数据分析之绘制边界以及np.c_和np.r_用法
这里记录一下绘制分类边界的方法。记录一下meshgrid,pcolormesh的使用方法
import numpy as np
# 抓取数据
iris = datasets.load_iris()
x = iris.data[:, 1:3]
y = iris.target[:]
k = 15 # 设置KNN k=15,计算周围临近的15个点
# 图片,x,y每一步的步长
h = 0.02
# 颜色分类
cmap_light = ListedColormap(["#FFAAAA", "#AAFFAA", "#AAAAFF"])
cmap_bold = ListedColormap(["#FF0000", "#00FF00", "#0000FF"])
model = KNeighborsClassifier(n_neighbors=15) # 设置访问周围15个点
model.fit(x, y) # 自适应, 训练数据
# 四个数描述图片显示范围
xmin, xmax = x[:, 0].min() , x[:, 0].max()
ymin, ymax = x[:, 1].min() , x[:, 1].max()
# 生成网格
xx, yy = np.meshgrid(np.arange(xmin, xmax, h),np.arange(ymin, ymax, h))
# 预测
# np.c_是按照列合并,列数相等,np.r_按照行合并,行数相等
z = model.predict(np.c_[xx.ravel(), yy.ravel()])
z = z.reshape(xx.shape)
# 显示背景颜色
plt.pcolormesh(xx, yy, z, cmap=cmap_light)
# 显示点
plt.scatter(x[:,0], x[:,1], c=y, cmap=cmap_bold)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title(u"分类")
plt.show()
对于代码中的np.c_,其并不是一个方法,更像是一个数组元素的访问方式,因为其使用[],而不是()。
import numpy as np
a = np.array([1,2,3])
b = np.array([4,5,6])
print(a)
print(np.c_[a, b])

这里可以看到,反悔了一个新数组,并且将两个数组中的元素通过列合并。

同上,np.r_则在行上合并,

这里从两行数据,变成了四行数据。
总结:
np.r_是按行连接两个矩阵,就是把两矩阵上下相加,要求列数相等=>因为是在行合并,所以列数相等

这里列数不相等就直接报错。

np.c_是按列连接两个矩阵,就是把两矩阵左右相加,要求行数相等
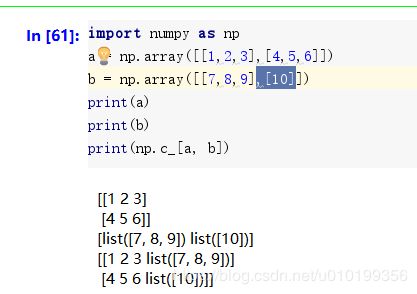
这里行数不相等的话就直接报错。