Sqoop2的安装与使用
安装篇
Sqoop由两部分组成:客户端(client)和服务端(server)。需要在集群的其中某个节点上安装server,该节点的服务端可以作为其他Sqoop客户端的入口点。在服务端的节点上必须安装有Hadoop。客户端可以安装在任意数量的机子上。在装有客户端的机子上不需要安装Hadoop。
服务端安装
# 将Sqoop分布式tar包解压到任意的目录。我们将它加压到/opt目录下。 tar -zxvf sqoop-1.99.6-bin-hadoop200.tar.gz -C /opt # 进入/opt目录 cd /opt # 名字太长,重命名下 mv sqoop-1.99.6-bin-hadoop200 sqoop-1.99.6
安装依赖
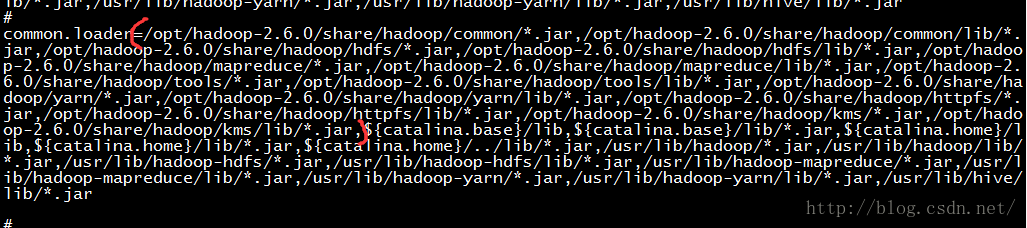
在目录server/conf下的catalina.properties文件中配置Hadoop 库的路径。需要改变common.loader这个参数来包含Hadoop 库的所有目录。
根据hadoop的安装路径,在中common.loader添加如下的库:
/opt/hadoop-2.6.0/share/hadoop/common/*.jar,/opt/hadoop-2.6.0/share/hadoop/common/lib/*.jar,/opt/hadoop-2.6.0/share/hadoop/hdfs/*.jar,/opt/hadoop-2.6.0/share/hadoop/hdfs/lib/*.jar,/opt/hadoop-2.6.0/share/hadoop/mapreduce/*.jar,/opt/hadoop-2.6.0/share/hadoop/mapreduce/lib/*.jar,/opt/hadoop-2.6.0/share/hadoop/tools/*.jar,/opt/hadoop-2.6.0/share/hadoop/tools/lib/*.jar,/opt/hadoop-2.6.0/share/hadoop/yarn/*.jar,/opt/hadoop-2.6.0/share/hadoop/yarn/lib/*.jar,/opt/hadoop-2.6.0/share/hadoop/httpfs/*.jar,/opt/hadoop-2.6.0/share/hadoop/httpfs/lib/*.jar,/opt/hadoop-2.6.0/share/hadoop/kms/*.jar,/opt/hadoop-2.6.0/share/hadoop/kms/lib/*.jar,
如下图:
最后,需要安装JDBC驱动,将JDBC驱动放入server/lib/目录下。我们使用的是mysql,所以将下载好的mysql驱动放入到该目录下即可。
如下图:

配置PATH
建议在/etc/profile目录中增加以下环境变量以及修改$PATH,以方便使用,如下图:

配置服务端
在启动服务之前,需要检测配置文件是否与你的环境相匹配。服务端的配置文件存放在 server/config目录下。你可能需要将 sqoop.properties文件中的 org.apache.sqoop.submission.engine.mapreduce.configuration.directory这个属性设置成当前安装的Hadoop的配置文件所在的目录。
yarn.log-aggregation-enable true
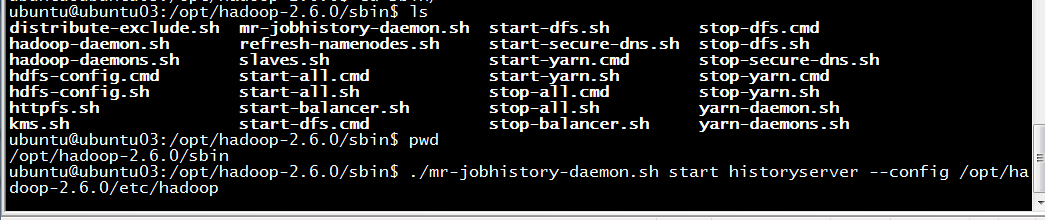
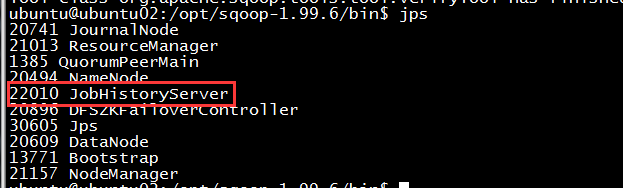
# /opt/hadoop-2.6.0/etc/hadoop 是我的hadoop存放配置文件的目录 ./mr-jobhistory-daemon.sh start historyserver --config /opt/hadoop-2.6.0/etc/hadoop
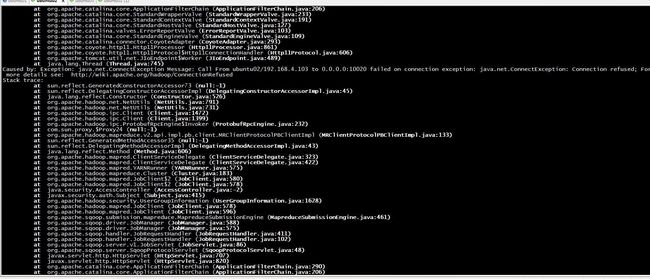
客户端不需要额外的安装和配置步骤。只需要将Sqoop的包放到目标节点上,并且解压到某个目录即可使用 。
使用篇
服务端的启动
可以直接使用以下命令启动服务。
sqoop2-server start
客户端的启动
sqoop2-shell
sqoop:000> set option --name verbose --value true
连接Sqoop服务端:
#我们的服务端安装在ubuntu02这个节点上所以--host是ubuntu02
sqoop:000> set server --host ubuntu02
### 使用上面自动连接即可。(set server --host ubuntu02 --port 12000 --webapp sqoop)
验证是否已经连上
sqoop:000> show version --all
client version:
