PyTorch框架下自定义层和自定义模型
PyTorch是一款简洁且高效的深度学习框架,目前在学术界被广泛使用。
和TensorFlow、Keras等框架一样,PyTorch框架下集成了一些常用的神经网络模型,如卷积神经网络、循环神经网络、全连接神经网络等,我们可以很方便地调用这些模型解决自己的问题。但是,当我们需要尝试用一些新的模型结构来解决自己的问题时,这些框架内置的模型就不行了,这时我们需要自己在PyTorch框架下定义层和模型。本篇博客主要介绍PyTorch框架下如何自定义层和自定义模型,会以具体实例进行详细说明。
写这篇博客参考了:
- pytorch教程之nn.Module类详解——使用Module类来自定义网络层
- pytorch教程之nn.Module类详解——使用Module类来自定义模型
- 《深度学习框架PyTorch入门与实践》
目录
1 自定义层
2 自定义模型
3 实例
1 自定义层
我们首先看一下框架自己定义的层的源码:
1)Linear全连接层
import math
import torch
from torch.nn.parameter import Parameter
from .. import functional as F
from .. import init
from .module import Module
from ..._jit_internal import weak_module, weak_script_method
class Linear(Module):
__constants__ = ['bias']
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
init.uniform_(self.bias, -bound, bound)
@weak_script_method
def forward(self, input):
return F.linear(input, self.weight, self.bias)
def extra_repr(self):
return 'in_features={}, out_features={}, bias={}'.format(
self.in_features, self.out_features, self.bias is not None
)2)Conv2d卷积层
class Conv2d(_ConvNd):
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, groups=1,
bias=True, padding_mode='zeros'):
kernel_size = _pair(kernel_size)
stride = _pair(stride)
padding = _pair(padding)
dilation = _pair(dilation)
super(Conv2d, self).__init__(
in_channels, out_channels, kernel_size, stride, padding, dilation,
False, _pair(0), groups, bias, padding_mode)
@weak_script_method
def forward(self, input):
if self.padding_mode == 'circular':
expanded_padding = ((self.padding[1] + 1) // 2, self.padding[1] // 2,
(self.padding[0] + 1) // 2, self.padding[0] // 2)
return F.conv2d(F.pad(input, expanded_padding, mode='circular'),
self.weight, self.bias, self.stride,
_pair(0), self.dilation, self.groups)
return F.conv2d(input, self.weight, self.bias, self.stride,
self.padding, self.dilation, self.groups)我们可以看到这两个层的源码的公共部分:__init__()函数和forward()函数,其中 __init__()函数被称为构造函数,主要用于定义参数,我们一般把具有可学习参数的层都放在__init__()函数,forward函数是层的前向传播函数,表示的是层的前向传播逻辑,注意forward()函数定义的是批数据的前向传播逻辑。
要实现一个自定义层,需要:
1)自定义一个类,该类继承自nn.Module类,并且一定要实现两个基本的函数:构造函数__init__()、层的逻辑运算函数forward();
2)在构造函数__init__()中实现层的参数定义;
3)在前向传播forward函数中实现批数据的前向传播逻辑,只要在nn.Module的子类中定义了forward()函数,backward()函数就会被自动实现。
注意:一般情况下我们定义的参数是可导的,但是如果自定义操作不可导,就需要我们手动实现backward()函数。
现在我们要自定义层实现这样一个功能:输入为两个 维向量
维向量![]() 和
和 ,参数为一个
,参数为一个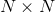 的矩阵
的矩阵 ,输出为
,输出为![]() 。自定义层的代码如下:
。自定义层的代码如下:
import torch
import torch.nn as nn
import numpy as np
from torch.autograd import Variable
import math
from torch import optim
import torch.utils.data as Data
# 定义DisMult层
class DisMult(nn.Module):
def __init__(self, emb_size):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
# 下式等价于nn.Module.__init__(self)
super(DisMult, self).__init__()
# 隐特征维度
self.emb_size = emb_size
# 关系特定的方阵
# self.weights = nn.Parameter(torch.Tensor(emb_size, emb_size), requires_grad=requires_grad)
self.weights = nn.Parameter(torch.Tensor(emb_size, emb_size))
# 初始化参数
self.reset_parameters()
# 初始化参数
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weights.size(0))
self.weights.data.uniform_(-stdv, stdv)
# 前向传播函数
def forward(self, input1, input2):
# 前向传播的逻辑
result = torch.sum((input1 @ self.weights) * input2, dim=1)
return torch.sigmoid(result)2 自定义模型
对于多输入多输出模型、多分支模型、跨层连接模型等复杂模型,需要我们自己定义模型。PyTorch中的Layer和Module没有明显的区别,不管是自定义层、自定义块,还是自定义模型,都是通过继承Module类完成的,PyTorch中的一切自定义操作基本上都是通过继承nn.Module类来实现的。
和自定义层类似,我们在定义自己的模型时,需要继承nn.Module类,并重新实现构造函数__init__()和前向传播函数forward(),但要注意:
1)一般把网络中具有可学习参数的层放在构造函数__init()中,当然也可以把不具有可学习参数的层放在里面;
2)如果不把不具有可学习参数的层放在构造函数__init()中,则在forward()函数中使用nn.functional代替。
