java微信公众平台开发实战(一)——图书馆微信查书助手
项目下载地址:http://download.csdn.net/detail/u010182075/7836241
一、项目的功能:
1、用户订阅时推送文本消息“感谢您的关注!”;
2、用户输入“help”或者“?”时回复帮助信息;
3、对于用户输入的其他文本信息,将其视作书名关键词,并访问清华大学图书馆进行书籍查询。如果查询结果大于8条,则取前8条,返回图文消息;如果查询结果小于8条,则返回全部查询结果;如果没有查到,则返回文本消息。
二、项目依赖的第三方jar包:(已经打包在项目中,不需要自己去下载)
1、easywechat:用于与微信后台的交互。
2、jsoup:用于图书馆查询接口的访问和html页面解析。
三、开发过程详解:
大致分为三个部分:获取书籍查询接口;接口访问与网页解析;微信相关部分。
1、通过抓包获得图书馆书籍查询接口:(以清华大学为例)
打开谷歌浏览器,访问清华大学图书馆。
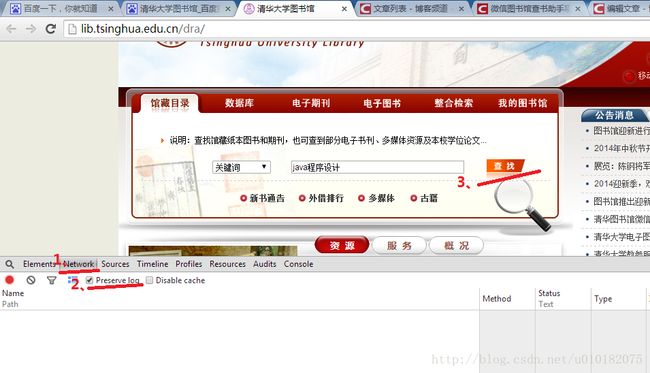
按“F12”进入开发者工具栏,选择“Network”进行抓包。注意勾选“Preserve log”,以防页面跳转时丢失抓到的数据包。
然后从网页上输入查询关键词,例如“java程序设计”,点击“查找”。
这时,谷歌浏览器下方的开发者工具栏中的显示内容大致如下:
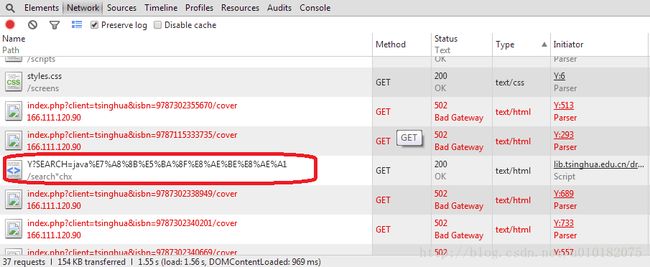
点击“Type”(上图右上角)会按照类型排序,我们只关注类型为“text/html”的请求。上图红框内就是我们要找的,点进去查看请求信息。
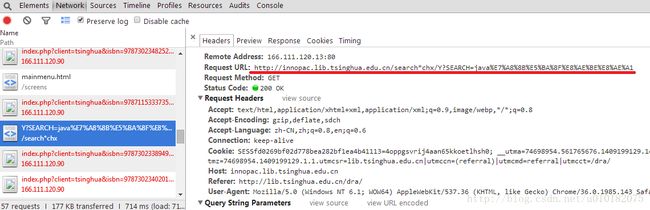
请求信息如上图。上图红线标出了请求地址,这正是我们要找的,其余信息目前可以忽略。我们可以看出请求参数只有一个"SEARCH",参数的值就是书籍查询的关键词。参数值采用了utf-8编码,我们可以通过查看网页源代码来找到编码方式。至此,项目的第一部分也就完成了。
2、使用jsoup访问网络接口并解析网页代码:
示例代码如下:
String bookName = "代码整洁之道";
String url = HOST + "/search*chx/Y?SEARCH="
+ URLEncoder.encode(bookName, "utf-8");
Document document = Jsoup.connect(url).get();
Elements eles = document.select(".briefcitTitle a");
for (int i = 0; i < eles.size() && i < 8; i++) {
Element ele = eles.get(i);
//从页面中解析出书名和书的链接
String link = host + ele.attr("href");// 书的链接
String bookName = ele.text();// 书名
//...
}3、完成微信模块:
@WebServlet("/coreServlet")
public class Wechat extends SimpleWeixinSupport {
@Override
protected String getToken() {
// 返回你在微信公众平台设置的token
return "out";
}
// onText方法响应用户发送的文本消息
@Override
protected BaseMsg onText(String content) {
if (content.equalsIgnoreCase("help") || content.equals("?")) {
// 如果用户输入"help"或者"?"
// 则发送文本消息"输入书名查询书籍!"
return MessageFactory.createTextMsg("输入书名查询书籍!");
} else {
// 如果用户输入其他文本,则去查询书籍,并返回图文消息
try {
return Crawler.findBookByKeyWord(content);
} catch (IOException e) {
e.printStackTrace();
// 如果出现IO错误,则返回null
// 返回null表示不响应用户
return null;
}
}
}
// handleSubscribe方法如理用户订阅事件
@Override
protected BaseMsg handleSubscribe(BaseEvent event) {
// 在用户首次关注微信号时,发送文本消息“感谢您的关注!”
return MessageFactory.createTextMsg("感谢您的关注!");
}
}