构建五种机器学习模型作比较(某金融数据集)
导入各种包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,roc_auc_score,roc_curve,auc
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.linear_model import LogisticRegression
from sklearn import svm
from sklearn.tree import DecisionTreeClassifier
导入数据
data=pd.read_csv('./data.csv',index_col=0,encoding='gbk')
数据理解
#单独提取出y列标签,和其余的88列标记为x
y=data['status']
X=data.drop('status',axis=1)
#X值的行列数,以及y的分布类型
print('X.shape:',X.shape)
print('y的分布:',y.value_counts())
X.shape: (4754, 88)
y的分布: 0 3561
1 1193
Name: status, dtype: int64
数据准备
#首先剔除一些明显无用的特征,如id_name,custid,trade_no,bank_card_no
X.drop(['id_name','custid','trade_no','bank_card_no'],axis=1,inplace=True)
print(X.shape)
#选取数值型特征
X_num=X.select_dtypes('number').copy()
print(X_num.shape)
type(X_num.mean())
#使用均值填充缺失值
X_num.fillna(X_num.mean(),inplace=True)
#观察数值型以外的变量
X_str=X.select_dtypes(exclude='number').copy()
X_str.describe()
#把reg_preference用虚拟变量代替,其它三个变量删除
X_str['reg_preference_for_trad'] = X_str['reg_preference_for_trad'].fillna(X_str['reg_preference_for_trad'].mode()[0])
X_str_dummy = pd.get_dummies(X_str['reg_preference_for_trad'])
X_str_dummy.head()
#合并数值型变量和名义型(字符型)变量
X_cl = pd.concat([X_num,X_str_dummy],axis=1,sort=False)
#X_cl.shape
(4754, 84)
(4754, 80)
数据建模和评估(建立函数和类整合五个模型)
#以三七比例分割训练集和测试集
random_state = 1118
X_train,X_test,y_train,y_test = train_test_split(X_cl,y,test_size=0.3,random_state=1118)
print(X_train.shape)
print(X_test.shape)
#建立xgboost模型
xgboost_model=XGBClassifier()
xgboost_model.fit(X_train,y_train)
"""
#用建立好的xgboost模型运用到训练集和测试集上,进行预测
y_train_pred = xgboost_model.predict(X_train)
y_test_pred = xgboost_model.predict(X_test)
"""
#建立lightgbm模型
lgbm_model=LGBMClassifier()
lgbm_model.fit(X_train,y_train)
"""
#用建立好的lightbm模型运用到训练集和测试集上,进行预测
y_train_pred = lgbm_model.predict(X_train)
y_test_pred = lgbm_model.predict(X_test)
"""
#建立lin_svc模型
Lin_SVC = svm.SVC(probability=True)
Lin_SVC.fit(X_train,y_train)
#建立决策树模型
dt = DecisionTreeClassifier()
dt.fit(X_train, y_train)
#建立逻辑回归模型
lr = LogisticRegression()
lr.fit(X_train, y_train)
#定义一个函数
def model_metrics(clf, X_train, X_test, y_train, y_test):
# 预测
y_train_pred = clf.predict(X_train)
y_test_pred = clf.predict(X_test)
y_train_proba = clf.predict_proba(X_train)[:, 1]
y_test_proba = clf.predict_proba(X_test)[:, 1]
# 准确率
print('[准确率]', end=' ')
print('训练集:', '%.4f' % accuracy_score(y_train, y_train_pred), end=' ')
print('测试集:', '%.4f' % accuracy_score(y_test, y_test_pred))
