tesseract-ocr识别英文和中文图片文字以及扫描图片实例讲解
tesseract-ocr识别英文和中文图片文字以及扫描图片实例讲解
本文参考http://blog.sina.com.cn/s/blog_4aa166780101cji7.html实现,在这里感谢该文章的作者。
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,后经由Google进行改进,消除bug,优化,重新发布。当前版本为3.02
项目下载地址为:http://jaist.dl.sourceforge.net/project/tesseract-ocr-alt/tesseract-ocr-setup-3.02.02.exe
Windows cmd命令行使用Tesseract-OCR引擎识别手机号码和图片中的文字:
1、下载安装Tesseract-OCR引擎(3.0版本+才支持中文识别)
tesseract-ocr-setup-3.02-02.exe.
下载完后进行安装,默认情况下安装程序会给你配置系统环境变量,以指向安装目录(之后可以通过DOS界面在任意目录运行tesseract)。安装完成后目录如下:

附录:
tessdata 目录存放的是语言字库文件,和在命令行界面中可能用到的参数所对应的文件. 这个安装程序默认包含了英文字库。
如果想能识别中文,可以到http://code.google.com/p/tesseract-ocr/downloads/list下载对应的语言的字库文件.一般google访问不了,请到这里下载即可,
简体中文字库文件下载地址为:http://download.csdn.net/detail/wanghui2008123/7621567下载完成后解压,然后将该文件剪切到tessdata目录下去就可以了。
2、使用Tessract-OCR引擎识别验证码
打开DOS界面,输入tesseract:

如果出现如上输出,表示安装正常。
命令格式:
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
识别数字:
我准备了一张验证码123.png 手机号码的图片,放在F:\IDOL\a|目录下

运行的命令行如下,我自己的命令行工具做了属性调整背景是白色的。

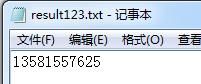
表示识别后生成一个result123.txt 打开文件如下:
识别中文:
我准备了一张验证码234.png "中国识别测试"个字的图片,放在F:\IDOL\a\目录下如图:

运行的命令行如下:
表示识别后生成一个result234.txt 打开文件如下:

识别中文和英文:
网上找了一张图片,有中文有英文的图片:

运行命令如下:

结果如下:中文识别还不是太好啊!

例如:
tesseract OCR.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract code.jpg图片是一行文本这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdata\configs 和 tessdata\tessconfigs 目录下的文件名.