3)forward()方法必须要重写,它是实现模型的功能、实现各个层之间逻辑的核心。
现在我们的模型只包含上述一个自定义层,模型定义如下:
import torch
import torch.nn as nn
import numpy as np
from torch.autograd import Variable
import math
from torch import optim
import torch.utils.data as Data
# 定义DisMult模型
class DisMultModel(nn.Module):
def __init__(self, hidden_dim):
super(DisMultModel, self).__init__()
self.hidden_dim = hidden_dim
# 模型中加入一层DisMult层
self.dismult = DisMult(hidden_dim)
def forward(self, x_a, x_b):
return self.dismult(x_a, x_b)3 实例
我们使用仿真数据来训练上述的自定义模型,完整代码如下:
#-*-coding:utf-8-*-
"""
@author:taoshouzheng
@time:2019/7/1 10:37
@email:[email protected]
"""
import torch
import torch.nn as nn
import numpy as np
from torch.autograd import Variable
import math
from torch import optim
import torch.utils.data as Data
# 定义DisMult层
class DisMult(nn.Module):
def __init__(self, emb_size):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
# 下式等价于nn.Module.__init__(self)
super(DisMult, self).__init__()
# 隐特征维度
self.emb_size = emb_size
# 关系特定的方阵
# self.weights = nn.Parameter(torch.Tensor(emb_size, emb_size), requires_grad=requires_grad)
self.weights = nn.Parameter(torch.Tensor(emb_size, emb_size))
# 初始化参数
self.reset_parameters()
# 初始化参数
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weights.size(0))
self.weights.data.uniform_(-stdv, stdv)
# 前向传播函数:注意这里定义的是批的处理逻辑
def forward(self, input1, input2):
result = []
for i in range(input1.size(0)):
result_i = input1[i] @ self.weights @ (input2[i].t())
result.append(result_i)
return torch.sigmoid(torch.DoubleTensor(result))
# 定义DisMult模型
class DisMultModel(nn.Module):
def __init__(self, hidden_dim):
super(DisMultModel, self).__init__()
self.hidden_dim = hidden_dim
# 模型中加入一层DisMult层
self.dismult = DisMult(hidden_dim)
def forward(self, x_a, x_b):
return self.dismult(x_a, x_b)
# 定义网络
model = DisMultModel(hidden_dim=50)
# 打印初始化参数
for item in model.named_parameters():
print(item)
# 定义损失函数和优化器
criterion = nn.BCELoss(reduction='sum') # 二分类交叉熵损失函数
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) # 优化器
# 训练网络:输入数据、前向传播 + 反向传播、更新参数
# 超参数
EPOCH = 100 # 迭代轮数
BATCH_SIZE = 100 # 批大小
input_a = []
input_b = []
label = []
with open(r'E:\Experiment\数据预处理\仿真数据\relation_1_train.csv', 'r', encoding='utf8') as f:
contents = f.readlines()
for content in contents:
content = content.strip().split('\t')
# inputs.append([content[0].strip().split(' '), content[1].strip().split(' ')])
input_a.append(content[0].strip().split(' '))
input_b.append(content[1].strip().split(' '))
label.append(content[2])
# numpy数组
inputs = np.array([input_a, input_b], dtype=np.float) # 实数类型
label = np.array(label, dtype=np.long)
# Tensor
inputs = torch.FloatTensor(inputs)
label = torch.DoubleTensor(label)
# 先转化成torch能识别的Dataset
torch_dataset = Data.TensorDataset(inputs[0], inputs[1], label)
# dataset放到DataLoader中
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True)
# 训练
for epoch in range(EPOCH):
# 每一步loader释放一小批数据用于训练
for step, (batch_inputs_1, batch_inputs_2, batch_label) in enumerate(loader):
# 输入数据
input_1 = Variable(batch_inputs_1)
input_2 = Variable(batch_inputs_2)
label = Variable(batch_label)
# 梯度清零
optimizer.zero_grad()
# 前向传播 + 反向传播
output = model(input_1, input_2) # 计算输出
loss = criterion(output, label) # 计算损失函数
loss.requires_grad = True
print('Epoch', epoch + 1, 'Step', step + 1, ':', loss.item())
loss.backward() # 反向传播
# 更新参数
optimizer.step()
# 打印训练后的参数
for item in model.named_parameters():
print(item)
结果:
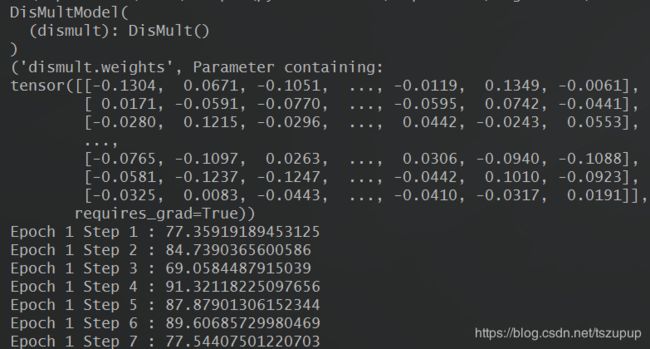
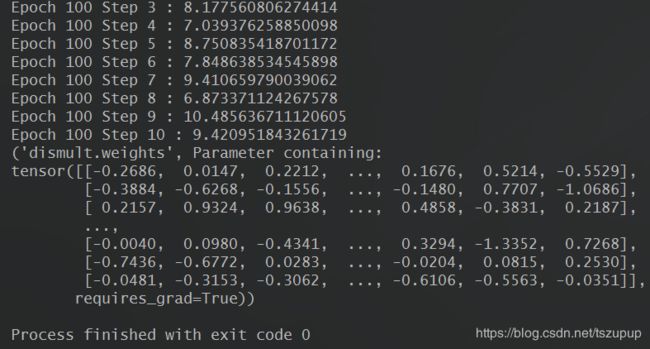
可以看到,虽然训练时使用的是仿真的数据,但是在训练过程中,模型的损失值明显下降,对应的模型参数也明显改变。
最近在学习pytorch框架,可以加QQ3408649893交流。