Sqoop 2.0.0-SNAPSHOT source revision 418c5f637c3f09b94ea7fc3b0a4610831373a25f
Compiled by vbasavaraj on Mon Nov 3 08:18:21 PST 2014
server version:
Sqoop 2.0.0-SNAPSHOT source revision 418c5f637c3f09b94ea7fc3b0a4610831373a25f
Compiled by vbasavaraj on Mon Nov 3 08:18:21 PST 2014
API versions:
[v1]
如果打印出类似上面的形式,表示已经连上了。
可以使用help命令来检查sqoop shell所支持的命令:
sqoop:000> help
For information about Sqoop, visit: http://sqoop.apache.org/
Available commands:
exit (\x ) Exit the shell
history (\H ) Display, manage and recall edit-line history
help (\h ) Display this help message
set (\st ) Configure various client options and settings
show (\sh ) Display various objects and configuration options
create (\cr ) Create new object in Sqoop repository
delete (\d ) Delete existing object in Sqoop repository
update (\up ) Update objects in Sqoop repository
clone (\cl ) Create new object based on existing one
start (\sta) Start job
stop (\stp) Stop job
status (\stu) Display status of a job
enable (\en ) Enable object in Sqoop repository
disable (\di ) Disable object in Sqoop repository
创建Link对象
检查Sqoop服务(server)已经注册的 connectors:

我们例子中的Generic JDBC Connector 有一个永久不变的 Id 4 ,我们会利用这个值来为connector创建新的link对象,下面创建的是连接JDBC的link:
sqoop:000> create link -c 4 #注意:这边的4是connector的id,表明创建的是一个generic jdbc connector
Creating link for connector with id 2
Please fill following values to create new link object
Name: mysql-link #注意:Name是唯一的
Link configuration
JDBC Driver Class: com.mysql.jdbc.Driver
JDBC Connection String: jdbc:mysql://ubuntu02:3306/mytest #注意:jdbc:mysql://主机名(ip):端口/数据库名
Username: root
Password: ******
JDBC Connection Properties:
There are currently 0 values in the map:
entry#protocol=tcp
New link was successfully created with validation status OK and persistent id 3
上面,我们成功创建了一个id为3的link。
使用 show connector -all 我们还可以看到一个 hdfs-connector ,它的id是4。接下来我们为hdfs connector创建一个link:
sqoop:000> create link -c 3
Creating link for connector with id 1
Please fill following values to create new link object
Name: hdfs-link
Link configuration
HDFS URI: hdfs://ns1/ #注意,ns1是逻辑命名空间,我使用了两个namenode,也许你的hdfs的URI是这样的形式 hdfs://nameservice1:8020/
Hadoop conf directory:/opt/hadoop-2.6.0/etc/hadoop #Hadoop配置文件的目录
