大数据项目之通话记录统计
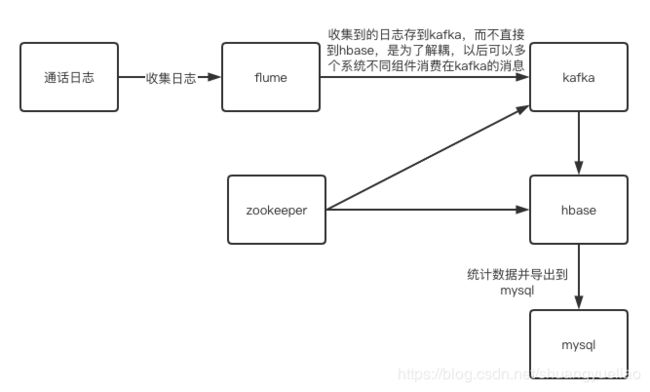
架构图:
第一步:模拟生产数据
public void produce() {
try {
// 读取通讯录数据
List<Contact> contacts = in.read(Contact.class);
while ( flg ) {
// 从通讯录中随机查找2个电话号码(主叫,被叫)
int call1Index = new Random().nextInt(contacts.size());
int call2Index;
while ( true ) {
call2Index = new Random().nextInt(contacts.size());
if ( call1Index != call2Index ) {
break;
}
}
Contact call1 = contacts.get(call1Index);
Contact call2 = contacts.get(call2Index);
// 生成随机的通话时间
String startDate = "20180101000000";
String endDate = "20190101000000";
long startTime = DateUtil.parse(startDate, "yyyyMMddHHmmss").getTime();
long endTime = DateUtil.parse(endDate, "yyyyMMddHHmmss").getTime();
// 通话时间
long calltime = startTime + (long)((endTime - startTime) * Math.random());
// 通话时间字符串
String callTimeString = DateUtil.format(new Date(calltime), "yyyyMMddHHmmss");
// 生成随机的通话时长
String duration = NumberUtil.format(new Random().nextInt(3000), 4);
// 生成通话记录
Calllog log = new Calllog(call1.getTel(), call2.getTel(), callTimeString, duration);
System.out.println(log);
// 将通话记录刷写到数据文件中
out.write(log);
}
} catch ( Exception e ) {
e.printStackTrace();
}
}
数据格式如下
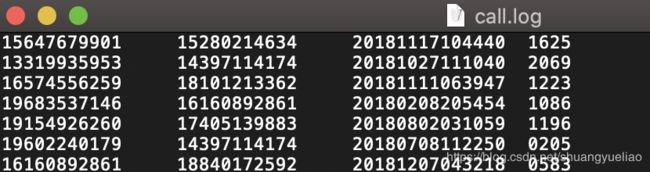
第一列是主叫电话号码,第二列是被叫电话号码,第三列是通话开始时间,第四列是通话时长,单位秒。生成的数据放到一个文件中去。
第二步:flume收集日志并存放至kafka
启动flume来收集日志并发送到kafka(根据自己的安装目录自行修改)
flume-ng agent -c conf/ -n a1 -f conf/flume-2-kafka.conf
flume-2-kafka.conf文件内容如下
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F -c +0 /Users/liangjiepeng/Documents/tmpfile/bigdata/call.log
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = ct
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动kafka(启动参数根据自己配置文件位置自行修改)
kafka-server-start /usr/local/etc/kafka/server.properties
第三步:导入数据到hbase中去
启动hbase
从kafka中导出数据到hbase中去
hbase的表结构如下

