检查
谷歌浏览器检查的快捷键是F12,其他浏览器可以右键检查或者审查元素
选择Network下的xhr
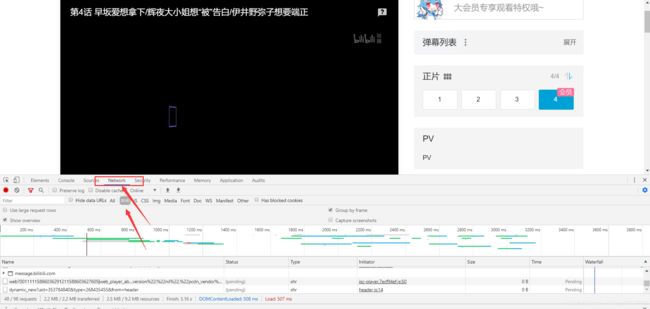
2.观察浏览器向服务器发送的请求
我们看的视频是需要先向服务器进行请求,然后将其缓存到本地进行观看的,所以我们可以获取到B站的视频
B站的视频格式主要是.m4s这种格式音频和视频是分开的分别是一个.m4s所以我们需要观察这些有.m4s后缀的请求,经过观察他们就是两个名称进行多次请求,我们也可以判定其中一个是音频文件另一个是视频文件了。
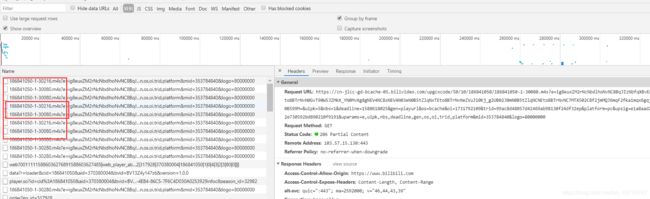
3.获取音视频文件
-
方法一:直接点击该请求,复制右侧的Request URL信息,复制到浏览器地址栏中进行请求,这时它就会自动下载了,不过有的视频这种方式成功了,有的视频出现了403错误,这就需要用方法二了

-
方法二:用python设置请求头进行文件请求,为什么会出现403错误呢?因为哔哩哔哩服务器在收到请求后会对请求头中的信息进行一些验证(比如大会员)。所以解决办法也很简单,加上就行了。
先查看正常观看时的请求是什么样子的,按照方法一中的做法在Request URL下方找到Request Headers

找到这些信息后,就需要写我们的python代码了
先定义两个变量,记录Request URL和 Request Headers,其中Request URL是一个字符串就可以,而Request Headers则按照你浏览器中Request Headers的参数进行填写
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36',
'Accept': '*/*',
'Accept-Encoding': 'identity',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': '',
'Host': '',
'If-Range': '',
'Origin': 'https://www.bilibili.com',
'Range': 'bytes=146320647-146769238',
'Referer': '',
'Sec-Fetch-Dest': '',
'Sec-Fetch-Mode': '',
'Sec-Fetch-Site': ''
}
requestUrl = "Request URL"
# 发送请求(时间会稍长)
resp = requests.get(requestUrl, headers=headers)
headers = resp.headers
# 数据保存
print(resp)
fo = open("video.m4s", "wb")
fo.write(resp.content)
fo.close()
print("结束")
4.处理.m4s文件
我用的是格式工厂然后将其转成了MP4格式(会有两个MP4文件,音频和视频),最后用pr将两个MP4文件合成了一个视频
可能出现的问题
返回了206状态去掉’Range’: ‘bytes=3274663-3531425’ 再进行请求在格式工厂中找不玩.m4s文件选择最下方的all files

可以比较简单的获取B站视频,不过想大批量下载的话这个方法还需要改进的。