使用c++和cuda写深度学习框架:Grape简介
前言
看过我之前的博客就知道,我曾经用java写了一个深度神经网络[CupDnn](https://github.com/sunnythree/CupDnn),但是,java写的深度神经网络真的非常慢。由于这个原因,我打算使用c++和cuda重写一个深度学习框架。有了写CupDnn的经验,结合最近阅读darknet、caffe、tiny_dnn源码的心得,新写的[Grape](https://github.com/sunnythree/Grape)会有一些优点:
- 无任何依赖
- 支持 json/xml/binary参数保存
- 通过json构建计算图
- c++ and cuda 非常快
此外,基于gtest的单元测试是代码质量的有力保障。
Grape大量使用darknet的代码,也使用了部分caffe和tiny_dnn的代码,非常感谢这些开源工程的帮助。但是呢,相比于caffe,Grape没有依赖多,安装麻烦的问题,相比darknet而言,c++面向对象组织的代码对习惯了面向对象设计的程序员而言更加容易接受,相比于tiny_dnn,Grape对cuda的支持更好。
Grape目前还处于婴幼儿时期,它的代码很少,很容易学习。Mnist的例子会让你轻易上手,全连接在Mnist上能轻易超过98%,卷积神经网络在mnist能轻易超过99%(gpu和cpu都已测试)。
整体设计
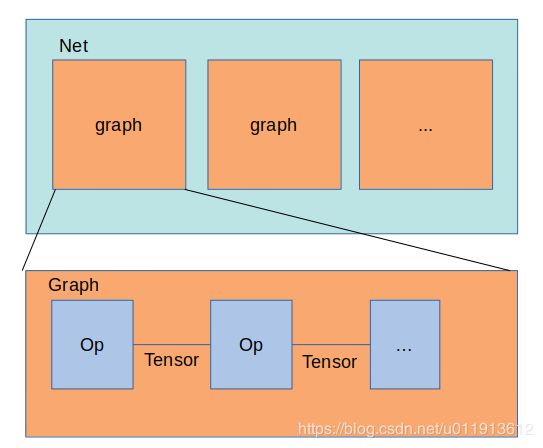
Net
整个神经网络由一个Net进行组织。net中可以有多个计算图。mnist的例子中,一个Net都有两个计算图,一个用来训练,一个用来测试,它们可以交替执行,这样就实现了训练一会后进行测试的目的。
Graph
计算图由Op和Tensor组成,Tensor同时包含了synced_memory来存储数据。synced_memory设计非常巧妙,它可以让你不用担心cpu和gpu之间的数据同步问题,当地读cpu数据,数据可能会自动从gpu同步到cpu,反之亦然。Op则是一些操作,比如Conv2d,Fc,PoolMax等。
Op和Tensor的关系
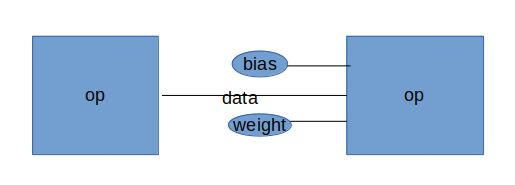
data是连接两个op的tensor,bias和weight只连接了一个op,它们是这个op的偏置和权重。也就是说Tensor既有连接的功能,也有保存数据的功能。
使用json构建神经网络
已最简单的全连接为例,你需要连个文件,一个定义op,一个定义Net和Graph以及Graph使用优化器等。
定义Op
{
"ops": {
"op_list": [
{
"name": "train_data",
"type": "MnistData",
"batch": 20,
"data_path": "data/mnist/train-images-idx3-ubyte",
"label_path": "data/mnist/train-labels-idx1-ubyte",
"sample_count":50000,
"random": false
},
{
"name": "test_data",
"type": "MnistData",
"batch": 20,
"data_path": "data/mnist/t10k-images-idx3-ubyte",
"label_path": "data/mnist/t10k-labels-idx1-ubyte",
"sample_count":10000,
"random": false
},
{
"name": "fc0",
"type": "Fc",
"batch": 20,
"in_dim": 784,
"out_dim": 100,
"has_bias": true,
"activation":"leaky"
},
{
"name": "fc1",
"type": "Fc",
"batch": 20,
"in_dim": 100,
"out_dim": 30,
"has_bias": true,
"activation":"leaky"
},
{
"name": "fc2",
"type": "Fc",
"batch": 20,
"in_dim": 30,
"out_dim": 10,
"has_bias": true,
"activation":"leaky"
},
{
"name": "softmax_loss",
"type": "SoftmaxWithLoss",
"batch": 20,
"in_dim": 10
},