public void consume() {
try {
// 创建配置对象
Properties prop = new Properties();
prop.load(Thread.currentThread().getContextClassLoader().getResourceAsStream("consumer.properties"));
// 获取flume采集的数据
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(prop);
// 关注主题
consumer.subscribe(Arrays.asList(Names.TOPIC.getValue()));
// Hbase数据访问对象
HBaseDao dao = new HBaseDao();
// 初始化
dao.init();
int i = 0;
// 消费数据
while ( true ) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(10);
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.value());
// 插入数据
dao.insertData(consumerRecord.value());
//Calllog log = new Calllog(consumerRecord.value());
//dao.insertData(log);
System.out.println(i++);
}
}
} catch ( Exception e ) {
e.printStackTrace();
}
}
为了更快地统计数据,创建了两个列族,分别代表call1是主叫还是被叫。上方produce方法中产生的数据都是放到caller族,而callee族的数据由hbase的协处理器根据放到caller族中的数据生成。
协处理器的postPut方法
public void postPut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability) throws IOException {
// 获取表
Table table = e.getEnvironment().getTable(TableName.valueOf(Names.TABLE.getValue()));
// 主叫用户的rowkey
String rowkey = Bytes.toString(put.getRow());
// 1_133_2019_144_1010_1
String[] values = rowkey.split("_");
CoprocessorDao dao = new CoprocessorDao();
String call1 = values[1];
String call2 = values[3];
String calltime = values[2];
String duration = values[4];
String flg = values[5];
if ( "1".equals(flg) ) {
// 只有主叫用户保存后才需要触发被叫用户的保存
String calleeRowkey = dao.getRegionNum(call2, calltime) + "_" + call2 + "_" + calltime + "_" + call1 + "_" + duration + "_0";
// 保存数据
Put calleePut = new Put(Bytes.toBytes(calleeRowkey));
byte[] calleeFamily = Bytes.toBytes(Names.CF_CALLEE.getValue());
calleePut.addColumn(calleeFamily, Bytes.toBytes("call1"), Bytes.toBytes(call2));
calleePut.addColumn(calleeFamily, Bytes.toBytes("call2"), Bytes.toBytes(call1));
calleePut.addColumn(calleeFamily, Bytes.toBytes("calltime"), Bytes.toBytes(calltime));
calleePut.addColumn(calleeFamily, Bytes.toBytes("duration"), Bytes.toBytes(duration));
calleePut.addColumn(calleeFamily, Bytes.toBytes("flg"), Bytes.toBytes("0"));
table.put( calleePut );
// 关闭表
table.close();
}
}
使用协处理器可能会出现java.lang.OutOfMemoryError: Unable to create new native thread,这时需要增加系统进程可创建线程的最大数或者降低数据put到hbase中的速度。
第四步:分析统计并写入到mysql
目标:统计每个电话号码每天/每月/每年的通话次数和通话总时长,即mysql中一条记录要有电话号码、通话日期、通话次数、通话总时长,因为电话号码和通话日期有很多重复,把电话号码和通话日期作成外键关联到其它表中去。
格式变成如下

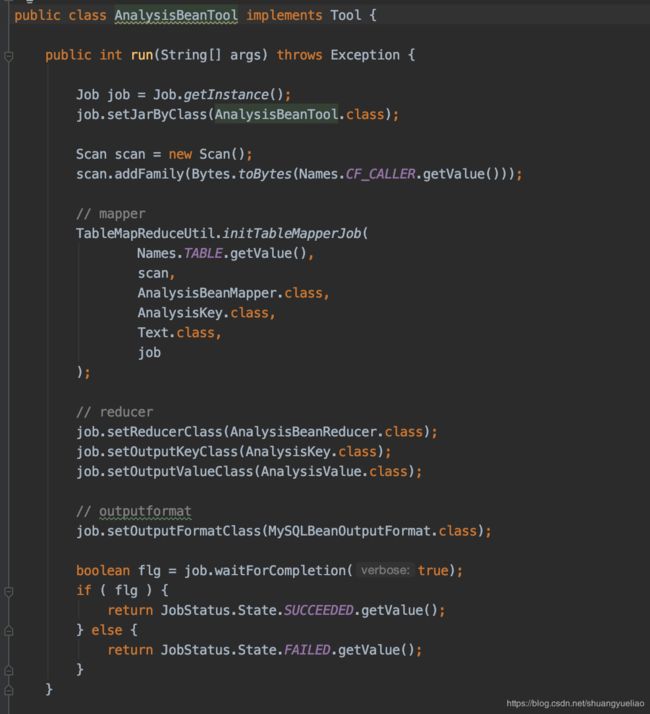
mapper如下
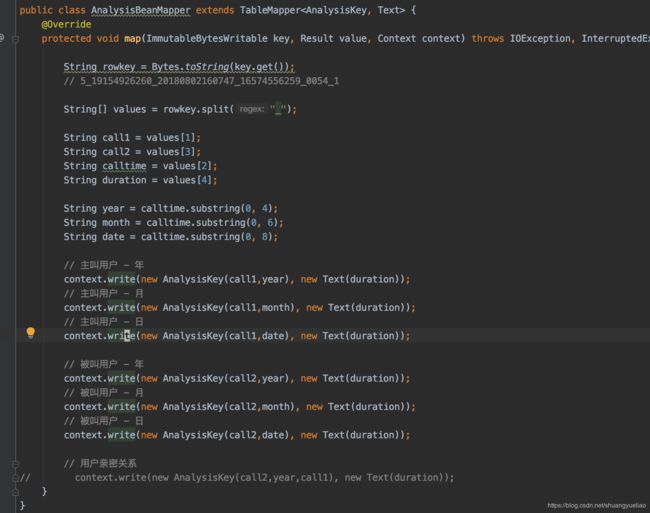
reducer

MySQLBeanOutputFormat的write方法
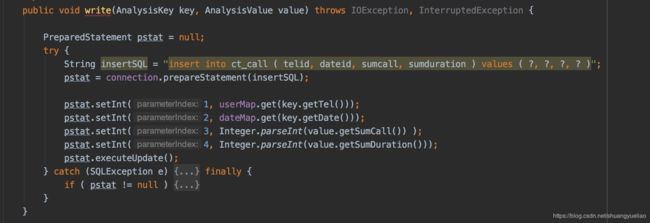
代码链接