# 精准率
print('[精准率]', end=' ')
print('训练集:', '%.4f' % precision_score(y_train, y_train_pred), end=' ')
print('测试集:', '%.4f' % precision_score(y_test, y_test_pred))
# 召回率
print('[召回率]', end=' ')
print('训练集:', '%.4f' % recall_score(y_train, y_train_pred), end=' ')
print('测试集:', '%.4f' % recall_score(y_test, y_test_pred))
# f1-score
print('[f1-score]', end=' ')
print('训练集:', '%.4f' % f1_score(y_train, y_train_pred), end=' ')
print('测试集:', '%.4f' % f1_score(y_test, y_test_pred))
# auc取值:用roc_auc_score或auc
print('[auc值]', end=' ')
print('训练集:', '%.4f' % roc_auc_score(y_train, y_train_proba), end=' ')
print('测试集:', '%.4f' % roc_auc_score(y_test, y_test_proba))
# roc曲线
fpr_train, tpr_train, thresholds_train = roc_curve(y_train, y_train_proba, pos_label=1)
fpr_test, tpr_test, thresholds_test = roc_curve(y_test, y_test_proba, pos_label=1)
label = ["Train - AUC:{:.4f}".format(auc(fpr_train, tpr_train)),
"Test - AUC:{:.4f}".format(auc(fpr_test, tpr_test))]
plt.plot(fpr_train, tpr_train)
plt.plot(fpr_test, tpr_test)
plt.plot([0, 1], [0, 1], 'd--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend(label, loc=4)
plt.title("ROC curve")
plt.show()
if __name__ == "__main__":
model_metrics(lr, X_train, X_test, y_train, y_test)
model_metrics(dt, X_train, X_test, y_train, y_test)
model_metrics(Lin_SVC, X_train, X_test, y_train, y_test)
model_metrics(xgboost_model, X_train, X_test, y_train, y_test)
model_metrics(lgbm_model, X_train, X_test, y_train, y_test)
(3327, 85)
(1427, 85)
[准确率] 训练集: 0.7532 测试集: 0.7393
[精准率] 训练集: 0.0000 测试集: 0.0000
[召回率] 训练集: 0.0000 测试集: 0.0000
[f1-score] 训练集: 0.0000 测试集: 0.0000
[auc值] 训练集: 0.5880 测试集: 0.5720
[准确率] 训练集: 1.0000 测试集: 0.6959
[精准率] 训练集: 1.0000 测试集: 0.4139
[召回率] 训练集: 1.0000 测试集: 0.4005
[f1-score] 训练集: 1.0000 测试集: 0.4071
[auc值] 训练集: 1.0000 测试集: 0.6003
[准确率] 训练集: 1.0000 测试集: 0.7393
[精准率] 训练集: 1.0000 测试集: 0.0000
[召回率] 训练集: 1.0000 测试集: 0.0000
[f1-score] 训练集: 1.0000 测试集: 0.0000
[auc值] 训练集: 0.0000 测试集: 0.5000
[准确率] 训练集: 0.8533 测试集: 0.7835
[精准率] 训练集: 0.8447 测试集: 0.6684
[召回率] 训练集: 0.4970 测试集: 0.3360
[f1-score] 训练集: 0.6258 测试集: 0.4472
[auc值] 训练集: 0.9145 测试集: 0.7676
[准确率] 训练集: 0.9973 测试集: 0.7694
[精准率] 训练集: 0.9988 测试集: 0.5931
[召回率] 训练集: 0.9903 测试集: 0.3683
[f1-score] 训练集: 0.9945 测试集: 0.4544
[auc值] 训练集: 0.9999 测试集: 0.7621
下图分别为逻辑回归、决策树、SVM、xgboost、lightgbm的ROC图


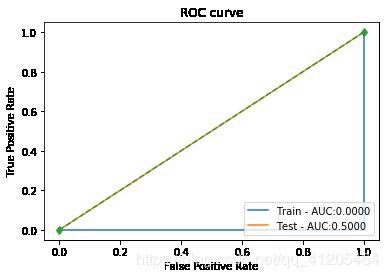
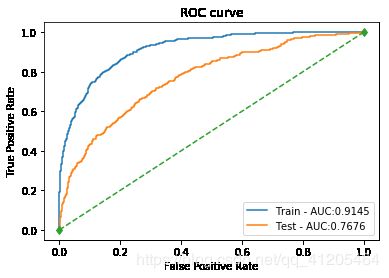
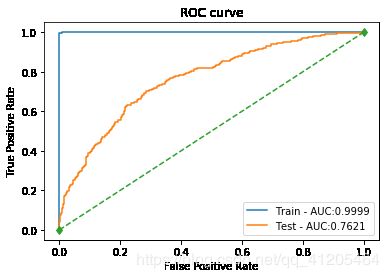
PS:有两个模型结果很奇怪,有待研究