New link was successfully created with validation status OK and persistent id 4
创建Job对象
Connectors 的From 用于读取数据,To用于写入数据。使用上面的show connector -all命令可以显示出Generic JDBC Connector对From和To都是支持的。也就是说我们既可以从数据库中读取数据,也可以往数据库中写入数据。为了创建一个Job,我们需要指定Job的From和To部分,From和To部分可以使用link Id 来表示。
sqoop:000> show link --all
2 link(s) to show:
link with id 3 and name mysql-link (Enabled: true, Created by ubuntu at 7/14/15 3:58 PM, Updated by ubuntu at 7/14/15 3:58 PM)
Using Connector generic-jdbc-connector with id 4
Link configuration
JDBC Driver Class: com.mysql.jdbc.Driver
JDBC Connection String: jdbc:mysql://ubuntu02:3306/mytest
Username: root
Password:
JDBC Connection Properties:
protocol = tcp
link with id 4 and name hdfs-link (Enabled: true, Created by ubuntu at 7/14/15 4:09 PM, Updated by ubuntu at 7/14/15 4:09 PM)
Using Connector hdfs-connector with id 3
Link configuration
HDFS URI: hdfs://ns1/
Hadoop conf directory: /opt/hadoop-2.6.0/etc/hadoop
接下来,我们可以使用这两个link Id来关联job的From和To部分。说的通俗一点,就是我们需要从哪里(From)读取数据,把这些数据导入(To)到哪里?
sqoop:000> create job -f 3 -t 4
Creating job for links with from id 3 and to id 4
Please fill following values to create new job object
Name: testsqoop #Name必须唯一
From database configuration
Schema name: mytest #必填,数据库名称
Table name: balance #必填,表名
Table SQL statement: #可选
Table column names: #可选
Partition column name: #可选
Null value allowed for the partition column: #可选
Boundary query: #可选
Incremental read
Check column: #可选
Last value: #可选
To HDFS configuration
Override null value: #可选
Null value:
Output format:
0 : TEXT_FILE
1 : SEQUENCE_FILE
Choose: 0 #必选
Compression format:
0 : NONE
1 : DEFAULT
2 : DEFLATE
3 : GZIP
4 : BZIP2
5 : LZO
6 : LZ4
7 : SNAPPY
8 : CUSTOM
Choose: 0 #必选
Custom compression format:
Output directory: /user/ubuntu/lucius/new_balance #必填
Append mode:
Throttling resources
Extractors: 2 #可选,对应mapreduce的job中的map的数量
Loaders: 1 #可选,对应mapreduce的job中的reduce的数量
New job was successfully created with validation status OK and persistent id 5
这样就建立了一个新的job,他的id是5
启动job
可以使用以下命令来执行job:
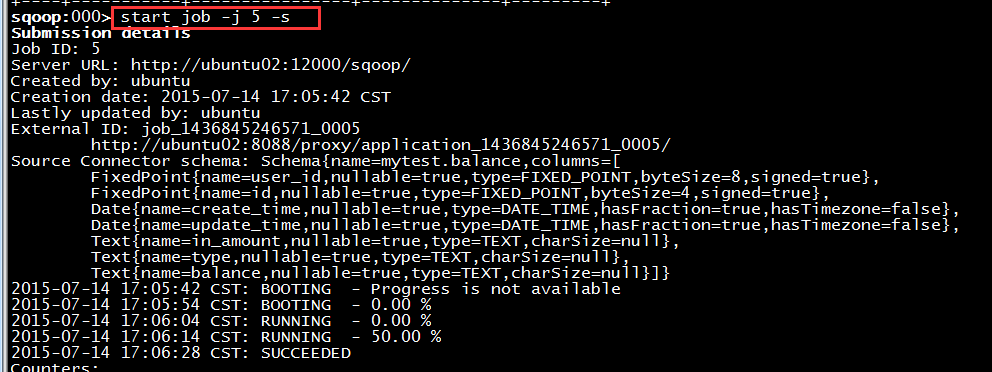
#这边-j后面的5代表上面创建的job的id,可以使用show job来查看已经创建的job sqoop:000> start job -j 5 -s
运行结果如下图:
确认数据是否已经导入