{
"name": "softmax",
"type": "Softmax",
"batch": 20,
"in_dim": 10
},
{
"name": "accuracy_test",
"type": "AccuracyTest",
"batch": 20,
"in_dim": 10
}
]
}
}
定义Net和计算图
{
"op_paths": {
"path_list": [
{
"name": "mnist_op",
"path": "cfg/mnist/mnist_op.json"
}
]
},
"connections": {
"connection_list": [
{
"op_list_name": "mnist_op",
"graph_name": "graph_mnist_train",
"cnnections": [
{
"from": "train_data:0",
"to": "fc0:0"
},
{
"from": "fc0:0",
"to": "fc1:0"
},
{
"from": "fc1:0",
"to": "fc2:0"
},
{
"from": "fc2:0",
"to": "softmax_loss:0"
},
{
"from": "train_data:1",
"to": "softmax_loss:1"
}
]
},
{
"op_list_name": "mnist_op",
"graph_name": "graph_mnist_test",
"cnnections": [
{
"from": "test_data:0",
"to": "fc0:0"
},
{
"from": "fc0:0",
"to": "fc1:0"
},
{
"from": "fc1:0",
"to": "fc2:0"
},
{
"from": "fc2:0",
"to": "softmax:0"
},
{
"from": "softmax:0",
"to": "accuracy_test:0"
},
{
"from": "test_data:1",
"to": "accuracy_test:1"
}
]
}
]
},
"optimizers": {
"optimizer_list": [
{
"graph_name":"graph_mnist_train",
"type": "sgd",
"lr": 0.01,
"momentum":0.9,
"policy":"step",
"step":10000,
"gamma":0.8
}
]
},
"graphs": {
"graph_list": [
{
"name": "graph_mnist_train",
"max_iter": 2500,
"cal_mode": "gpu",
"phase": "train",
"device_id": 0,
"serialize_type":"json",
"save_path": "model/mnist_model",
"display_iter":500,
"snapshot_iter":1000
},
{
"name": "graph_mnist_test",
"max_iter": 500,
"cal_mode": "gpu",
"serialize_type":"json",
"phase": "test",
"device_id": 0,
"save_path": "model/mnist_model",
"display_iter":500
}
]
},
"net": {
"max_iter": 30
}
}
这里定义了两个计算图,一个用来训练,一个用来测试。
定义一个神经网络的步骤如下:
- 定义Op
- 连接Op,将op的连接关系写入"connections"中。
- 定义计算图和优化器
- 定义Net
Graph会自动添加到Net中,优化器、计算图、连接都是通过名字进行关联的。
我很遗憾的是,json定义计算图依然比较繁琐。
总结
Grape才刚刚起步,有很多问题,有很多不足,希望有同道中人一起开发。
不足之处有很多,比如说:
- json定义神经网络有点繁琐
- op的接口还不太友好
- 支持的Op还很少
- 一机多卡还未支持。理论上,可以通过创建多个计算图,不同计算图执行在不同gpu上,然后由其中一个计算图讲计算结果汇总的方式时间一机多卡。但遗憾的是,我没有测试的条件,我没有一机多卡的条件。
- 分布式训练还未支持。还没有想清楚要怎样支持分布式训练比较好,这部分工作量也很大。
交流
QQ group: 704153141
Email: [email protected]